Introduction to Anomaly Detection in Python
Learn what anomalies are and several approaches to detect them along with a case study.


There are always some students in a classroom who either outperform the other students or failed to even pass with a bare minimum when it comes to securing marks in subjects. Most of the times, the marks of the students are generally normally distributed apart from the ones just mentioned. These marks can be termed as extreme highs and extreme lows respectively. In Statistics and other related areas like Machine Learning, these values are referred to as Anomalies or Outliers.
The very basic idea of anomalies is really centered around two values - extremely high values and extremely low values. Then why are they given importance? In this article, we will try to investigate questions like this. We will see how they are created/generated, why they are important to consider while developing machine learning models, how they can be detected. We will also do a small case study in Python to even solidify our understanding of anomalies. But before we get started let’s take some concrete example to understand how anomalies look like in the real world.
A dive into the wild: Anomalies in the real world
Suppose, you are a credit card holder and on an unfortunate day it got stolen. Payment Processor Companies (like PayPal) do keep a track of your usage pattern so as to notify in case of any dramatic change in the usage pattern. The patterns include transaction amounts, the location of transactions and so on. If a credit card is stolen, it is very likely that the transactions may vary largely from the usual ones. This is where (among many other instances) the companies use the concepts of anomalies to detect the unusual transactions that may take place after the credit card theft. But don’t let that confuse anomalies with noise. Noise and anomalies are not the same. So, how noise looks like in the real world?
Let’s take the example of the sales record of a grocery shop. People tend to buy a lot of groceries at the start of a month and as the month progresses the grocery shop owner starts to see a vivid decrease in the sales. Then he starts to give discounts on a number of grocery items and also does not fail to advertise about the scheme. This discount scheme might cause an uneven increase in sales but are they normal? They, sure, are not. These are noises (more specifically stochastic noises).
By now, we have a good idea of how anomalies look like in a real-world setting. Let’s now describe anomalies in data in a bit more formal way.
Find the odd ones out: Anomalies in data
Allow me to quote the following from classic book Data Mining. Concepts and Techniques by Han et al. -
Outlier detection (also known as anomaly detection) is the process of finding data objects with behaviors that are very different from expectation. Such objects are called outliers or anomalies.
Could not get any better, right? To be able to make more sense of anomalies, it is important to understand what makes an anomaly different from noise.
The way data is generated has a huge role to play in this. For the normal instances of a dataset, it is more likely that they were generated from the same process but in case of the outliers, it is often the case that they were generated from a different process(s).

In the above figure, I show you what it is like to be outliers within a set of closely related data-points. The closeness is governed by the process that generated the data points. From this, it can be inferred that the process for generated those two encircled data-points must have been different from that one that generated the other ones. But how do we justify that those red data points were generated by some other process? Assumptions!
While doing anomaly analysis, it is a common practice to make several assumptions on the normal instances of the data and then distinguish the ones that violate these assumptions. More on these assumptions later!
The above figure may give you a notion that anomaly analysis and cluster analysis may be the same things. They are very closely related indeed, but they are not the same! They vary in terms of their purposes. While cluster analysis lets you group similar data points, anomaly analysis lets you figure out the odd ones among a set of data points.
We saw how data generation plays a crucial role in anomaly detection. So, it will be worth enough to discuss what might lead towards the creation of anomalies in data.
Generation of anomalies in data
The way anomalies are generated hugely varies from domain to domain, application to application. Let’s take a moment to review some of the fields where anomaly detection is extremely vital -
- Intrusion detection systems - In the field of computer science, unusual network traffic, abnormal user actions are common forms of intrusions. These intrusions are capable enough to breach many confidential aspects of an organization. Detection of these intrusions is a form of anomaly detection.
- Fraud detection in transactions - One of the most prominent use cases of anomaly detection. Nowadays, it is common to hear about events where one’s credit card number and related information get compromised. This can, in turn, lead to abnormal behavior in the usage pattern of the credit cards. Therefore, to effectively detect these frauds, anomaly detection techniques are employed.
- Electronic sensor events - Electronic sensors enable us to capture data from various sources. Nowadays, our mobile devices are also powered with various sensors like light sensors, accelerometer, proximity sensors, ultrasonic sensors and so on. Sensor data analysis has a lot of interesting applications. But what happens when the sensors become ineffective? This shows up in the data they capture. When a sensor becomes dysfunctional, it fails to capture the data in the correct way and thereby produces anomalies. Sometimes, there can be abnormal changes in the data sources as well. For example, one’s pulse rate may get abnormally high due to several conditions and this leads to anomalies. This point is also very crucial considering today’s industrial scenario. We are approaching and embracing Industry 4.0 in which IoT (Internet of Things) and AI (Artificial Intelligence) are integral parts. When there is IoT, there are sensors. In fact a wide network of sensors, catering to an arsenal of real-world problems. When these sensors start to behave inconsistently the signals they convey get also uncanny, thereby causing unprecedented troubleshooting. Hence, systematic anomaly detection is a must here.
and more.
In all of the above-mentioned applications, the general idea of normal and abnormal data-points is similar. Abnormal ones are those which deviate hugely from the normal ones. These deviations are based on the assumptions that are taken while associating the data points to normal group. But then again, there are more twists to it i.e. the types of the anomalies.
It is now safe enough to say that data generation and data capturing processes are directly related to anomalies in the data and it varies from application to application.
Anomalies can be of different types
In the data science literature, anomalies can be of the three types as follows. Understanding these types can significantly affect the way of dealing with anomalies.
- Global
- Contextual
- Collective
In the following subsections, we are to take a closer look at each of the above and discuss their key aspects like their importance, grounds where they should be paid importance to.
Global anomalies
Global anomalies are the most common type of anomalies and correspond to those data points which deviate largely from the rest of the data points. The figure used in the “Find the odd ones out: Anomalies in data” section actually depicts global anomalies.

A key challenge in detecting global anomalies is to figure out the exact amount of deviation which leads to a potential anomaly. In fact, this is an active field of research. Follow this excellent paper by Macha et al. for more on this. Global anomalies are quite often used in the transnational auditing systems to detect fraud transactions. In this case, specifically, global anomalies are those transactions which violate the general regulations.
You might be thinking that the idea of global anomalies (deviation from the normal) may not always hold practical with respect to numerous conditions, context and similar aspects. Yes, you are thinking just right. Anomalies can be contextual too!
Contextual anomalies
Consider today’s temperature to be 32 degrees centigrade and we are in Kolkata, a city situated in India. Is the temperature normal today? This is a highly relative question and demands for more information to be concluded with an answer. Information about the season, location etc. are needed for us to jump to give any response to the question - “Is the temperature normal today?”
Now, in India, specifically in Kolkata, if it is Summer, the temperature mentioned above is fine. But if it is Winter, we need to investigate further. Let’s take another example. We all are aware of the tremendous climate change i.e. causing the Global Warming. The latest results are with us also. From the archives of The Washington Post:
Alaska just finished one of its most unusually warm Marches ever recorded. In its northern reaches, the March warmth was unprecedented.
Take note of the phrase “unusually warm”. It refers to 59-degrees Fahrenheit. But this may not be unusually warm for other countries. This unusual warmth is an anomaly here.
These are called contextual anomalies where the deviation that leads to the anomaly depends on contextual information. These contexts are governed by contextual attributes and behavioral attributes. In this example, location is a contextual attribute and temperature is a behavioral attribute.

The above figure depicts a time-series data over a particular period of time. The plot was further smoothed by kernel density estimation to present the boundary of the trend. The values have not fallen outside the normal global bounds, but there are indeed abnormal points (highlighted in orange) when compared to the seasonality.
While dealing with contextual anomalies, one major aspect is to examine the anomalies in various contexts. Contexts are almost always very domain specific. This is why in most of the applications that deal with contextual anomalies, domain experts are consulted to formalize these contexts.
Collective anomalies
In the following figure, the data points marked in green have collectively formed a region which substantially deviates from the rest of the data points.

This an example of a collective anomaly. The main idea behind collective anomalies is that the data points included in forming the collection may not be anomalies when considered individually. Let’s take the example of a daily supply chain in a textile firm. Delayed shipments are very common in industries like this. But on a given day, if there are numerous shipment delays on orders then it might need further investigation. The delayed shipments do not contribute to this individually but a collective summary is taken into account when analyzing situations like this.
Collective anomalies are interesting because here you do not only to look at individual data points but also analyze their behavior in a collective fashion.
So far, we have introduced ourselves to the basics of anomalies, its types and other aspects like how anomalies are generated in specific domains. Let’s now try to relate to anomalies from a machine learning specific context. Let’s find out answers to general questions like - why anomalies are important to pay attention to while developing a machine learning model and so on.
Machine learning & anomalies: Could it get any better?
The heart and soul of any machine learning model is the data that is being fed to it. Data can be of any form practically - structured, semi-structured and unstructured. Let’s go into these categories for now. At all their cores, machine learning models try to find the underlying patterns of the data that best represent them. These patterns are generally learned as mathematical functions and these patterns are used for making predictions, making inferences and so on. To this end, consider the following toy dataset:
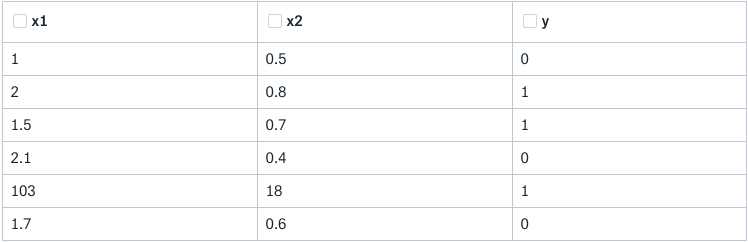
The dataset has two features: x1 and x2 and the predictor variable (or the label) is y. The dataset has got 6 observations. Upon taking a close look at the data points, the fifth data point appears to be the odd one out here. Really? Well, it depends on a few things -
- We need to take the domain into the account here. The domain to which the dataset belongs to. This is particularly important because until and unless we have information on that, we cannot really say if the fifth data point is an extreme one (anomaly). It might so happen that this set of values is possible in the domain.
- While the data was getting captured, what was the state of the capturing process? Was it functioning in the way it is expected to? We may not always have answers to questions like these. But they are worth considering because this can change the whole course of the anomaly detection process.
Now coming to the perspective of a machine learning model, let’s formalize the problem statement -
Given a set of input vectors x1 and x2 the task is to predict y.
The prediction task is a classification task. Say, you have trained a model M on this data and you got a classification accuracy of 96% on this dataset. Great start for a baseline model, isn’t it? You may not be able to come up with a better model than this for this dataset. Is this evaluation just enough? Well, the answer is no! Let’s now find out why.
When we know that our dataset consists of a weird data-point, just going by the classification accuracy is not correct. Classification accuracy refers to the percentage of the correct predictions made by the model. So, before jumping into a conclusion of the model’s predictive supremacy, we should check if the model is able to correctly classify the weird data-point. Although the importance of anomaly detection varies from application to application, still it is a good practice to take this part into account. So, long story made short, when a dataset contains anomalies, it may not always be justified to just go with the classification accuracy of a model as the evaluation criteria.
The illusion, that gets created by the classification accuracy score in situations described above, is also known as classification paradox.
So, when a machine learning model is learning the patterns of the data given to it, it may have a critical time figuring out these anomalies and may give unexpected results. A very trivial and naive way to tackle this is just dropping off the anomalies from the data before feeding it to a model. But what happens when in an application, detection of the anomalies (we have seen the examples of these applications in the earlier sections) is extremely important? Can’t the anomalies be utilized in a more systematic modeling process? Well, the next section deals with that.
Getting benefits from anomalies
When training machine learning models for applications where anomaly detection is extremely important, we need to thoroughly investigate if the models are being able to effectively and consistently identify the anomalies. A good idea of utilizing the anomalies that may be present in the data is to train a model with the anomalies themselves so that the model becomes robust to the anomaly detection. So, on a very high level, the task becomes training a machine learning model to specifically identify anomalies and later the model can be incorporated in a broader pipeline of automation.
A well-known method to train a machine learning model for this purpose is Cost-Sensitive Learning. The idea here is to associate a certain cost whenever a model identifies an anomaly. Traditional machine learning models do not penalize or reward the wrong or correct predictions that they make. Let’s take the example of a fraudulent transaction detection system. To give you a brief description of the objective of the model - to identify the fraudulent transactions effectively and consistently. This is essentially a binary classification task. Now, let’s see what happens when a model makes a wrong prediction about a given transaction. The model can go wrong in the following cases -
- Either misclassify the legitimate transactions as the fraudulent ones
or
- Misclassify the fraudulent ones as the legitimate ones

To be able to understand this more clearly, we need to take the cost (that is incurred by the authorities) associated with the misclassifications into the account. If a legitimate transaction is categorized as fraudulent, the user generally contacts the bank to figure out what went wrong and in most of the cases, the respective authority and the user come to a mutual agreement. In this case, the administrative cost of handling the matter is most likely to be negligible. Now, consider the other scenario - “Misclassify the fraudulent ones as the legitimate ones.” This can indeed lead to some serious concerns. Consider, your credit card has got stolen and the thief purchased (let’s assume he somehow got to know about the security pins as well) something worth an amount (which is unusual according to your credit limit). Further, consider, this transaction did not raise any alarm to the respective credit card agency. In this case, the amount (that got debited because of the theft) may have to be reimbursed by the agency.
In traditional machine learning models, the optimization process generally happens just by minimizing the cost for the wrong predictions as made by the models. So, when cost-sensitive learning is incorporated to help prevent this potential issue, we associate a hypothetical cost when a model identifies an anomaly correctly. The model then tries to minimize the net cost (as incurred by the agency in this case) instead of the misclassification cost.
(N.B.: All machine learning models try to optimize a cost function to better their performance.)
Effectiveness and consistency are very important in this regard because sometimes a model may be randomly correct in the identification of an anomaly. We need to make sure that the model performs consistently well on the identification of the anomalies.
Let’s take these pieces of understandings together and approach the idea of anomaly detection in a programmatic way.
A case study of anomaly detection in Python
We will start off just by looking at the dataset from a visual perspective and see if we can find the anomalies. You can follow the accompanying Jupyter Notebook of this case study here.

Let's first create a dummy dataset for ourselves. The dataset will contain just two columns:
- Name of the employees of an organization
- Salaries of those employees (in USD) within a range of 1000 to 2500 (Monthly)
For generating the names (and make them look like the real ones) we will use a Python library called Faker (read the documentation here). For generating salaries, we will use the good old numpy. After generating these, we will merge them in a pandas DataFrame. We are going to generate records for 100 employees. Let's begin.
Note: Synthesizing dummy datasets for experimental purposes is indeed an essential skill.
# Import the necessary packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Comment out the following line if you are using Jupyter Notebook
# %matplotlib inline
# Use a predefined style set
plt.style.use('ggplot')
# Import Faker
from faker import Faker
fake = Faker()
# To ensure the results are reproducible
fake.seed(4321)
names_list = []
fake = Faker()
for _ in range(100):
names_list.append(fake.name())
# To ensure the results are reproducible
np.random.seed(7)
salaries = []
for _ in range(100):
salary = np.random.randint(1000,2500)
salaries.append(salary)
# Create pandas DataFrame
salary_df = pd.DataFrame(
{'Person': names_list,
'Salary (in USD)': salaries
})
# Print a subsection of the DataFrame
print(salary_df.head())
Let's now manually change the salary entries of two individuals. In reality, this can actually happen for a number of reasons such as the data recording software may have got corrupted at the time of recording the respective data.
salary_df.at[16, 'Salary (in USD)'] = 23
salary_df.at[65, 'Salary (in USD)'] = 17
# Verify if the salaries were changed
print(salary_df.loc[16])
print(salary_df.loc[65])
We now have a dataset to proceed with. We will start off our experiments just by looking at the dataset from a visual perspective and see if we can find the anomalies.
Seeing is believing: Detecting anomalies just by seeing
Hint: Boxplots are great!
As mentioned in the earlier sections, the generation of anomalies within data directly depends on the generation of the data points itself. To simulate this, our approach is good enough to proceed. Let's now some basic statistics (like minimum value, maximum value, 1st quartile values etc.) in the form of a boxplot.
Boxplot, because we get the following information all in just one place that too visually:

# Generate a Boxplot
salary_df['Salary (in USD)'].plot(kind='box')
plt.show()We get:

Notice the tiny circle point in the bottom. You instantly get a feeling of something wrong in there as it deviates hugely from the rest of the data. Now, you decide to look at the data from another visual perspective i.e. in terms of histograms.
How about histograms?
# Generate a Histogram plot
salary_df['Salary (in USD)'].plot(kind='hist')
plt.show()The result is this plot:

In the above histogram plot also, we can see there's one particular bin that is just not right as it deviates hugely from the rest of the data (phrase repeated intentionally to put emphasis on the deviation part). We can also infer that there are only two employees for which the salaries seem to be distorted (look at the y-axis).
So what might be an immediate way to confirm that the dataset contains anomalies? Let's take a look at the minimum and maximum values of the column Salary (in USD).
# Minimum and maximum salaries
print('Minimum salary ' + str(salary_df['Salary (in USD)'].min()))
print('Maximum salary ' + str(salary_df['Salary (in USD)'].max()))We get:
Minimum salary 17
Maximum salary 2498Look at the minimum value. From the accounts department of this hypothetical organization, you got to know that the minimum salary of an employee there is $1000. But you found out something different. Hence, its worth enough to conclude that this is indeed an anomaly. Let's now try to look at the data from a different perspective other than just simply plotting it.
Note: Although our dataset contains only one feature (i.e. Salary (in USD)) that contains anomalies in reality, there can be a lot of features which will have anomalies in them. Even there also, these little visualizations will help you a lot.
Clustering based approach for anomaly detection
We have seen how clustering and anomaly detection are closely related but they serve different purposes. But clustering can be used for anomaly detection. In this approach, we start by grouping the similar kind of objects. Mathematically, this similarity is measured by distance measurement functions like Euclidean distance, Manhattan distance and so on. Euclidean distance is a very popular choice when choosing in between several distance measurement functions. Let's take a look at what Euclidean distance is all about.
An extremely short note on Euclidean distance
If there are n points on a two-dimensional space(refer the following figure) and their coordinates are denoted by(x_i, y_i), then the Euclidean distance between any two points((x1, y1) and(x2, y2)) on this space is given by:


We are going to use K-Means clustering which will help us cluster the data points (salary values in our case). The implementation that we are going to be using for KMeans uses Euclidean distance internally. Let's get started.
# Convert the salary values to a numpy array
salary_raw = salary_df['Salary (in USD)'].values
# For compatibility with the SciPy implementation
salary_raw = salary_raw.reshape(-1, 1)
salary_raw = salary_raw.astype('float64')We will now import the kmeans module from scipy.cluster.vq. SciPy stands for Scientific Python and provides a variety of convenient utilities for performing scientific experiments. Follow its documentation here. We will then apply kmeans to salary_raw.
# Import kmeans from SciPy
from scipy.cluster.vq import kmeans
# Specify the data and the number of clusters to kmeans()
centroids, avg_distance = kmeans(salary_raw, 4)
In the above chunk of code, we fed the salary data points the kmeans(). We also specified the number of clusters to which we want to group the data points. centroids are the centroids generated by kmeans() and avg_distance is the averaged Euclidean distance between the data points fed and the centroids generated by kmeans().Let's assign the groups of the data points by calling the vq() method. It takes -
- The data points
- The centroid as generated by the clustering algorithm (kmeans() in our case)
It then returns the groups (clusters) of the data points and the distances between the data points and its nearest groups.
# Get the groups (clusters) and distances
groups, cdist = cluster.vq.vq(salary_raw, centroids)Let's now plot the groups we have got.
plt.scatter(salary_raw, np.arange(0,100), c=groups)
plt.xlabel('Salaries in (USD)')
plt.ylabel('Indices')
plt.show()The resultant plot looks like:

Can you point to the anomalies? I bet you can! So a few things to consider before you fit the data to a machine learning model:
- Investigate the data thoroughly - take a look at each of the features that the dataset contains and pay close attention to their summary statistics like mean, median.
- Sometimes, it is easy for the eyes to generate a number of useful plots of the different features of the dataset (as shown in the above). Because with the plots in front of you, you instantly get to know about the presence of the weird values which may need further investigation.
- See how the features are correlated to one another. This will in turn help you to select the most significant features from the dataset and to discard the redundant ones. More on feature correlations here.
The above method for anomaly detection is purely unsupervised in nature. If we had the class-labels of the data points, we could have easily converted this to a supervised learning problem, specifically a classification problem. Shall we extend this? Well, why not?
Anomaly detection as a classification problem
To be able to treat the task of anomaly detection as a classification task, we need a labeled dataset. Let's give our existing dataset some labels.
We will first assign all the entries to the class of 0 and then we will manually edit the labels for those two anomalies. We will keep these class labels in a column named class. The label for the anomalies will be 1 (and for the normal entries the labels will be 0).
# First assign all the instances to
salary_df['class'] = 0
# Manually edit the labels for the anomalies
salary_df.at[16, 'class'] = 1
salary_df.at[65, 'class'] = 1
# Veirfy
print(salary_df.loc[16])Let's take a look at the dataset again!
salary_df.head()
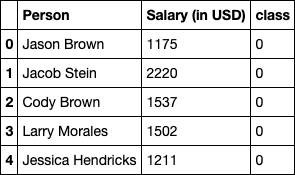
We now have a binary classification task. We are going to use proximity-based anomaly detection for solving this task. The basic idea here is that the proximity of an anomaly data point to its nearest neighboring data points largely deviates from the proximity of the data point to most of the other data points in the data set. Don't worry if this does not ring a bell now. Once, we visualize this, it will be clear.
We are going to use the k-NN classification method for this. Also, we are going to use a Python library called PyOD which is specifically developed for anomaly detection purposes.
I really encourage you to take a look at the official documentation of PyOD here.
# Importing KNN module from PyOD
from pyod.models.knn import KNNThe column Person is not at all useful for the model as it is nothing but a kind of identifier. Let's prepare the training data accordingly.
# Segregate the salary values and the class labels
X = salary_df['Salary (in USD)'].values.reshape(-1,1)
y = salary_df['class'].values
# Train kNN detector
clf = KNN(contamination=0.02, n_neighbors=5)
clf.fit(X)Let's discuss the two parameters we passed into KNN() -
- contamination - the amount of anomalies in the data (in percentage) which for our case is 2/100 = 0.02
- n_neighbors - number of neighbors to consider for measuring the proximity
Let's now get the prediction labels on the training data and then get the outlier scores of the training data. The outlier scores of the training data. The higher the scores are, the more abnormal. This indicates the overall abnormality in the data. These handy features make PyOD a great utility for anomaly detection related tasks.
# Get the prediction labels of the training data
y_train_pred = clf.labels_
# Outlier scores
y_train_scores = clf.decision_scores_
Let's now try to evaluate KNN() with respect to the training data. PyOD provides a handy function for this - evaluate_print().
# Import the utility function for model evaluation
from pyod.utils import evaluate_print
# Evaluate on the training data
evaluate_print('KNN', y, y_train_scores)We get:
KNN ROC:1.0, precision @ rank n:1.0
We see that the KNN() model was able to perform exceptionally good on the training data. It provides three metrics and their scores -
Note: While detecting anomalies, we almost always consider ROC and Precision as it gives a much better idea about the model's performance. We have also seen its significance in the earlier sections.
We don't have any test data. But we can generate a sample salary value, right?
# A salary of $37 (an anomaly right?)
X_test = np.array([[37.]])Let's now test how if the model could detect this salary value as an anomaly or not.
# Check what the model predicts on the given test data point
clf.predict(X_test)The output should be: array([1])
We can see the model predicts just right. Let's also see how the model does on a normal data point.
# A salary of $1256
X_test_abnormal = np.array([[1256.]])
# Predict
clf.predict(X_test_abnormal)
And the output: array([0])
The model predicted this one as the normal data point which is correct. With this, we conclude our case study of anomaly detection which leads us to the concluding section of this article.
Challenges, further studies and more
We now have reached to the final section of this article. We have introduced ourselves to the whole world of anomaly detection and several of its nuances. Before we wrap up, it would be a good idea to discuss a few compelling challenges that make the task of anomaly detection troublesome -
- Differentiating between normal and abnormal effectively: It gets hard to define the degree up to which a data point should be considered as normal. This is why the need for domain knowledge is needed here. Suppose, you are working as a Data Scientist and you asked to check the health (in terms of abnormality that may be present in the data) of the data that your organization has collected. For complexity, assume that you have not worked with that kind of data before. You are just notified about a few points regarding the data like the data source, the collection process and so on. Now, to effectively model a system to capture the abnormalities (if at all present) in this data you need to decide on a sweet spot beyond which the data starts to get abnormal. You will have to spend a sufficient amount of time to understand the data itself to reach that point.
- Distinguishing between noise and anomaly: We have discussed this earlier as well. It is critical to almost every anomaly detection challenges in a real-world setting. There can be two types of noise that can be present in data - Deterministic Noise and Stochastic Noise. While the later can be avoided to an extent but the former cannot be avoided. It comes as second nature in the data. When the amount deterministic noise tends to be very high, it often reduces the boundary between the normal and abnormal data points. Sometimes, it so happens that an anomaly is considered as a noisy data point and vice versa. This can, in turn, change the whole course of the anomaly detection process and attention must be given while dealing with this.
Let’s now talk about how you can take this study further and sharpen your data fluency.
Taking things further
It would be a good idea to discuss what we did not cover in this article and these will be the points which you should consider studying further -
- Anomaly detection in time series data - This is extremely important as time series data is prevalent to a wide variety of domains. It also requires some different set of techniques which you may have to learn along the way. Here is an excellent resource which guides you for doing the same.
- Deep learning based methods for anomaly detection - There are sophisticated Neural Network architectures (such as Autoencoders) which actually help you model an anomaly detection problem effectively. Here’s an example. Then there are Generative models at your disposal. This an active field of research, however. You can follow this paper to know more about it.
- Other more sophisticated anomaly detection methods - In the case study section, we kept our focus on the detection of global anomalies. But there’s another world of techniques which are designed for the detection of contextual and collective anomalies. To study further on this direction, you can follow Chapter 12 of the classic book Data Mining. - Concepts and Techniques (3rd Edition). There are also ensemble methods developed for the purpose of anomaly detection which have shown state-of-the-art performance in many use cases. Here’s the paper which seamlessly describes these methods.
This is where you can find a wide variety of datasets which are known to have anomalies present in them. You may consider exploring them to deepen your understanding of different kinds of data perturbations.
More anomaly detection resources
- Anomaly Detection Learning Resources - A GitHub repo maintained by Yue Zhao
- Outlier Detection for Temporal Data by Gupta et al.
- Outlier detection methods for detecting cheaters in mobile gaming by Andrew Patterson
We have come to an end finally. I hope you got to scratch the surface of the fantastic world of anomaly detection. By now you should be able to take this forward and build novel anomaly detectors. I will be waiting to see you then.
Do you model for living? 👩💻 🤖 Be part of a ML/DL user research study and get a cool AI t-shirt every month 💥
We are looking for full-time data scientists for a ML/DL user study. You'll be participating in a calibrated user research experiment for 45 minutes. The study will be done over a video call. We've got plenty of funny tees that you can show-off to your teammates. We'll ship you a different one every month for a year!
Click here to learn more.
Thanks to Alessio of FloydHub for sharing his valuable feedback on the article. It truly helped me enhance the quality of the article’s content. I am really grateful to the entire team of FloydHub for letting me run the accompanying notebook on their platform (which is truly a Heroku for deep learning).
FloydHub Call for AI writers
Want to write amazing articles like Sayak and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Sayak Paul
Sayak loves everything deep learning. He goes by the motto of understanding complex things and helping people understand them as easily as possible. Sayak is an extensive blogger and all of his blogs can be found here. He is also working with his friends on the application of deep learning in Phonocardiogram classification. Sayak is also a FloydHub AI Writer. He is always open to discussing novel ideas and taking them forward to implementations. You can connect with Sayak on LinkedIn and Twitter.