Becoming One With the Data
This article discusses effective ways of handling the data in machine learning projects.


This article serves as the successor to the article How to plan and execute your ML and DL projects. It focuses on data-specific aspects of our experiments that are typically carried out before we set out for the modeling part. The motivation comes from the following statement made by Andrej Karpathy in his blog A Recipe for Training Neural Networks:
The first step to training a neural net is to not touch any neural net code at all and instead begin by thoroughly inspecting your data.
We will specifically be focusing on the following aspects:
- Becoming one with data , which deals with the reasons why familiarizing yourself with the data is necessary if you want your modeling to be successful
- Data transformation , which shares meaningful ways to transform the raw dataset
- Exploratory Data Analysis , aka EDA, which takes you through the steps of deriving insights from the data
- Human baselines , which can be used to craft meaningful questions regarding the modeling process, as well as the data collection process
Becoming One With the Data

In the preceding article we discussed that a data exploration notebook (or a set of notebooks) proves extremely useful when the business value of the project is still unclear and you need to understand your customer data with more targeted questions. We will start this section with this as motivation.
Here are the most common pointers for this process, which I hope will collectively convey the importance of this step.
- To be able to understand the data, a good understanding of domain knowledge is required. What makes certain instances truly interesting from the rest? What is the importance of a feature with respect to the problem statement you are dealing with? You will be able to answer questions like these if you have sound domain knowledge. Additionally, it will help you to develop a solid business understanding of the data, and make better sense of the features present.
- If the dataset is not balanced enough, special measures will need to be taken. This is very popularly known as the class imbalance problem, wherein you do not have a sufficient number of data points for a particular class(es) with respect to the other class(es). It is impractical to expect good performance from a network if it has not seen a sufficient number of examples belonging to a particular class. Furthermore, the class imbalance problem has a direct relationship with the kind of evaluation metric you would care for.
- If the dataset consists of duplicate records with different labels, there is no point keeping a sample in your dataset with the wrong label. This would do nothing other than confuse our model.
- Is there any label noise in the dataset? Often times, it is found that a set of instances in the dataset is categorized incorrectly. This can absolutely fail your network when it is deployed in production. We will revisit this topic later in the article.
- Is there any data leakage in the dataset? Data leakage can take many forms. For example, any feature in the dataset that may not be available during the inference time is a potential source of data leakage. Consider that you want to predict the individuals who will contract swine-flu. A few rows in the dataset looks like:
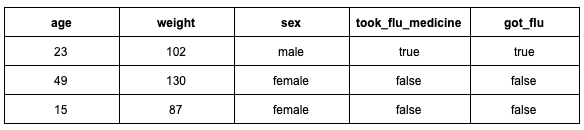
It’s common to take medicine while being infected by the flu to recover. This is why took_flu_medicine and got_flu features are very strongly correlated. But the value took_flu_medicine can change after the target variable, i.e. got_flu, is determined. This is an example of target leakage.
Naturally, the models built with this data are likely to learn that anyone that did not take a flu medicine did not get infected by the flu, which is inaccurate. If you happen to split the training data into partial training and validation set, you are likely to have a well-performing model on the validation data as well. On deployment, however, the model will fail terribly since it was not trained to capture a good relationship between the data points and the labels.
In order to prevent situations like this, it is always good to exclude features which can be updated after the labels have been learned by the model.
This was an example of leaky predictors. There is another type of leakage which is introduced during data preprocessing steps. We will discuss it in a separate section in this article.
- Are the examples in the dataset confusing to distinguish? The subtle variations and finer local granularities in images can cause confusion when recognizing the classes of certain images.
To understand the above two points more thoroughly, consider the problem of identifying age from a person’s front-facing image.
Here is an example which presents three images of different persons along with a network’s prediction with the actual labels (in prediction/actual/loss/probability format).

The person on the left is actually middle-aged; the image is not labeled correctly. But from what the network had learned, it appears that its prediction is right. By contrast, the person in the center is actually middle-aged, but because of the color variations the network received from other images of the dataset, it predicted the person to be young. The rightmost person is young, but again is labeled incorrectly.
- Are the data points relevant to the given problem? It is common to see data points that are not representative of the problem you are dealing with. Consider the above problem again. The task is to detect the age of individuals from their front-facing images. You would not want images of toys, dogs, airplanes in the dataset, just as you would not want images of this quality:

Try to map this point with the idea of irrelevance. If we were having a class on the basis of differentiation, for example, we would not want lessons on how to solve a quadratic equation in that same class.
- Is there any bias in the dataset? There can be many forms of biases in the dataset, and during this step a fair amount of time should be given to find out if the data suffers from any kind of bias. Consider the age detection problem again. While exploring the images in the dataset, you discovered that there are instances where the people in the images have been given a label of Old just because the images were grayscale (we saw this example). Not only is this an example of label noise, but these instances can also reveal an inductive bias that may be present in the dataset.
If you inspect the dataset with the above points in your mind, you will at least be able to cross-check your data to figure out if something is off that is causing your network to fail. These observations allow for follow up with the data engineering and labeling teams to look for scopes of improvements in the data sampling process, including labeling and data collection processes.
Keep in mind that the whole idea of data understanding is very iterative in nature. Sometimes the deep learning model you are using can reveal additional information regarding the data which was missed in the initial data exploration.
Data Transformations
The data you get from the data engineering team is often raw, without any transformations applied to it. The problem with that is raw data is not suitable for any of the steps you would take further, be it exploratory data analysis or modeling. You will see a lot of issues in the raw dataset which should now be addressed. It would make sense to discuss some of these issues before we jump into discussing the transformations.
- Missing values
- Typing
- Difference in value ranges in features
- Encoding
- Data distribution and outliers
- Handling missing values
- Scaling and normalization
- Representation of categorical variables
- Handling inconsistent data entries
- Fighting data leakage
- Fighting data imbalance
Missing values
This is probably both the most naive and most complex issue you will see in a raw dataset. Naive because missing values may be easy to spot depending on how they are indicated. Complex because it might so happen that you will not be able to figure out the missing values in the first place. If they go unnoticed, this will definitely lead you (and the company) to suffering. Python data analysis libraries like pandas provide you with several utilities to figure out missing values in a dataset easily, but only when the missing values conform to the rules that are defined in the libraries.
Consider this toy example of the Pima Indians Diabetes dataset. The dataset is known to have missing values but if you do not go deeper in your analysis you will not be able to figure out which features of the dataset have missing values. Here’s a preview of the dataset -

The dataset contains health records of 768 individuals. If you extract the summary statistics of the dataset you will be able to see that there are erroneous zero values in a number of features. The following features in the dataset have invalid zero entries:
- Glucose
- BloodPressure
- SkinThickness
- Insulin
- BMI
There can be many instances like this in the raw dataset which are nothing but missing values. Missing values are not suitable for effective modeling as they can greatly hamper the predictive power of a model. Dealing with missing values is another ball game altogether, and we will return to that later in this section.
Typing
This issue is very often seen in tabular datasets - the issue of inconsistent datatypes. You will often find that the datatypes of the features in the dataset are not in the format they should be. For example, the date features are often interpreted as native string objects (in Python it is just ‘object’), the integer features are represented as float or double, and so on. What problems can arise from this?
Consider a sales dataset about certain customers which has a number of date features, two very important ones being purchase_date and last_visit_date. You have loaded the dataset in your working environment but the date features have been interpreted as plain non-numeric objects by the library you are using. Now suppose you want to find the maximum amount of sales that happened during a particular period in a quarter. You will not able to query the dataset effectively for this if the date features have not been parsed properly. All the data analysis libraries provide you with a number of useful functions to deal with date and time. To be able to use them on the respective features of your dataset, the features must be in their suitable formats.
Consider another situation: the numeric features have been recorded as non-numeric ones in the dataset itself, or where there is an issue with the precision (half-precision values represented as full precision). This is not at all desirable. Just to give you an example, in a recent Kaggle competition, namely, Microsoft Malware Prediction, the dataset that was provided was large enough to fit into the memory of a commodity computer. There were 81 features in the dataset and I struggled to get the data loaded in the memory to progress. The fundamental problem was in the datatypes of the features - they were inconsistent. The immediate solution to this problem was to specify the best possible datatypes of the features (incorporating domain knowledge). This not only sped up the data loading process but also resulted in much lower memory consumption.
It is likely that you will face these types of issues as well. Chances are good that you will have a separate data engineering team to help you with this issue, but if that is not the case, you will have to find ways to help yourself.
Difference in value ranges in features
When you have varying ranges among the features in the dataset, a small change in one feature may not affect the other one. This is undesirable for many machine learning models such as neural networks.
To understand this, consider a dataset of house pricing where you have two features: number_of_rooms and price_of_the_house(USD). These two features will not have values of the same range. If they are not scaled to a uniform range of values, the model (non-tree-based) will consider a difference in the room number as important as a difference of 1 USD in price_of_the_house. This is not how you would want to model the relationship between the two features.
Enconding
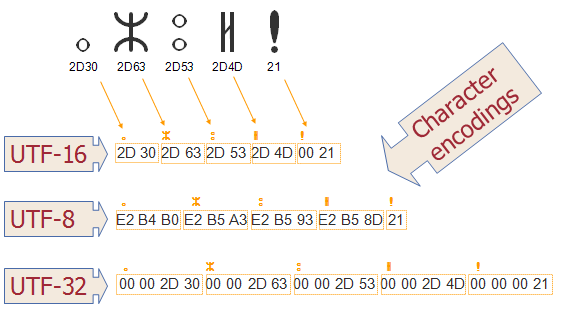
Data is serialized in raw binary bytes when it resides in computers. Character encodings provide a mapping to convert these raw bytes to human-readable characters. The most popular encoding you will encounter is UTF-8.
If you try to load in a dataset using an encoding that does not know how to map some of the characters to raw binary bytes, you will run into errors. The default encoding that is followed by most of the libraries is UTF-8. There may be situations where you would specify the encoding of the dataset explicitly to the library you are using, of course, if the encoding is known to you. A good way to determine the encoding of a file in Python is to use the chardet module, although it may not be 100% perfect all the time.
This a topic that every programmer (and data scientist) absolutely and positively needs to know!
Data distribution and outliers
You are likely to run into deep trouble if the distribution of the training data is different from that of the data that the model would see during inference. Consider if you have deployed a model that was trained on low-resolution images and then, during inference, the model is streamed with much higher-resolution images. In this situation, the model is most likely to perform poorly.
There can be outliers present in the raw dataset also. At a high level, outliers are those data points that deviate largely from most of the data points in the dataset. If you do not deal with the outliers carefully, the predictive performance of your model can be highly flawed. For a more comprehensive introduction to the topic of outliers in data, readers are encouraged to check this article.
We discussed the most staggering issues in the raw datasets that lead us to apply various transformations. Rather than discussing specific techniques, in the following subsections we will be focusing on the aspects that we should care about the most while applying transformations to the data.
Handling missing values

To be able to effectively deal with missing values, it is vital to understand why the data is missing. To figure that out, you would want to understand how the data was collected - if your data engineering team is responsible for that you would want to check with them. If you are using an already existing dataset, you would want to check the documentation to really get a good sense of what the features mean in the dataset. Once you develop a good interpretation of the features, you would investigate the reasons for which the data may have gone missing, of which there can be several.
Was the data not recorded? Sometimes, it might so happen that the device/system responsible for capturing the data has an issue which keeps the respective data from being captured. On the other hand, there can be certain features that may not apply for all the data points in a dataset.
Suppose that you are dealing with sensor data and you encountered a decent amount of missing values coming from a particular sensor category. This can most likely happen because of the sensor’s failure. In these situations, the best bet for you would be to try to ignore those missing values. Now, consider there is a feature called is_married in a dataset of credit card applications and 10% of the values for this feature is missing. In this case, it would make more sense if you do not guess if an individual is married or not and probably drop the instances where the is_married feature is missing.
This is how a good understanding of the features, with the right amount of domain knowledge, is essential to decision-making in this step.
Scaling and normalization

Scaling and normalization are essentially two different things. It is common to see them being used interchangeably, though.
- Scaling deals with changing the range of values from one scale to another, 3000 - 5000 to 100 - 200, for example.
- Normalization is the process of transforming a set of values so that they follow a normal distribution. This is often done because many parametric models like neural networks assume that your data is drawn from a normal distribution.
A few points to consider in this step -
- Be careful at applying scaling and normalization on the features that do not require it. You would not want to scale and normalize features that are categorical in nature.
- Also, make sure that while constructing the training and validation splits you scale and normalize the validation using the statistics from the training set only. There should not be any governance on these factors from the holdout validation set or even the test set.
- While using a pre-trained model (trained on ImageNet) on your custom image dataset, you should be normalizing the dataset with the ImageNet statistics only.
Representation of categorical variables

There can be a lot of non-numeric categorical features in your dataset. You would transform them into numeric ones to make them suitable for feeding to your models. Be careful about how you are numerically representing the categorical features. There is usually a good trade-off between a label encoded and a one-hot encoded representation of categorical features.
Label encoding typically assigns an integer to each of the unique categories in a feature. This introduces a certain order in the features which can negatively influence the predictive power of your model. On the other hand, one-hot encoding turns the categories into one-hot vectors. If there are a lot of categories present in a feature, one-hot encoding can introduce a huge amount of sparsity which can be challenging to a model.
This is why there is no fixed rule of thumb on how you represent the categorical features. You should decide this after thorough experimentation and after also considering the available resources.
Handling inconsistent data entries
If the dataset that you are dealing with comes from human entries or some kind of survey, chances are good that you will see many variants of the same value. Consider that your organization is conducting a public survey for getting feedback on one of its products. In the survey form, there is a field called department. Individuals that are working in information technology departments (or any other department) can enter either I.T. or Information Technology or IT. There can be many variants like this if there is no pre-filter being applied to this respective field.
You will have to clean this kind of inconsistent entry before moving to your data analyses. This will also give you an opportunity to take this to the data collection team so that they can enhance the collection process.
Fighting data leakage
As Dan Becker of Kaggle specifies it -
Data leakage can be multi-million dollar mistake in many data science applications.
Data leakage is not a trivial problem. There really is no single remedy to this problem like most of the other problems with machine learning in general. But a good first step to fight this problem starts with careful construction of training and validation sets.
Say you are building an image segmentation model and the dataset consists of several frames snapped out of videos. It might not be a good idea to create a partial validation set with random splits, since you may end up having an image(s) in the validation set which is contiguous to another image in the train set. It will be very easy for the model to do the segmentation on the image from the validation set. In this case, a good validation set would contain images that are non-contiguous in nature with the images in the train set. There is this really interesting article on how to create a good validation set which I highly recommend for reading.
Also, identifying the leaky predictors (as discussed earlier) would definitely help you minimize data leakage as much as possible.
Fighting data imbalance
Imagine you are dealing with a dataset containing loan applications. The task is to predict if a loan application would get accepted or not. You built a model which gave you 96% accuracy and were ready to report this to your manager, but it did not go well. Why?
Well, in this case the dataset was known to be imbalanced, where the ratio between the approved application and unapproved application was 96:4. You only presented how accurate the model was without showing how accurate the model would be when predicting the minority class (the unapproved applications). After running the model again, you came to know that the model is not able to predict the minority class at all. This is a situation where you would want to consider metrics other than just plain classification accuracy.
Exploratory Data Analysis
By now you should have the data ready with necessary transformations (maybe a few left off). Now is a good time to put on your investigator hat again and to run an exploratory analysis on the data, aka EDA. This is not only for understanding interesting trends in the data, but also for communicating the results of the EDA with the rest of the team. It will help the team to remain well-informed about the data, which is really crucial for any machine learning team project.
EDA helps with a number of things:
- Discovering interesting patterns from the data
- Understanding how well the data represents the problem at hand
- Identification of outliers that may be present in the data
I am going to take the Fashion MNIST dataset to better walk through the steps that I often follow when I start doing EDA. Another reason for going with this dataset is it loosely resembles the problem statement that we had discussed in the initial section. The dataset is available for download from the specified link as zipped files. The local repository structure should resemble the following -

You can follow this project to execute the code snippets alongside reading the article.

I will be using the EDA_FashionMNIST notebook throughout this section. First, we will have to load the data into the working environment, which in this case is Jupyter Notebook. Luckily the data is small enough to be read in-memory. The following helper function can load in the dataset and return the images and the labels as numpy arrays. Note that the dataset comes with standard train and test sets.
# Function to load in the FashionMNIST dataset
def load_mnist(path, kind='train'):
labels_path = os.path.join(path,
'%s-labels-idx1-ubyte.gz'
% kind)
images_path = os.path.join(path,
'%s-images-idx3-ubyte.gz'
% kind)
with gzip.open(labels_path, 'rb') as lbpath:
labels = np.frombuffer(lbpath.read(), dtype=np.uint8,
offset=8)
with gzip.open(images_path, 'rb') as imgpath:
images = np.frombuffer(imgpath.read(), dtype=np.uint8,
offset=16).reshape(len(labels), 784)
return images, labels
The function takes two arguments:
- Path where the data is residing
- Kind of dataset- whether it is the train set or test set
Load the data by running -
# Train set
X_train, y_train = load_mnist('/floyd/home/data', kind='train')
# Test set
X_test, y_test = load_mnist('/floyd/home/data', kind='test')
In a later article in this series, we will use FloydHub dataset to make the version control of the data seamless.
Each image is a grayscale image having a 28x28 dimension. The images were flattened during the loading process and we can confirm this by calling the shape attribute on X_train and X_test - X_train.shape, X_test.shape
This will return - ((60000, 784), (10000, 784)) which means that there is a total of 60000 images in the train set and 10000 images in the test set. The second dimension, i.e. 784 (28*28), in both X_train and X_test suggests the flattening step. The y_train and y_test variables contain the integer encoded labels of the images. Their shapes are (60000,) and (10000,) respectively. But what do the images look like? After loading in the data and inspecting its shape, this is the first question I generally find the answer to. It is a matter of the following lines of code:
# Shows the first images along with its label
plt.imshow(X_train[0].reshape(28,28), cmap=plt.cm.binary)
plt.show()
print('Class label {}'.format(y_train[0]))
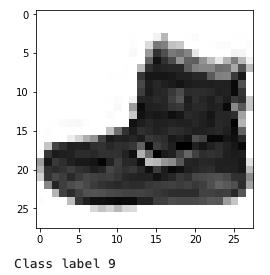
You can easily turn the above lines of code into a handy function, but I will leave that to you. Before proceeding further, let’s look at the mapping of the encoded labels as specified on the homepage of the dataset.

The label of the image we just saw refers to an ankle boot. Instead of running the above lines of code a few times, I would write another helper function that would create a montage of a few images along with their labels. I would run this function a couple of times to see the data myself and get a better sense of it, and develop my own understanding of how the image labels have been annotated.
# Helper function to generate
# a montage of a random batch of 25 images from the training set
def show_25_images(X, y):
plt.figure(figsize=(10,10))
for i,ii in enumerate(np.random.randint(low=1, high=X.shape[0]+1, size=25)):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(True)
plt.imshow(X[ii].reshape(28,28), cmap=plt.cm.binary)
plt.xlabel(CLASS_NAMES[y[ii]])
plt.show()
Running show_25_images(X_train, y_train) would produce -

As mentioned above, I would typically run this function a few times on the dataset to look for any uneven patterns, to understand their labels and to try classifying the images based on my own understanding. This is really a good time to spot anything uncanny in the data, which includes label noise, signal noise and so on. During this process, I was able to find some amount of label noise in the data.
There are certainly some inconsistencies/label noises in the labels of pullovers, coats and shirts. For example, consider the following chunk:

Look at the variation in the shapes of these items. It can be difficult for us to distinguish these images properly. In these situations, your model is bound to get confused if it has not been instructed well. Note that I tend not to look at the test set (if it is available separately) from these aspects as that should not influence the model training. You could also write a function that generates a random set of images per category. And then you could run the function a couple of times to spot any abnormality.
We should have a basic understanding of the images by now. How about the labels? How are they distributed across the two sets?
This little function can find answers to these questions -
# Function to calculate the distribution of the classes
def class_dist(y):
return pd.DataFrame(Counter(y).most_common(), columns=['Class', 'Observations'])
For train set, it should yield -

The figure indeed tells us that there is no class imbalance in the train set, but in real life this is not always the case. I like to project the image data on a 2D plane to understand the underlying distribution visually. Later in the experimentation process, I would also do the same for the test set to figure out if both the distributions are similar to each other. If they are not, we will have to take this into consideration while training and improving the model.
To plot the image data-points on a 2D plane I will first have to reduce their dimensionality. t-SNE or t-distributed stochastic neighbor embedding is a widely known technique that lets you view high dimensional data points on lower-dimensional space. I am going to use sklearn’s built-in TSNE module for this.
Before proceeding further, I will scale the pixel values in the images to 0-1 because t-SNE is a compute-intensive technique. So, a lower range of value will definitely help - X_train = X_train/255.
Now the t-SNE part. t-SNE is quite time consuming, so running t-SNE on the entire train set of 60000 data-points would take very long even on a GPU-enabled platform since sklearn does not utilize GPU. This is why I am going to use the first 5000 data-points from X_train.
# t-SNE on the train set
fashion_tsne = TSNE(random_state=666).fit_transform(X_train[:5000])
Next, another utility is needed to visualize the points returned by t-NSE. I am going to use an already existing implementation from this article. Here’s how the function looks -
# Helper function to visualize the points returned by t-SNE
def fashion_scatter(x, colors):
# Choose a color palette with seaborn.
num_classes = len(np.unique(colors))
palette = np.array(sns.color_palette("hls", num_classes))
# Create a scatter plot.
f = plt.figure(figsize=(8, 8))
ax = plt.subplot(aspect='equal')
sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40, c=palette[colors.astype(np.int)])
plt.xlim(-25, 25)
plt.ylim(-25, 25)
ax.axis('off')
ax.axis('tight')
# Add the labels for each digit corresponding to the label
txts = []
for i in range(num_classes):
# Position of each label at median of data points.
xtext, ytext = np.median(x[colors == i, :], axis=0)
txt = ax.text(xtext, ytext, str(i), fontsize=24)
txt.set_path_effects([
PathEffects.Stroke(linewidth=5, foreground="w"),
PathEffects.Normal()])
txts.append(txt)
plt.show()
Now if the function is called with fashion_scatter(fashion_tsne, y_train[:5000]), it should return you the following plot -

As you can see, the categories have formed groups in between them. This also hints to you about possible noise in the dataset, i.e. the points in the figure that do not belong in their respective groups.
With this, we can safely conclude the first round of EDA. One final step I would do before proceeding to the modeling experiments is take 100 images randomly without their labels and label them manually. During the modeling process, I would first create a model with this small subset of data and see how far off the predictions are. If they are not close, there is something off in the process and it needs to be inspected.
Human Baselines
Human annotation or human labeling is the process of manually labeling your data. This might sound trivial if you are unaware of it, but it has a tremendous amount of significance in the industry. As an example, I will refer to the following image taken from Andrej Karpathy’s talk here -

As you can see, there is a clear disconnect between academia and the industry when it comes to coupling together your data and modeling processes. The process of human labeling has numerous advantages -
- If you and your team are not sure how to label the data, the authority of labeling remains with the team. This is often propagated to a team of domain experts who are specifically hired for the task of labeling - yes, separate time for data labeling.
- For object detection problems where you have to localize an object or set of objects and bind them with boxes, human labeling is a must. Check this article if you want to know more about the process specifically for object detection. It shows how to use the labelImg tool for the process (and more).
- You would want to do this before starting the modeling experiments, since your models are essentially the representations of the data that you fed to them. Based on these learned representations, the models distinguish between the categories if it is a supervised learning problem. Before you have your models learn these representations, it would make sense if you give the supervision process a try and see how accurate you are. If you are not accurate enough, then why? Are you getting confused while making the distinction between the categories? If you can find answers to these questions before the modeling experiments, you will be much better off. You will keep your sanity if your model performs poorly, as well as have points to look for figuring out why it is happening.
- During this process, you will be able to decide if the dataset truly representative of the problem you are trying to solve. Let’s say that the team is working on building self-driving cars, and that you are responsible for making the cars understand how to classify between the objects it would see. Well, the first question you should be asking is about the environment where the self-driving cars would be deployed. Will the environment be crowded and be situated in a plane region? If this is the case, it would not make sense to train the cars on the images collected from lesser crowded mountain regions. We will return to this point in a separate section in the article.
I feel these points really make the human labeling process super important. Of course, there are other aspects if you are considering active learning, but I will skip them for now.
If you are considering manual labeling, labelImg is really a good tool. Data labeling is also a good alternative and is offered by the Google Cloud Platform. Since the dataset we are using is simple enough, I am not going to use any of these tools. Instead, I will take the first 100 images from the train set and I will maintain an array to store my class predictions.
For the labeling process, I will create another notebook in the notebooks directory.
First, let’s load up the first 100 images in batches of 25. I will also be reusing some of the function I had written in the EDA notebook. The first batch of images looks like the following -
Note: We are able to do this only because of adequate domain knowledge (or because it's easy to get). There are tasks where you need a pool of experts in order to set a good human baseline (e.g. ct-scan segmentation, etc...). Or that requires months or years in order to get a good understanding of the data you need to manage.

I will be following the string labels and will convert them to the integer encodings later when that is needed. After I finish the first batch of labeling, it would be an array looking like (order: left to right and row by row)-
batch_1 = ['Ankle boot', 'T-shirt/top', 'T-shirt/top', 'Dress', 'Tshirt/top',
'Pullover', 'Sneaker', 'Pullover', 'Sandal', 'Sandal'
'T-shirt/top', 'Ankle boot', 'Sandal', 'Sandal', 'Sneaker',
'Ankle boot', 'Trouser', 'Tshirt/top', 'Pullover', 'Pullover',
'Dress', 'Trouser', 'Pullover', 'Bag', 'Pullover']
Here are the next batches of images and their corresponding labels (predicted by me).

batch_2 = ['Coat', 'Pullover', 'Pullover', 'Pullover', 'Pullover',
'Sandal', 'Dress', 'Shirt', 'Shirt', 'T-shirt/top',
'Bag', 'Sandal', 'Pullover', 'Trouser', 'Shirt',
'Shirt', 'Sneaker', 'Ankle boot', 'Sandal', 'Ankle boot',
'Pullover', 'Sneaker', 'Dress', 'T-shirt/top', 'Dress']

batch_3 = ['Dress', 'Dress', 'Sneaker', 'Pullover', 'Pullover',
'T-shirt/top', 'Shirt', 'Bag', 'Dress', 'Dress',
'Sandal', 'T-shirt/top', 'Sandal', 'Sandal', 'T-shirt/top',
'Pullover', 'T-shirt/top', 'T-shirt/top', 'Coat', 'Trouser',
'T-shirt/top', 'Trouser', 'Shirt', 'Dress', 'Trouser']

batch_4 = ['Coat', 'Shirt', 'T-shirt/top', 'Trouser', 'Ankle boot',
'Trouser', 'Dress', 'Sandal', 'Sneaker', 'Ankle boot',
'Sneaker', 'Trouser', 'Sneaker', 'Ankle boot', 'Sneaker',
'Sneaker', 'T-shirt/top', 'Pullover', 'Sneaker', 'Dress',
'Shirt', 'Coat', 'Trouser', 'Trouser', 'Bag']
There seems to be some kind of ordering present in the predictions as made by me. If you look closely, there are some samples from respective classes residing beside one another. During the modeling process, we will have to make sure that the models do not learn about anything regarding order because that may cause their predictions to be biased. In this case, you would want the models to learn only about the contents in the images. So, to keep this in check, you would shuffle the images in the train set before feeding them to the models. Be careful here though. I have seen many people shuffling the images and labels in the wrong way - they shuffled the images but forgot the shuffle the labels in the same order. This can be disastrous.
After spending some 20-30 minutes manually labeling, I calculated the accuracy score with the original labels and it was exactly 84%. This seems to be low and indeed suggests a few possibilities -
- My mental process of classifying the apparels is maybe flawed and I am not able to capture the variations from the images fully.
- There is some amount of noise in the labels.
We will leave this section for now. The main takeaway from this section should be this method of getting important pointers about the data from the manual labeling process. For example, if you know that your own way of data classification is flawed beforehand, you will be able to use this going forward by consulting with a domain expert and iterating on the process.
Iterating with data engineering and labeling teams on the sampling process

This is going to be the final section of the article where we will focus on the data collection process itself. This part essentially appears quite a few times in the whole pipeline, but we will only consider the sections that typically come after you have completed an initial round of EDA or trained your first models. You would sit with the data engineering and the data labeling team to enhance the overall quality of the data. Examples include:
- It is very unlikely in a real project situation that you will have data which adequately represents the problem you are dealing with. To understand this, take the example of building self-driving cars again. Suppose you are labeling lanes in the images of roads to train the cars for lane detection. Most of the data labelings are like so -

During the first round of road-testing, the cars get the following lanes.

(This example is taken from this talk by Andrej Karpathy.)
This is an example where the training data is not versatile enough to capture conundrums of the real world. In reality, you can never be certain about the versatility of the data in the first place. So, in these situations, after a round of testing, you would include instances in the training data that are rare but possible during inference. You would also investigate a few unlabeled instances which are interesting in their patterns and then have the labeling team label those instances. This is referred to as active learning, which is an active field of research.
- There will be label noises in data and they make the models highly confused and flawed. (Refer to the example discussed in the Becoming One With the Data section). In this situation, you would need to convey this to the respective teams.
- A barebone truth about real-world data is that it is never clean. To understand the impact of this, consider the scenario discussed in the following talk. In order to build a speech recognition model, we would need annotated voice recordings- preferably human voice recordings. In reality, the text of the real-world voice recordings may not always be easily comprehensible. The word kdkdkd is a textual representation of a train’s running sound, for example. The talk discusses several cases like this and other nuances of building machine learning systems with unclean data.
- If more data is needed to better aid the models, you will need to discuss with the data engineering team whether to collect the data or to generate it. This depends on a wide range of things like the project budget and the possibility of collecting the data, since getting ahold of real data is not always possible, among other considerations. Even if you are considering data augmentation or other means to generate data, there will still be a set of changes in the data pipeline which depend on the infrastructure you have. This can be resource intensive, especially if you are using Python as the central programming language. It can even introduce a bottleneck in your data input pipeline.
The central idea you should take from this section is that data collection and data labeling are highly non-trivial tasks. Clearly enough, a considerable amount of effort is needed in these processes.
Conclusion
We finally come to an end today. With this article, I aimed to give you some sense of what structuring a deep learning project looks like. By now, you should be convinced that a generous amount of human involvement is needed in all the steps we discussed in the article- not everything can be automated 🙂
Well, that is good news, but what’s next?
In the next article of this series I will share ways to effectively avoid the pain associated with training a neural network, as well as discuss ways to troubleshoot deep neural networks (inspired from this article). But today, I will leave you with some links that helped me write this article, and hopefully they will help you too if you are really serious about being structured about your deep learning projects.
- Building the Software 2 0 Stack (Andrej Karpathy) where Andrej discusses a very important point regarding building today’s deep learning applications and their difficulties.
- FullStack Deep Learning, a full-fledged course on shipping deep learning models developed by Pieter Abbeel, Sergey Karayev and Josh Tobin.
- Structuring Machine Learning Projects, a course offered by Coursera and taught by Andrew Ng which takes you through a wide range of best practices for properly structuring machine learning projects.
- Advanced Machine Learning with TensorFlow on Google Cloud Platform, a course offered by Coursera which takes you through many complex production pipelines that are followed by Google for their machine learning systems.
- Tesla Autonomy Day where Andrej Karpathy shows how his team trains the neural networks for giving the visual recognition power to the self-driving cars at Tesla.
- Your dataset is a giant inkblot test by Cassie Kozyrkov, where she discusses the psychological trap in data analytics. The article meticulously takes you through the misconceptions that a data analyst could form from the data.
A huge shoutout to Alessio from FloydHub for sharing his valuable feedback during each of writing this article. It truly helped me enhance the quality of the article’s content. I think this article is equally Alessio's too :)
FloydHub Call for AI writers
Want to write amazing articles like Sayak and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Sayak Paul
Sayak loves everything deep learning. He goes by the motto of understanding complex things and help people understand them as easily as possible. Sayak is an extensive blogger and all of his blogs can be found here. He is also working with his friends on the application of deep learning in Phonocardiogram classification. Sayak is also a FloydHub AI Writer. He is always open to discussing novel ideas and taking them forward to implementations. You can connect with Sayak on LinkedIn and Twitter.