How to plan and execute your ML and DL projects
This article gives the readers a checklist to structure their machine learning (applies to deep ones too) projects in effective ways.


“Cracking” practical machine learning projects require an incredibly disciplined way to get executed, despite all the successful SoTA achievements obtained in the last couple of years.
The way we approach a Kaggle competition, a Hackathon, an amateur data science task or even implementing a paper, it’s not the same that is expected in a professional working environment. There isn’t anything wrong in rapid prototyping, but you also have to know how to make the transition from monolithic machine learning code to a structured codebase that will not hurt the software engineers in the team. Later, this will also save you from a reproducibility crisis and your mental health. Unfortunately, there are not easy to follow along boilerplates for this. Luckily a suite of software engineering and machine learning best practices and guidelines come to help to improve our way to approach & succeed in this task.
This article is the first one in a series that will be dedicated to forming a path for channeling out deep learning projects in a holistic manner. We will start off by discussing the importance of having a good strategy to structure deep learning projects. We will then decompose the units that are responsible for developing a deep learning project at a production scale and study the first set of units.
Here are the article of this series:
- How to plan and execute your ML and DL projects (this article)
- Becoming One With Data
- Training Neural Nets: a Hacker’s Perspective
Why care about structuring a deep learning project?
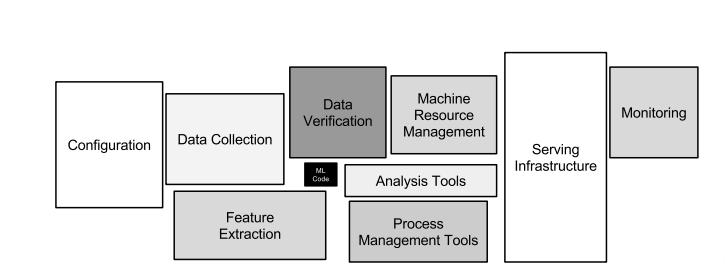
This is probably central to all the software development projects around the globe. You are most likely to work in a team when it comes to developing a software project at a production level. The team will consist of numerous members with varied responsibilities - some of them will be backend developers, some will be responsible for documentation while some will be responsible for unit testing. Things can get even worse if you are all alone - hired as a contractor to develop a PoC where you and only you are solely responsible for each and every little component of the PoC. The same theory applies to deep learning projects as well since at the end of the day we not only want to push the advancements in the field but also are interested in using deep learning to develop applications. When it comes to developing an application with deep learning at a decent scale it is nothing other than a software project.
Software engineering has been there since eternity. There already exists a general set of best practices which are domain agnostic (design patterns in software engineering) and then there are practices that are very domain specific, 12-factor app methodology, for example. Deep learning experiments are comprised of numerous modules even in their very nascent stage. For example dataset building, model building, model training, model tuning, model selection and so on. Now, think of the complexity that may arise when this gets scaled to a production environment. This is where the importance of software engineering comes into play.
Applied deep learning is an iterative process
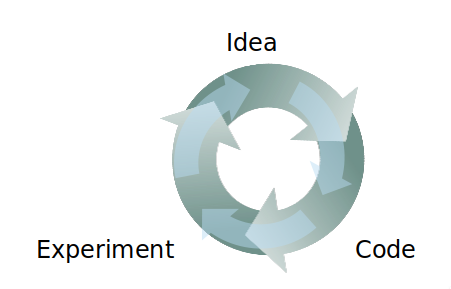
Performance of deep learning models can be improved in a lot of different ways. For example, you can collect more data if there is a dearth, you can train a network for a longer period of time, you can tune the hyperparameters of your deep learning model and so on. But when it comes to designing an entire system using deep learning, it is not uncommon to see these ideas getting failed. Even after improving the quality of the training data, your model might not work as expected may be the new training data is not well representative of the edge cases, may be there is still a significant amount of label noise in the training data; there can be many reasons literally. Now, this is perfectly fine but the amount of time put into collecting more data, labeling it, cleaning it gets wasted when this failure happens. We want this to be reduced as much as possible. Having a set of well-formed strategies will help here.
Reproducibility crisis
This is very central to deep learning because neural networks are stochastic in nature. This is one of the reasons why they are so good approximating functions. Because of this inherent stochasticity of neural networks, it is absolutely possible to get different results on the same experiment. For example today, you may get an accuracy of 90% on the Cats vs. Dogs dataset with a network architecture and the next day you observe a ± 1% change in the accuracy with the same architecture and experimentation pipeline. This is undesirable in production systems. We would want to have consistency in the results and would like the experiments as reproducible as possible.
Think of another scenario when you have conveyed your experiment results to your team. But when the other members are trying to reproduce your experiments for further development in the project, they are unable to do so. What is direr is even fixing the seeds of random number generators does not always guarantee reproducibility. There can be variations in the results due to dependency versions, environment settings, hardware configurations and so on. For example, you might have run all your experiments using TensorFlow 1.13 but the other members of the team are using the latest release (2.0.0-beta0). This can cause loads of problems unnecessarily in the execution of the experiments. In worst cases, the entire codebase can break for this dependency mismatch. Another example would be, say you have done all your experiments in GPU enabled environment without using any threading mechanism to load in the data. But this environment may not always be the same - your teammates may not have GPU enabled systems. As a result, they may get different results. So, apart from the fixation of the random seeds, it is important to maintain a fixed and consistent development environment across the team.
Versioning data and codebase separately
Software codebases are large and multi-variant. It is very likely that the software project you are working on will have multiple releases like most of the software do. So, quite naturally the codebases for these version changes also vary from each other and this gives birth to the need for version control. Versioning of codebases is probably way more important than one can imagine. Say, the latest version of your software is 2.0.1. after performing rigorous user feedback, it appears to you that a certain feature from one of the earlier versions of the software was better than the current one. If the developers' team does not maintain these different versions of codebases effectively, you will never be able to pull the changes easily in the current version of the software or rollback to the previously working release.
When it comes to deep learning, we not only have different codebases to version but also may have different versions of training data. You might have started your experiments with a training set containing several images and as the project progressed, you and your team decided to add more images to the training set. This is an example where data versioning is required. You are probably thinking why separately version the data? Can’t it be done along with the codebase?
This is very often overlooked in fact. You are most likely to change the software codebase more frequently than your data, if at all. When the software codebase is deployed to the production servers, then it would not make any sense to push your data along with the codebase if the data has not been changed. This point holds practical for any volumes of data that your project might deal with. You can read more about this here.
Regularity in checkpointing
You can save a considerable amount of time during your deep learning experiments if you set up model checkpointing correctly. Generally, model checkpointing refers to saving your network model during the training process. It can vary strategically. For example, one very common model checkpointing strategy is to record where the validation loss stops to decrease during the model training process along with the training loss and save the weights of the corresponding model. This is known as model checkpointing. As you keep prototyping through your deep learning experiments, you would be able to reuse these checkpointed models and this will definitely prevent you from having to repeat a training process(s) all over from scratch which might have taken hours/days.
The directory structure of a deep learning project
When you are working in a team or as a solo machine learning practitioner, it becomes important to put all the pieces of your deep learning experiments in a good structure so that it is as painless as possible for the other team members or stakeholders to refer to them. Consider the following examples -
- A web backend developer might need to load the model weights into his script to create a REST API endpoint
- Someone from the unit test team needs the model training script from your codebase in order to generate the particular test cases
In the above examples, if the fellow team members spend most of their time in finding the right files for the project development, then it affects the effectiveness in the project development. Maintaining a good directory structure can help a lot in preventing problems like these. Also, note that even if the Team agree on project structure, this is not a substitute for documenting the project repository/codebase.
The high-interest technical debt
As mentioned earlier, deep learning is a highly experimental field. There is always a plethora of possibilities and ideas one can try in their deep learning experiments. In fact, during the experimentation phase, we find ourselves exploring the realm of possibilities for the betterment of the performance. The more possibilities, the more the complexity, naturally. As the codebase progresses, it becomes difficult to keep track of the execution flow and remember which piece led to what. This gives birth to technical debt. This hurts the overall development of the project greatly since it is impractical to assume all the members in the project team would understand everything you tried in your experiments. However, if you document everything that you had tried in your experimentation phase in a proper manner, it becomes a lot easier to communicate across the team. Providing good documentation, adopting quality code refactoring practices are often seen as the traits of a not-so-cool developer since these things take time and considered to be boring. In a project environment, it is better to move slowly sometimes, so that the communication gap and slower experiment iteration cycles caused by technical debt can be reduced as much as possible.
In the next sections, we will be discussing the measure that we can take in order to check the above factors and thereby giving our deep learning projects a good structure. We will be simulating a pilot project scenario and will be building on top of that.
How to go about structuring deep learning projects?
To help ourselves develop solid know-how about structuring deep learning projects, it is practical to simulate a sample project scenario and proceed accordingly. For the sake of this article, imagine you are working for an e-Commerce company that focuses on fashion. The company aims to build an apparel classifier system to enhance its business processes. The end product will be a web application which will be able to take an image of apparel and produce its category as the output along with confidence score.
Your manager has given you the guidelines about the performance metrics that the company is interested in along with other details such as inference time, the maximum size of a deep learning model and so on. Now you are expected to execute with the rest of the team consisting of front-end developers, backend developers, data engineers and so on. The data engineers have collected some initial data with which you can start the experimentation process. But instead of directly spinning up a Jupyter Notebook, you decided to have a meeting with the rest of the team to agree on a suitable directory structure for the project. By now, you should already know why maintaining a directory structure for the project is important.
Assume that the infrastructure team has already set up the machines for the team to work on. If you are working alone, imagine you have set the infrastructure for yourself already. But, if you don't know how to do this or if you only want to focus on the science, here's FloydHub :)
A polished directory structure
At this point in time, if the team has a set of short-term goal of experiments that are going to be undertaken, it will be a lot easier to derive what directory structure might play out well. Ideally, at this stage, the team would -
- Have data as given by the data engineering team
- Have an experimentation notebook (or a set of notebooks) to introduce the dataset and initial modelling experiments
This is even more useful when the business value of the project is still unclear and you need to understand your, customer, data with more targeted questions.
As the project would progress, the team would develop more assets -
- Data (along with scripts to download it and preprocess it)
- Experimentations
- Web backend
- Utility scripts
- Model building and model training scripts
We will have to keep in mind that during this phase, there will be rapid prototyping involved. It is very likely that as a deep learning practitioner you will be trying out different network topologies, different loss functions, different training strategies and so on. There is no free lunch theorem in machine learning and this applies even more strongly in deep learning. So, to make sure you have a decent model trained with the available data, you are allowed to explore possibilities and ideas. This will result in some amount of technical debt. There will be a number of files residing in the project directory in an unordered fashion - duplicate & redundant codes, checkpoints & logs in anonymous folders and so on. In order to cope up with that, a relatively matured directory structure can be followed. This is inspired by this talk by Josh Tobin.
Data

In this case, the data engineers have already collected the data for the team to experiment with. The dataset is the FashionMNIST dataset. But there can be instances, you will be needed to write some functionality which would download the data from your company’s asset server according to the given specifications and will put in the directory as shown above. As discussed earlier, you would want to separate it from the rest of the codebase and version control it separately.
Experiments
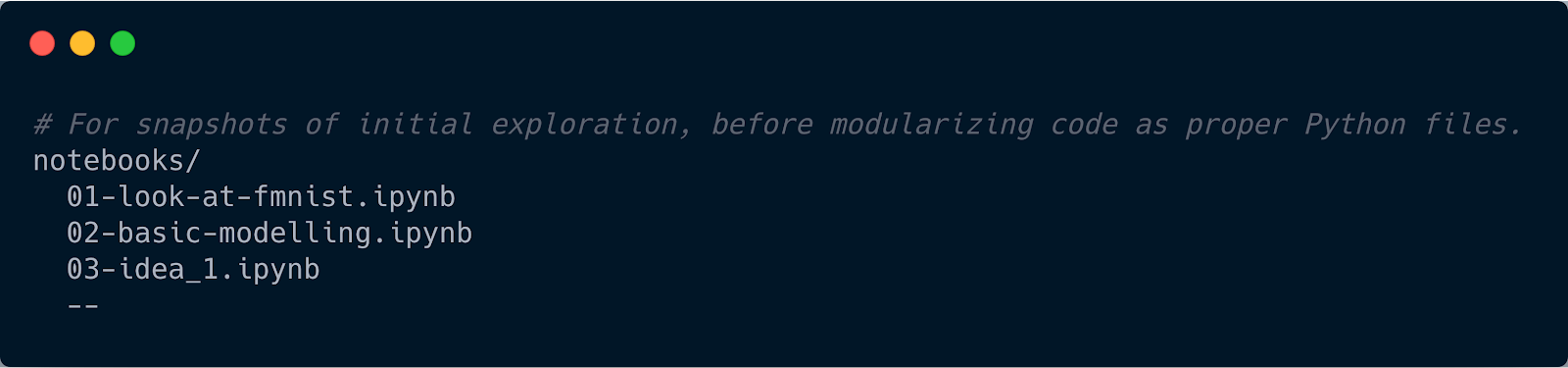
This is where you would put all the experiments performed during the initial phase. This can be an extensive study about the data, basic modelling experiments and so on. In machine learning specifically, the best way to communicate your findings to the rest of the team is via Jupyter Notebooks, hence the name directory name notebooks.
For web backend
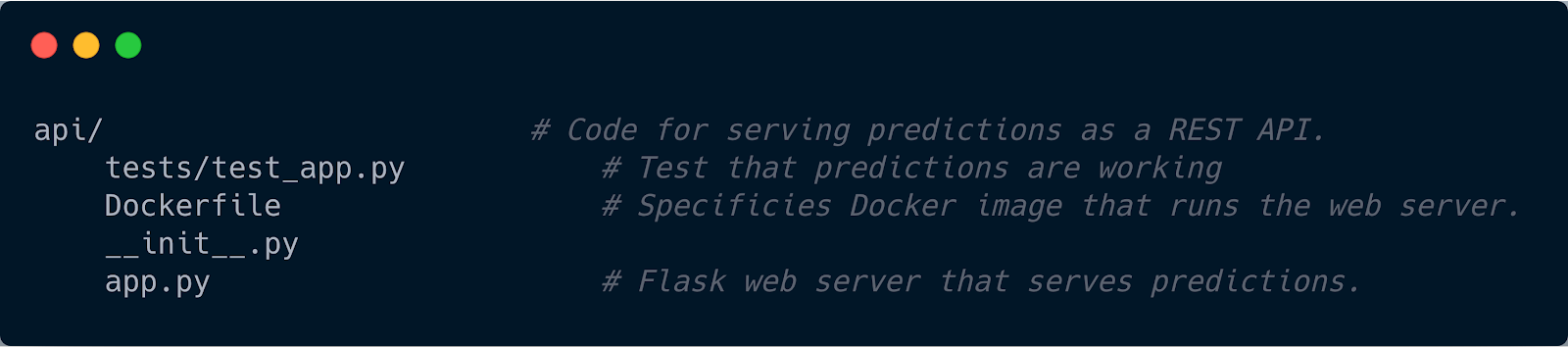
This is essentially for exposing the final model as a REST API endpoint. This is can contain basic tests as shown to test if the predictions are being made in the way they should be, the desired web server logic that wraps the model into an API endpoint. Along with these scripts, this is where all the specifications related to the Docker image of the development environment will reside. Docker is just an example I cited. It can be anything that helps to bundle software as containers. You will have a production server (like AppEngine, Lambda) to which the API will be deployed. The corresponding deployment scripts will also live in here in this directory.
For helper scripts
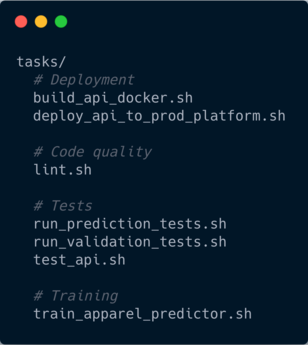
This is where all the convenient scripts for the project will go. This includes tests for checking code quality, tests for model’s predictions, deployment jobs, training jobs etc.
Model building and training
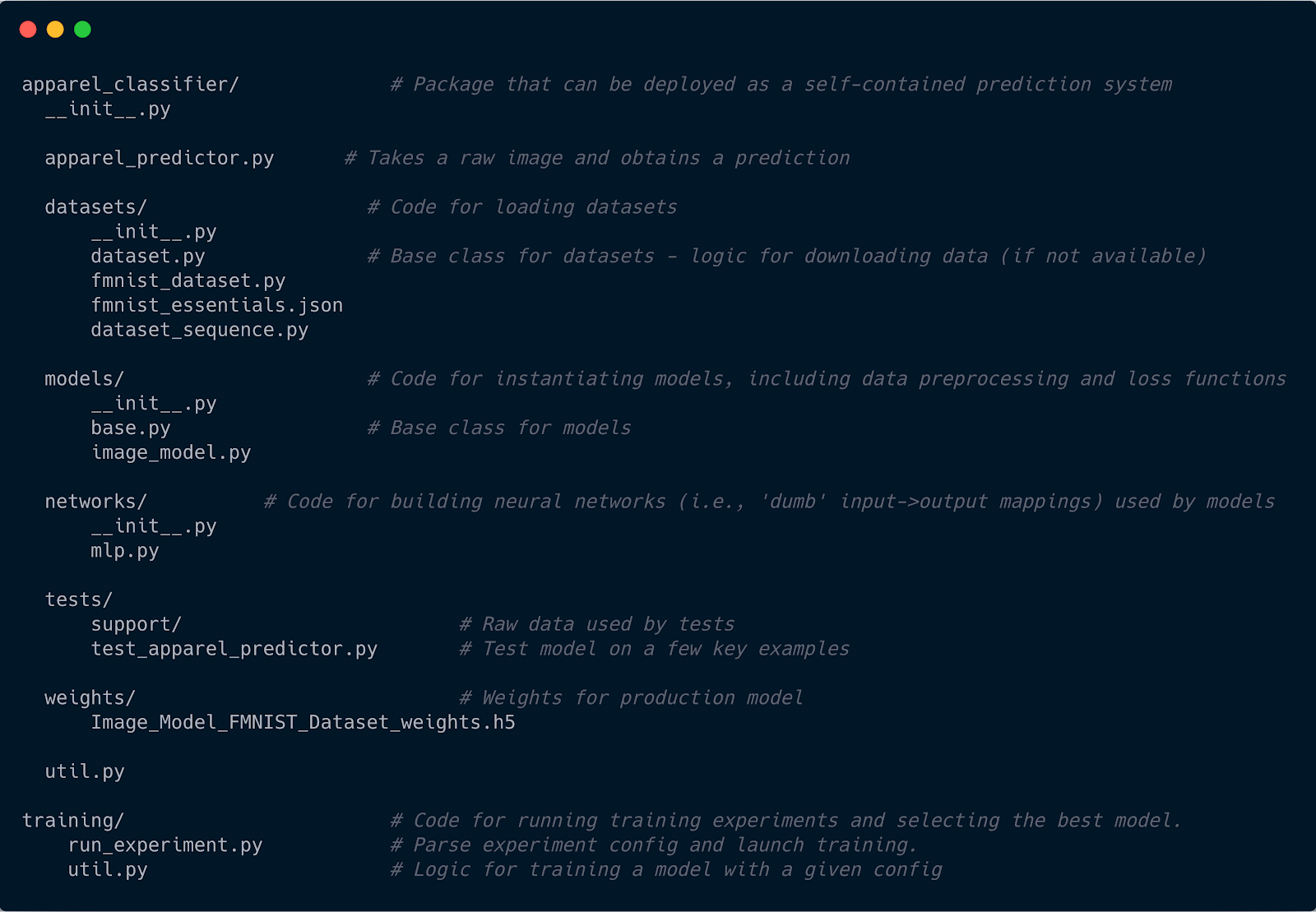
You can see there are two separate directories present in the structure - one that includes all the necessary pieces in order to build a model and another that actually train a model with respect to a set of model configurations. Note the distinction made between models and networks. This is because of a neural network is considered as dummy function here which just has the units but it does not know how to operate - how to load data, make a forward pass, produce a prediction and so on. The scripts residing in models are responsible for this.
Note that this is a reference structure and it can vary from team to team and projects to projects. Throughout this article and the upcoming articles, we will be building it.
After the team has agreed on a mutual directory structure, the next ideal step is to set up the development workspace - using the environment manager tools like pip and pipenv or Docker.
Workspace setup
We have discussed the importance of maintaining common development workspaces throughout the project in the earlier sections. We would not want to see the project getting broken due to dependency problems or dependency updates. Assuming the project is going to be based on Python as the central programming language, we can take advantage of tools like pip and pipenv to delegate the task of environment management. So, it will be worth discussing these tools to understand how they might be useful for this stage.
Use of environment management tools
The team members might already be having some dependencies already installed on their machines but they may differ in terms of versions. So, a good first step is to create a virtual environment or a container for the project and maintain that throughout the project. All the dependencies required for the project should reside in this environment/container.
There are a number of tools for doing this such as conda, pipenv, pip + virtualenv and so on. All of them are quite popular. In my experience, pipenv should be preferred over conda and pip + virtualenv. This is because sometimes it might so happen that a Python package (a dependency) has been released in Python Package Index (PyPI) but not has not been released as a conda package. In that case, you might have to build the package as a separate conda package by yourself.
Both conda and pipenv are able to create isolated Python environments but they differ in the ways using which they resolve dependencies. It is good to note that conda can install any conda package essentially and it may not always be a Python package. Explaining how pipenv and conda work is out of scope for this article but I recommend reading this article if anyone is interested.
Another solution that can be used while setting up workspaces is to use Docker. In the next section, we will see how.
Use of Docker

Docker enables you to develop, deploy and execute applications in a containerized environment. We can containerize our development environment in a stand-alone fashion within a Docker image. We can then distribute the Docker image as Docker containers. It is advantageous to use Docker since it provides the ability to package the whole development environment as a container which can be run on other machines. It can be particularly useful if we were to ship our project as containers to other parties.
Both of the above-discussed options are fine and are widely used in the industry but what if we could use an even simpler option?
Use of FloydHub to ease the environment management process.
FloydHub makes it quite easy to maintain consistency in environments. FloydHub's environments come with many common deep learning and machine learning packages and dependencies pre-installed. Examples of pre-installed packages include numpy, scipy, OpenCV, OpenAI Gym, SpaCy, etc. Along with this, FloydHub provides with a workspace with respect to a given environment. This workspace is fully configured Python environment wherein you can easily run your Python scripts, fire up Jupyter Notebooks and so on. Here is a list of some environments that are provided by FloydHub currently:
TensorFlow1.13PyTorch1.0MxNet1.0
If you need additional or custom packages, you can install them before running a FloydHub job.
We are now ready to proceed towards taking a step forward which is specific to the execution of the deep learning experiments.
Building a mental image of the execution flow
Deep learning experiments contain a series of different steps from data preparation to modelling. Each step builds on top of the other. There can be some steps which are collectively iterative. For example - building a model, then training it, tuning its hyperparameters, evaluating it and the experiments then again go back to the model building step.
It is often the case that for trying out different model architectures, we would preprocess the data differently to make it suitable for streaming to the respective models. Imagine that you are starting your deep learning experiment with a pre-trained VGG16 network to classify a set of images into categories. To make the data suitable for the pre-trained network, you normalized it using the statistics (mean and standard deviation) of the dataset on which the network was trained on. However, you did not get a satisfactory result with this network and you decided to try another pre-trained network - an Inception network this time trained on the CIFAR10 dataset. But before feeding your original data to the Inception network you forgot to normalize it with the statistics of CIFAR10 dataset. This can indeed lead to unexpected consequences and in the momentum, you may not be able to figure out why.
That is why it is important to prepare a mental model of the overall execution flow of the experiments even before starting to execute them. You can always refer to it and cross-check if something in your experiments is going wrong unexpectedly. Below is an example of such a mental model which was built by the FloydHub team during one of their internal Hackathon projects.
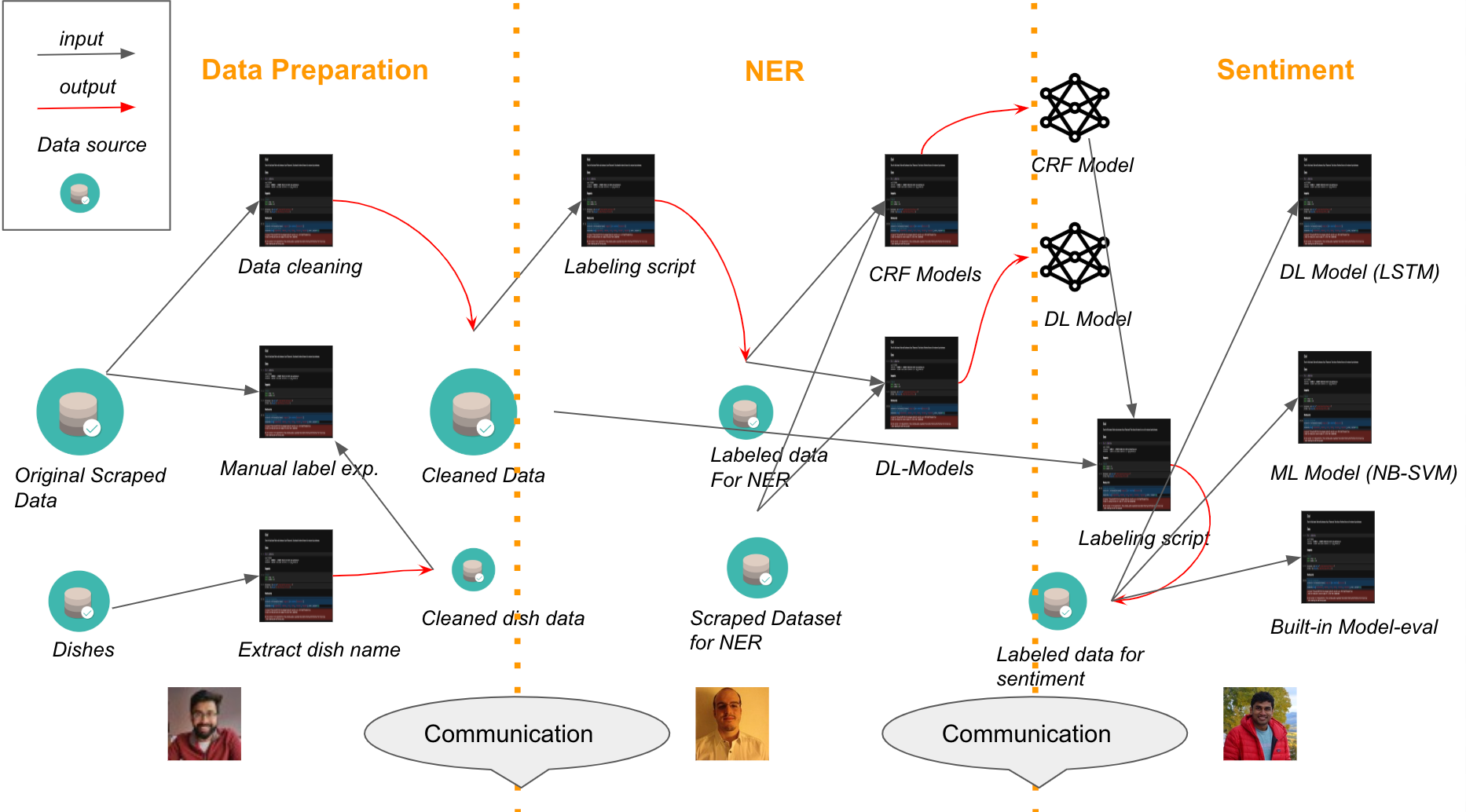
Observe how well curated this model is. It elegantly briefs out the steps that the team would perform while doing their experiments. It has carefully enlisted the operations and then these operations are segregated in phase wise fashion. The operations have been made interconnected so that the team can keep a track of the execution flow.
The final pointer to consider regarding the project structure is versioning of data and the codebase which we will be discussing next.
Version controlling
Version control of data is still not as well-established as that of a codebase. We have shed some light on why it is important to separate the data from the codebase. With time, data for training deep learning systems can often change. Consider the following scenarios -
- The team may want to replace the older images with newer ones
- The team may want to add new images to an already existing training set
- The team has decided to incorporate active learning to select interesting test data points to manually label them and add to the existing training set.
There can be many instances you would want to version control the data. Although version controlling the data is still an active research field FloydHub is solving this problem in a very simple way. Just like GitHub, BitBucket and so on, FloydHub provides ways to easily create and upload datasets via its CLI. You have the flexibility to either create a dataset from the files residing locally in your machine or you can create a dataset from the internet as well. But this is just the tip of salt. Be sure to check the documentation here if you are looking for ways to version control your data.
We now have a soft guide on how to go about structuring a deep learning project. These have been immensely helpful in my experience and I sincerely hope they will be in your cases as well. We iterated quite a lot about deep learning experiments. But it is important to know that there are some fundamental works that are needed to be done before digging into them.
Data is what fuels machine learning systems. So becoming one with the data is just important and I cannot really over-emphasize this enough. In the next section, we will be diving deep towards this subject. We will try to formulate a checklist that can easily be referenced in your own works too.
What's next?
In this article, we covered the points that should be taken into consideration to properly structure a deep learning project. But the journey does not end here. In the next article, we will be resuming just where we are leaving today. We will be studying some general guidelines that should be followed before the deep learning experiments begin to take place. This would include topics like becoming one with the data, data transformations, exploratory data analysis, human baselines and more.
Jump to the next article, now!
A huge shoutout to Alessio of FloydHub for sharing his valuable feedback during each of writing this article. It truly helped me enhance the quality of the article’s content. I think this article is equally Alessio's too :)
FloydHub Call for AI writers
Want to write amazing articles like Sayak and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Sayak Paul
Sayak loves everything deep learning. He goes by the motto of understanding complex things and helping people understand them as easily as possible. Sayak is an extensive blogger and all of his blogs can be found here. He is also working with his friends on the application of deep learning in Phonocardiogram classification. Sayak is also a FloydHub AI Writer. He is always open to discussing novel ideas and taking them forward to implementations. You can connect with Sayak on LinkedIn and Twitter.