NLP Datasets: How good is your deep learning model?
With the rapid advance in NLP models we have outpaced out ability to measure just how good they are at human level language tasks. We need better NLP datasets now more than ever to both evaluate how good these models are and to be able to tweak them for out own business domains.


In a previous post we talked about how tokenizers are the key to understanding how deep learning Natural Language Processing (NLP) models read and process text. Once a model is able to read and process text it can start learning how to perform different NLP tasks. At that point we need to start figuring out just how good the model is in terms of its range of learned tasks. Is it good at just one task or does it perform well on a range of tasks? Does it learn new tasks easily and with little training? And how well does it compare to other NLP models which perform the same or similar tasks?
This is an important part of the process. Think of BERT, it created a buzz when it arrived on to the scene in 2018 because of how it performed on a range of NLP tasks. Businesses choose which models to put into production based on how well they perform on different datasets. However it's difficult to know exactly which dataset to use as your baseline. What if one model performs well on a translation task for example but poorly on a question and answer type task. How do you compare this with a model that did just ok on both? In this blog post, to answer these questions, we will look at one of the most recently published NLP datasets and see how it tries to deal with these issues when trying to provide a benchmark for comparing cross lingual NLP models. But first, what do datasets have to do with Adam Driver?
Datasets, the movie, starring Adam Driver?
I think it is fair to say that datasets are not the “sexiest” part of the exciting new developments in deep learning NLP. When you read a new paper describing the new human-like performance of the latest model you are unlikely to hear people state, “wow, I can’t wait until I get my hands on the dataset, it sounds amazing!”. Similarly, unfortunately for the NLP community, it is doubtful Hollywood would like to make a film starring Adam Driver about creating the world's most comprehensive machine learning dataset. But, Adam Driver or no Adam Driver, good datasets are the main pinch point in the AI pipeline which is driven (driven, Driver, get it? I am here all week, try the veal!) by advances in deep learning NLP. It’s no longer Moore's law that’s fuelling the rate of change in computing technology, it's datasets.
There was a point, even in the early 2000’s where computing power was a limiting factor. But now we are shifting towards a new type of software, or software2.0 as described by Andrej Karpathy, where the goals of a program are more abstractly defined and things like algorithmic improvements are likely to achieve more gains than any advance in computer performance. At the core of this new software 2.0 paradigm are, you guessed it, datasets.
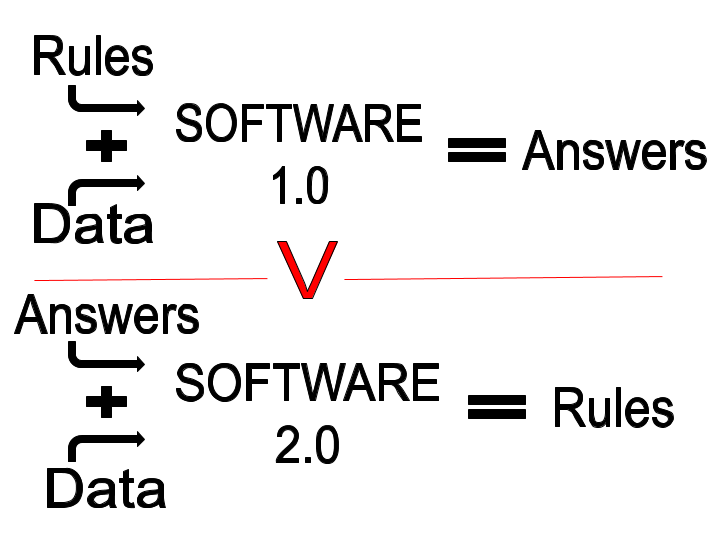
Since we no longer have specific instructions in the detailed steps of our programs, we create learning goals, for example, here are loads of pictures of Adam Driver, figure out how to identify him from pictures that do not contain Adam Driver. I can’t tell the program to use his hair, or his nose or his eyes or whatever features to differentiate him from everyone else. That was software 1.0, here is a list of rules as to how you, the computer, should identify Adam Driver. This is where the datasets come into play. We need them firstly, to train our Adam Driver image classifiers. And secondly, we need good datasets to benchmark the best Adam Driver classifiers out there.
NLP models like GPT-2 have already surpassed capabilities of earlier datasets which foresaw a much more gradual increase in machine learning capabilities in key NLP tasks. By current standards they are already performing at a near or better than human level of performance in a suite of NLP tasks. However, this shows the limits of our current datasets rather than the fact that these models are as good as humans in things like question and answering tasks. We are not quite at the HAL-9000 “I'm sorry, Dave. I'm afraid I can't do that” rubicon of machine learning language understanding. Sorry Hal, it will take a few more years before you exist.
Better datasets mean better models. If you understand how these datasets are structured then you will understand what the model can learn from them. Also, with the rise in transfer learning and fine-tuning of pre-trained models, it is likely you will need to create your own dataset to tailor these models to your unique business domain. This is easy if you already know the tasks and datasets on which the model was originally trained. If you get your dataset right, who knows, you might create your own HAL and Adam Driver will play you in the movie!
Datasets might not be cool but they are XTREME!
In the past I found it difficult to get a good overview of the NLP dataset landscape. There seemed to be no decent map to help navigate the myriad different NLP tasks and their corresponding datasets. Some models used translation datasets from Stanford, others used the Penn Treebank dataset to test for Part-Of-Speech tagging (POS), and then models such as BERT used a wide range of tasks to show the power of their model. What tasks should we aim to test our models on and which datasets should we use for those tests? Also, up until a few years ago, unless you were knee deep in academia or you had a Scrooge McDuck amount of money (interesting, recent research suggests his wealth at potentially over $5 Trillion, so take that Jeff Bezos, but I digress) then there seemed little value in trying to understand these datasets. It would just not have been feasible to train models from scratch on them. Due to cheaper computing resources, better learning architectures in models like ELECTRA or XLNet and resources such as HuggingFace, it is both easy and cheap to do so. And, given that, as we noted, you will very likely need to fine-tune these models to your own domain, it is now more important than ever to take some time to get to know these datasets.
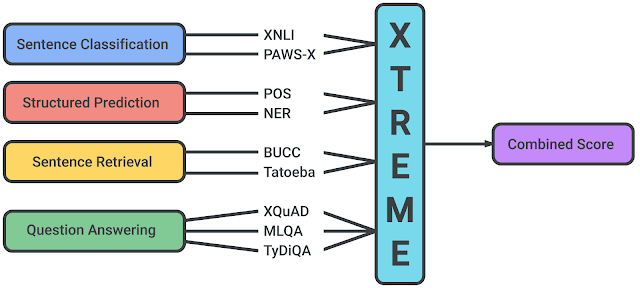
Right now is the best time to get started on these datasets as Google just launched a brand new multi-lingual, multi-task, multi-everything benchmark called XTREME which promises to help launch a new spate of linguistically talented NLP super models. The nice thing about this library is that it tried to put some structure on the NLP tasks needed to create a better model. It does this by defining four categories which are then made up of nine individual tasks.
Before I get a mailbag full of complaints, there are other resources that have tried to provide an all for one collection of NLP tasks, e.g. the Universal Dependency framework. But XTREME seems to be the first to try and organise it in a top down, category to tasks approach, to make it easy to understand the power of your model. Hence why I think it is a useful resource and the one I will use here as a way to frame the discussion.
Using XTREME as a guide we will first briefly review the categories and tasks discussed in their paper. Nothing too in-depth, just enough so that you know what each task is trying to do, and how it is structured. For example, how is the data labelled and how do you use it for training or testing. Then we will go through the different categories in mode detail and run some code to explore the datasets. We can also identify some other tasks or dataset that may also be useful but are not included in XTREME.
It should be noted that one of the main advantages of the XTREME dataset is its wide range of language support. There are many great datasets out there but many of them are only for english or other high resource languages. XTREME addresses this by ensuring that each task has a full range of different languages. XTREME is trying to provide a benchmark that measures a models general language ability. This is both in terms of a range of tasks, from low word level syntax tasks to higher level reasoning, and in terms of the models ability to transfer its learning to other languages (i.e. from English to a lower resourced language). So you can use XTREME to perform zero shot learning on a new set of tasks and languages. We won't be able to get into this level of detail but hopefully by making you aware of it you can dive deeper into XTREMEs many amazing features.
Do your green ideas sleep furiously?
The main NLP tasks, for XTREME or any other dataset, mainly fall within two broad categories. Either they are trying to teach the model about the word level syntactic sugar that makes up a language. Things like verbs, nouns and named entities. The bits and pieces that give a language its structure. Or they deal with the wider level of conceptual understanding and meaning which humans generally take for granted. For example, for humans it is easy to understand that “colorless green ideas sleep furiously” or “time flies like an arrow, fruit flies like a banana” are syntactically correct sentences but semantically meaningless or confusing. It is difficult for NLP models to process this high level of semantic understanding.
The holy grail for NLP is to train a model that learns a high level or "general" understanding of language rather than task specific knowledge. This is akin to the notion of Artificial General Intelligence (AGI) that posits machines can attain a level of intelligence that allows them to adapt and learn new concepts and skills in a human like fashion.
BERT was lauded precisely because it showed a high level of performance in a wide range of NLP tasks. If models like BERT could perform well on a wide rage of tasks then would it be possible for them to approach any NLP task and, similar to humans, adapt their knowledge to the task and understand the semantic issues with our above sentences? There is much debate about whether it is even possible for a machine to acquire this human like skillset. Some people even think this idea of AGI is impossible since there is no general level of intelligence for the machines to replicate.
This is relevant to XTREME since the authors noted that to understand a Language Model multilingual capabilities you need to evaluate it on a wide range of NLP tasks. It is not enough for a model to be good at translation since it may perform very poorly at classification or question and answering or lower level tasks. A good model should be able to perform well on a number of different tasks across a range of NLP skills. That is why the authors splits the NLP tasks into a number of groups.
XTREME Tasks layout
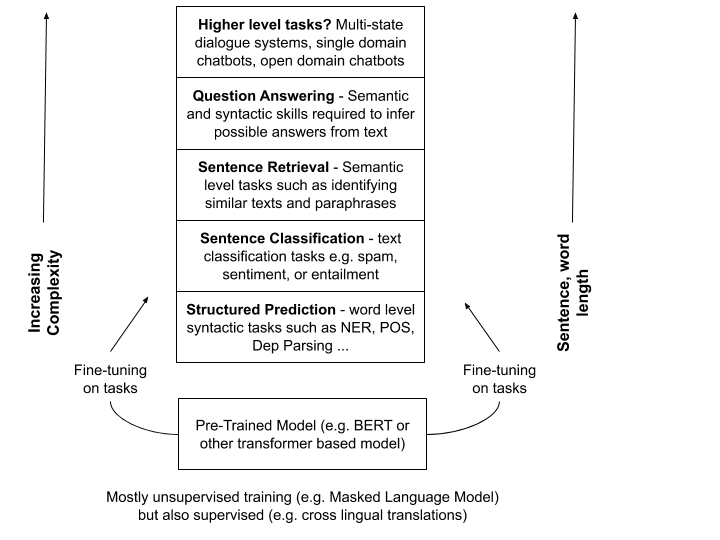
Roughly speaking we can define the type of NLP tasks as follows:
Structured Prediction: Focused on low level syntactic aspects of a language and such as Parts-Of-Speech (POS) and Named Entity Recognition (NER) tasks. These datasets provide sentences, usually broken into lists of individual words, with corresponding tags. For example, the list of tags for POS tokens can be seen here. This identifies whether something is a verb or a noun or even whether it is a “wh” type word. The NER list, in contrast, contains fewer tags and there are a few schemes you can use which is nicely shown here on the spaCy website.
Sentence Classification: There is no strict hierarchy here, but I think sentence classification is at the lower end of the syntactic-semantic tree. You could use classification tasks to train a model to differentiate between our "fruit files and green ideas" type sentences mentioned earlier. We could add a classification layer on top of pre-trained BERT and train it with loads of syntactically and semantically correct sentences against syntactically correct but semantically “weird” sentences. And it could perform well but it is a stretch to say that it has “learned” any knowledge of semantic knowledge. These models are smart and can “cheat” on these tasks to get results without gaining semantic knowledge. The classification can be for things like sentiment where the model has to decide whether something is mostly positive or negative. The reason classification is a somewhat higher level task is that it is based at the sentence level rather than at the word level for tasks like POS and NER. Sentences are infinitely more complex than words since there are, technically speaking, a defined number of words but an infinite number of ways in which they can be combined into a sentence.
Sentence Retrieval: Retrieval is another level up the complexity stack. These tasks try to find semantically similar sentences. This is more difficult than classification since there is more than one outcome for a sentence. It is not fully clear how these models identify similar sentences. You try interpreting a 512 dimensional vector and telling me what each dimension is for! “Oh, the 237th dimension is for cats🙀”. (I know this because I tried to interpret them, check out this blog on sentence embeddings and part two on using them to identify similar sentences to automate common tasks.) For example, are the sentences “I like Pizza” and “I don’t like Pizza” similar? On some level yes but if you are working in a restaurant and your chatbot routes someone saying they don’t like Pizza to the Pizza menu section then they won’t be too happy. Semantic retrieval or Semantic Textual Similarity (STS) tasks work by having many pairs of sentences associated with a label. The label can identify whether they are similar or not similar or even whether they are duplicates of each other.
Question Answering: Near the top of the stack we have the Question Answering (QA) tasks. These are more complex than the similarity tasks since the questions are not structurally similar to the answers and they need to take context into consideration. You can have simple versions of these tasks such as “what is the capital of Ireland?”. You could try and match this more easily than something like “what is the largest town in Ireland?”. First, what do you mean by largest? Population, land mass, miles of road? Then do you leave out cities and only look at towns? The complexity depends on the dataset since, for example, some QA datasets have an answer for every question. This makes a big difference since the model will know it can always find an answer. Others include answers that do not have an answer, and questions that have a short answer and a long answer and ones with just a long answer. So there is a lot more going on here.
Other Tasks? What about other tasks which are not included in the XTREME dataset such as text summarization and translation? Well let’s think about it in terms of what we just discussed.
First, text length. Both tasks require higher than word length text strings so this would suggest they are slightly higher up the complexity ladder than word level tasks such as NER and POS.
Next, the tasks itself. Some tasks are based on looking for things contained within the text itself. For example classification tasks are looking for clues that will help put something in one bucket or another.
Whereas QA tasks are trying to infer something that might not even be there in the first place. Is there even an answer here? If there is then it may not just be simply a case of copying the text and using that as the answer. Is it a long answer or a short answer. Do you need to leverage more knowledge outside of the text itself? For translation tasks you generally have the information contained in the text, e.g. this sentence is the French version of that sentence. (Cross lingual NLP models are trying to avoid this by generally training models to learn common language structures in an unsupervised fashion). Similarly, summarization involves condensing a certain chunk of text into a smaller size. This seems like a slightly more difficult task than translation since you are trying to figure out what to leave out and it may involve more combinations of syntax and semantics. So it seems like it is more complex than translation but somewhere below question answering on the complexity ladder.
Chatbots? While not a classic NLP task, you could say that the ultimate goal of creating more complex tasks is to create the potential for human-like chatbot interactions. This represents the highest level of complexity in terms of NLP since it involves a whole range of tasks from syntax up to semantics and inferring something from one domain to another. The performance of models at this chatbot like level is measured by competitions such as The Turing Test where a person needs to figure out if they are talking to a human or a machine.
For our practical purposes it is enough to focus on the type of tasks outlined in the XTREME dataset but it is important to keep the ultimate goal in mind. There is another layer of complexity within the realm of chatbots. For example, we can have simpler chatbots aimed at answering specific queries, or using simple rule based approaches. We can have more sophisticated combinations of rule and model based chatbots that try and deal with domain specific areas and finally we can have fully open domain chatbots able to talk to people about any topic.
None of this is a hard and fast rule in terms of the order of our complexity ladder. You may have different views on what constitutes a complex task. Indeed, the reason XTREME was created in the first place is since no one task can tell us which NLP model is the “best”. Some models that perform better on translation tasks have very little success when you try and transfer their skills to tasks such as NER and POS. Similarly, some models that perform well on POS or NER in one language struggle to transfer that performance to different languages. You could argue for a complexity element within different families of languages and use that to re-order the above layout. The main thing is to think about it yourself and come up with what you believe are some rough guidelines and use those going forward. Most importantly, be open to changing them when you see a task or language which seems to question your perceived world order.
Show me some code
Ok, ok, too much “waffle” and not enough coding. Let’s look at the layout of XTREME and also at other potential datasets which are not included in the XTREME library.
This notebook contains all the steps you need to explore the XTREME library of datasets. In the notebook you will see that we go through each step and you can try different things such as looking at other languages or parts of the dataset. Many of the steps are also show below to make it easy to follow along with the steps we are discussing. So feel free to jump back and forth between the two.
Initial Setup
The XTREME repo contains all the code you need to download most of the datasets automatically. There is just one dataset that needs to be manually downloaded. To make it easier to follow the individual steps are outlined in the README for the above notebook. To get started run through those setup steps and make sure you have all the datasets downloaded.
XTREME Task Layouts
- Structured Prediction (NER & POS)
- Sentence Classification
- Sentence Retrieval
- Question Answering (QA)
Structured Prediction
Named Entity Recognition (NER)
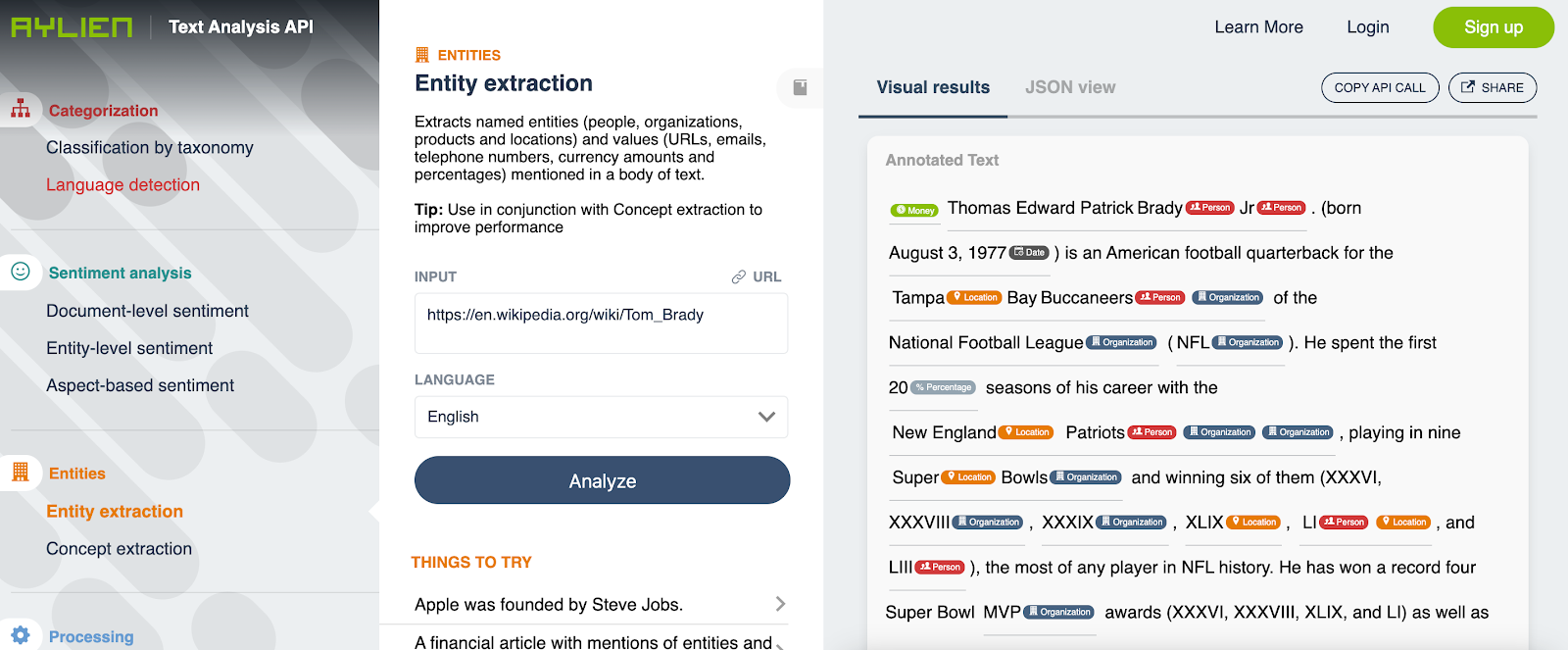
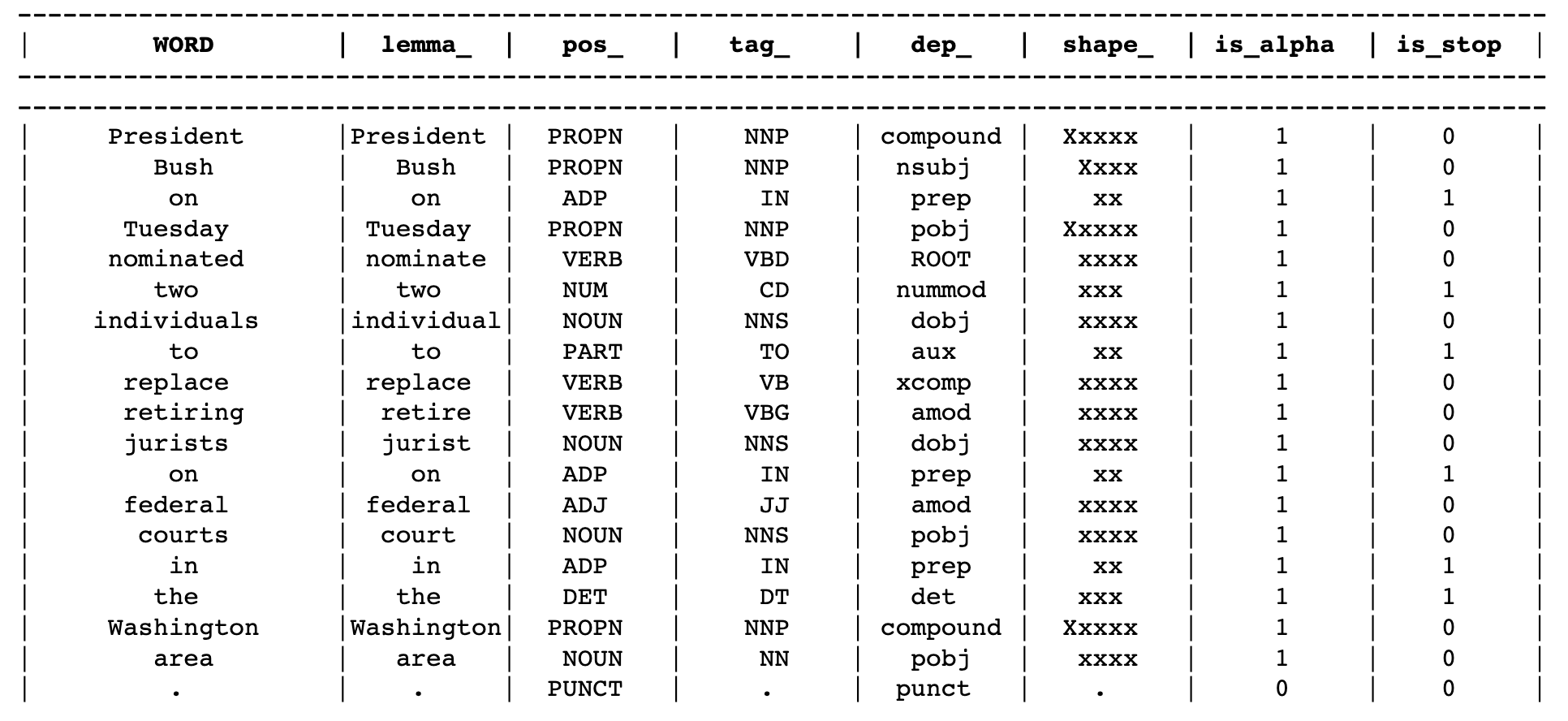
First let's look at the structured prediction datasets in the XTREME package. Don’t worry too much about the specifics of things like what each "token" means for now, we will cover that in due course. Just try and understand the general layout and how you might be able to use it to either train or fine tune your own models.
NER - Explained in more detail
In simple terms a named entity is any term or word that represents a real word object. In the sentence, “Tom Brady is the quarterback for the Tampa Bay Buccaneers”, “Tom Brady” and “Tampa Bay Buccaneers” are the named entities since they represent a person and an NFL team respectively. “Quarterback”, by contrast, is not a named entity since it can refer to different people. In other words, it is not specific to the entity “Tom Brady”. A named entity may be any person, place, organisation, product or object. It’s usage is generally expanded to include temporal and numeric terms also even if they do not fit within the strict definition of the term.
NER can help with tasks such as information extraction when you want to answer questions such as how much a product costs, when a product is due to be delivered or what person a sequence of text is referring to. NER may also be very specific to your particular domain with unique product names or business specific terms. As a result it's important to find, or build, a good dataset to address these potential unique elements.
NER - what tags are used in your dataset?
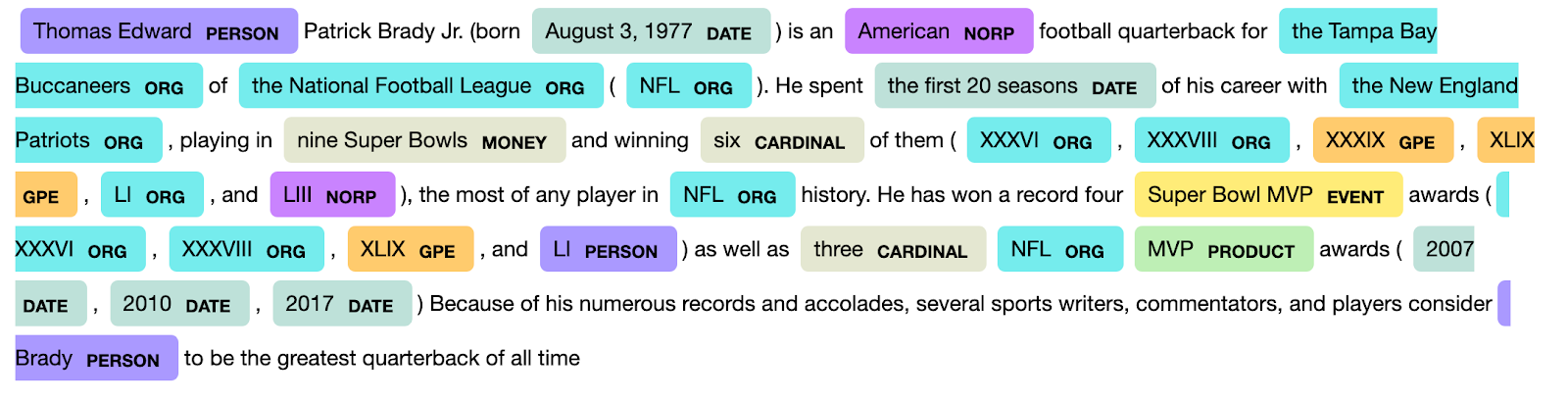
NER datasets will generally be structured in a word-token pairing where the token identifies whether or not the word is a named entity, and if so, the type of named entity it represents. As an example take the NLP library spaCy. Their NER model will identify named entities with tokens like “PERSON” which is a person, obviously, “ORG”, an organisation and so on. To see the full list of tokens check out their list here which also contains information to the NER dataset their models are trained on.
In contrast, other NER models and tools will use slightly different tokens to identify a named entity. Many datasets will follow what is known as Inside-Outside-Beginning Tagging or IOB-Tagging naming. This identifies, firstly, when something is not a named entity, the O or Outside tag. When something is a named entity then it can be either the Beginning or a named entity or Inside a named entity. The examples in the XTREME dataset will use this IOB format for the NER tasks. It’s just worth noting the different approaches in case you are using a different NER dataset and see a different type of tagging.
In the notebook there is a class to help us iterate through the XTREME NER examples so we can get a feel for them
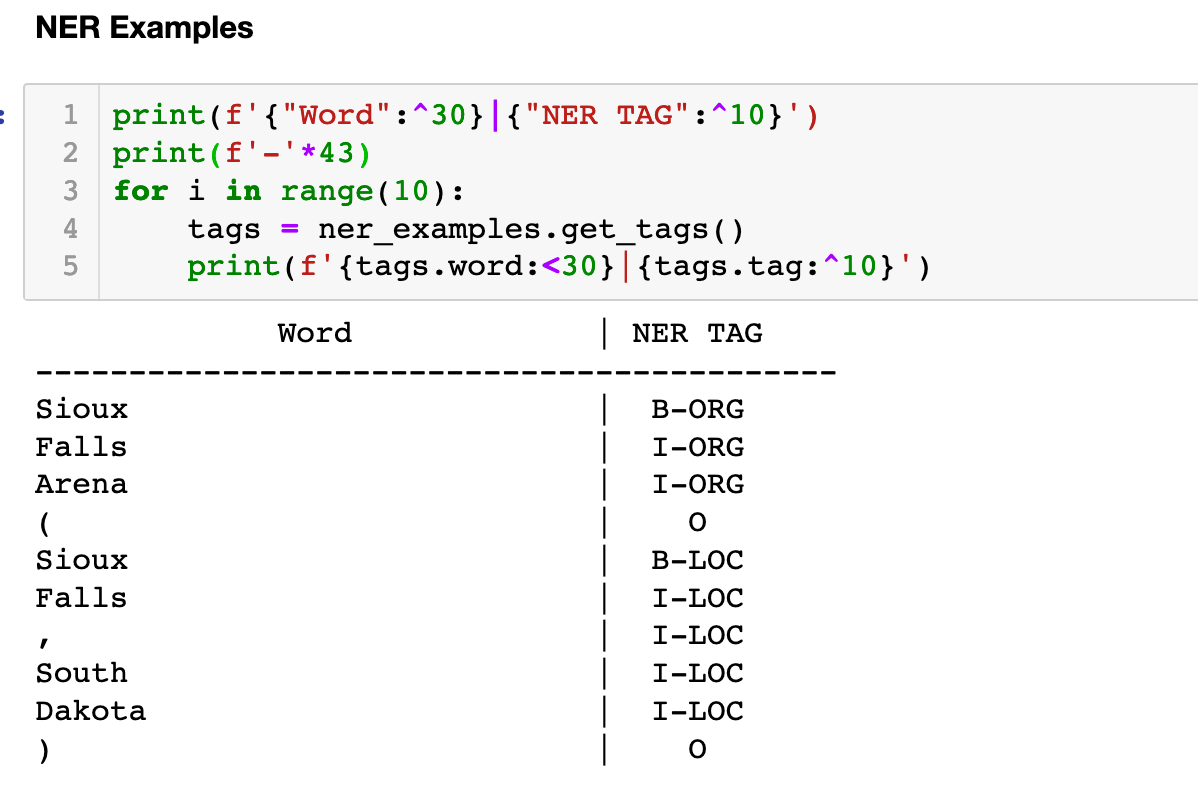


Note that spaCy allows you to use other models as well which use different tagging schemes such as the IOB-tagging or the BILUO scheme. These will use a different format but the spaCy default model uses the more straightforward approach shown here.
POS - Explained in more detail
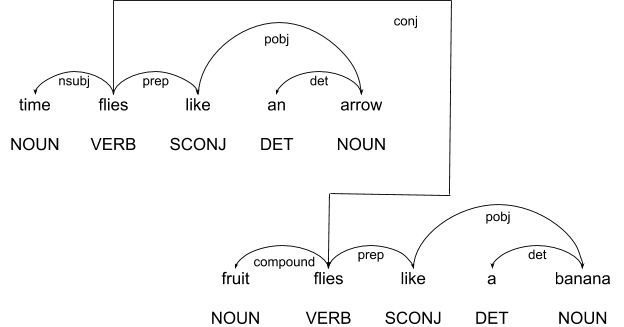
While NER looks for specific parts of a sentence to find entities, POS tries to understand the whole sentence and how each word interacts. Think of our earlier “time flies like an arrow, fruit flies like a banana”. The meaning of this sentence changes significantly depending on how you view the words in it. For example, does “time flies like an arrow” mean time moves fast or is it describing a type of fly, the “time” fly and their fetish for things arrow related? It depends, check out the different possibilities here.
POS tagging tries to help here by identifying whether something is a noun, verb, adverb and all that good grammatical goodness you were taught in school and have now forgotten. spaCy provides a neat way to vizualise the POS tags the output of which we can see above. According to that tagging the spaCy model does not think “time flies” are a thing. Really? Time flies are my favourite type of fly🦟
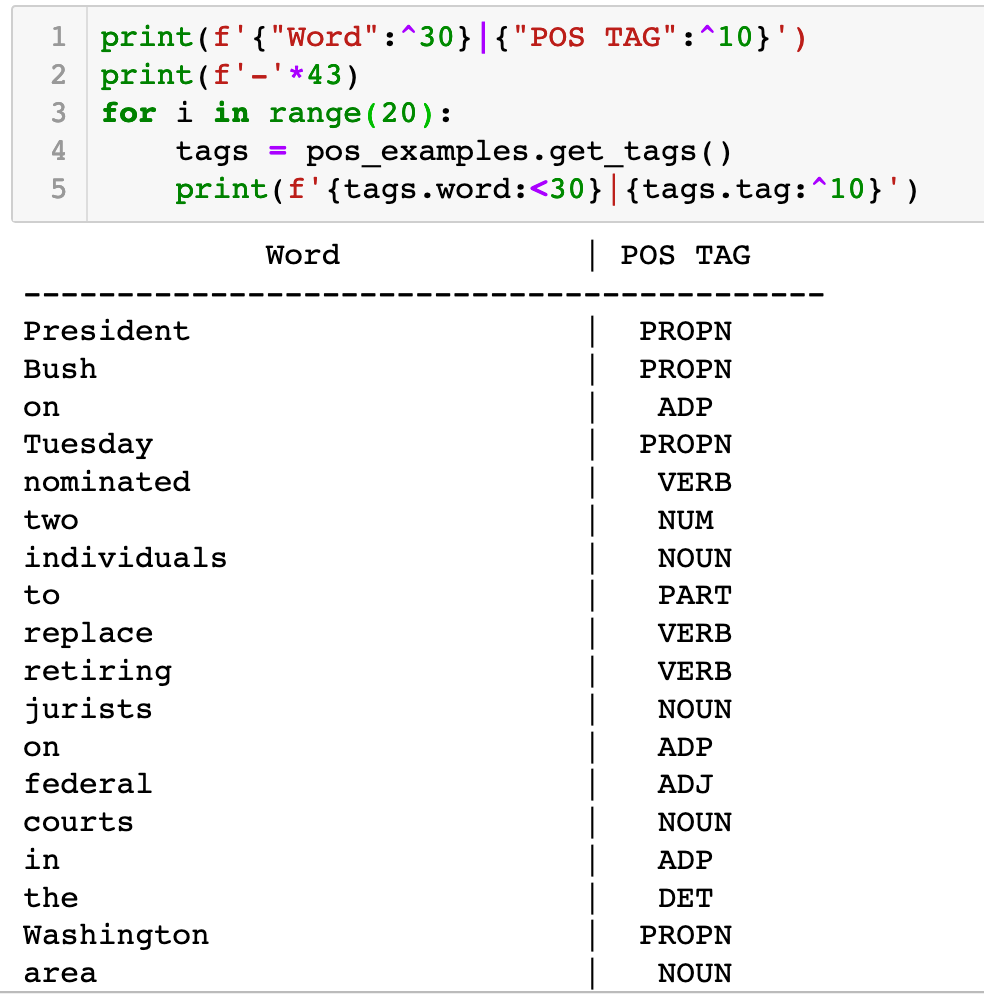
Either way, POS is, in many ways, more familiar to us from a simple grammar perspective than NER. We probably recognize more of the tags immediately and understand what it is trying to do. Whereas, with NER, the task may seem strange since few of us have stopped to try and explicitly identify the named entities in a sentence. It’s just so obvious to a human what is and isn’t a thing. For HAL 9000, however, this is a difficult task and hence the training required.
While POS tagging seems to make sense to us, it is still quite a difficult thing to learn since there is no hard and fast way to identify exactly what a word represents. But, as noted, there is less confusion about the tagging scheme than with NER so you should see most datasets contain some format of VERB, NOUN, ADV and so on. You can see the spaCy universal list here. In the notebook you can compare the tags with those in the XTREME dataset to see if there are any differences.

POS tagging is an important foundation of common NLP applications. Since it is such a core task its usefulness can often appear hidden since the output of a POS tag, e.g. whether something is a noun or a verb is often not the output of the application itself. But POS tagging is important for:
- Training models: Training NLP models like BERT or RoBERTa on POS like tasks is important to try and develop general linguistic skills which can help the model function in different domains. If these models learn POS skill then they have a better chance of developing general language skill which help them perform better in a wide range of tasks
- Text to speech: Enabling computers to speak more like humans is more important now with the increasing use of Alexa and SIRI like applications. POS tagging plays an important role in this area since languages such as english have words that are pronounced differently depending on their position and context in a sentence, e.g. read (pronounced as reed or red), live (as in alive or live rhyming with give) Word sense disambiguation: Remember our time flies sentence? Well POS tagging helps us understand whether the fly is a thing that buzzes around the place or whether it is referring to how quickly time goes by when you are having fun.
Sentence Classification

Some of the other datasets are easier to get to grips with than the NER and the POS. Some of the aspects of those tasks seem particularly technical and focused on the syntactic nuances of grammar and linguistics. Now, you might find that NER and POS tasks make perfect sense, maybe it is to do with my bad grasp of grammar✏️🤓 One of the interesting quirks about NLP tasks is that as the task complexity increases at a model level (i.e. when the task becomes more difficult for a machine to learn), to us humans the tasks often seem easier.
In the XTREME terminology "sentence classification" refers to a range of tasks that require a model to categorise sentences into a series of linguistic buckets. You may have come across classification tasks before where you classified something as spam or you classified reviews of a restaurant or product as being positive or negative or classifying articles into buckets of topics such as news or sport. The classification tasks implemented in XTREME are a little different and more difficult than traditional classifiers. They still require that a sentence be classified into two or more buckets. So the basic structure has not changed that much. But the buckets themselves are different. Now instead of sentiment or topics they are based on semantic relatedness, i.e. whether two sentences are paraphrases of each other or involve contradiction or things like entailment. This moves the type of classification task a little higher up our complexity ladder nearer things like sentence similarity. However, at its heart, it is still a classification with a defined number of outcomes or buckets.
Looking at pairs of sentences and deciding whether or not they are similar seems trivial to us humans right? Sure, there are some tough ones as any language will always have quirks and exceptions, but overall it seems like a reasonable task. Not so in the machine world. Before Skynet or HAl 9000 want to take over the world they need to understand much more about the whole crazy realm of human language.
Paraphrase Adversaries From Word Scrambling (PAWS)
If you want your model to identify whether something is a paraphrase of another statement you will want something like the PAWS dataset. Paraphrasing is a very important task in NLP. Think of a simple chatbot for a delivery company. A customer may want to update their delivery address or their account settings. A common way to phrase this may be:
- “Hi, how can I update my account?”
But there are many ways you could paraphrase this query:
- I would like to edit my account
- I would like to update my settings
- I would like to change my account details
- Can I modify my account details
And this could go on and on as we find different ways of asking about the same thing. This gets even more complicated as the text increases in size from a sentence to a paragraph and up to a page and so on. It is not ideal to try and code for all of these examples, and as humans we can that these are all essentially saying the same thing. Well datasets like PAWS are designed to help with this.
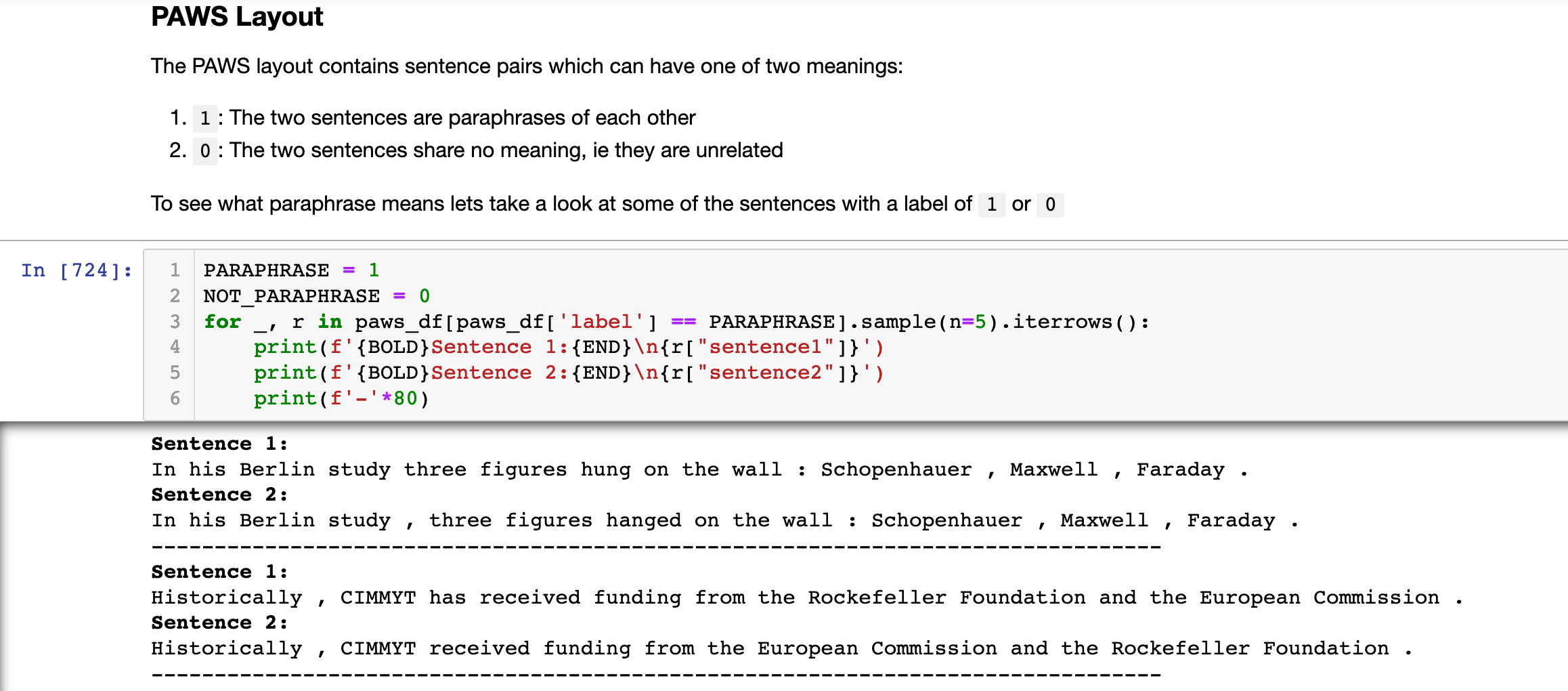
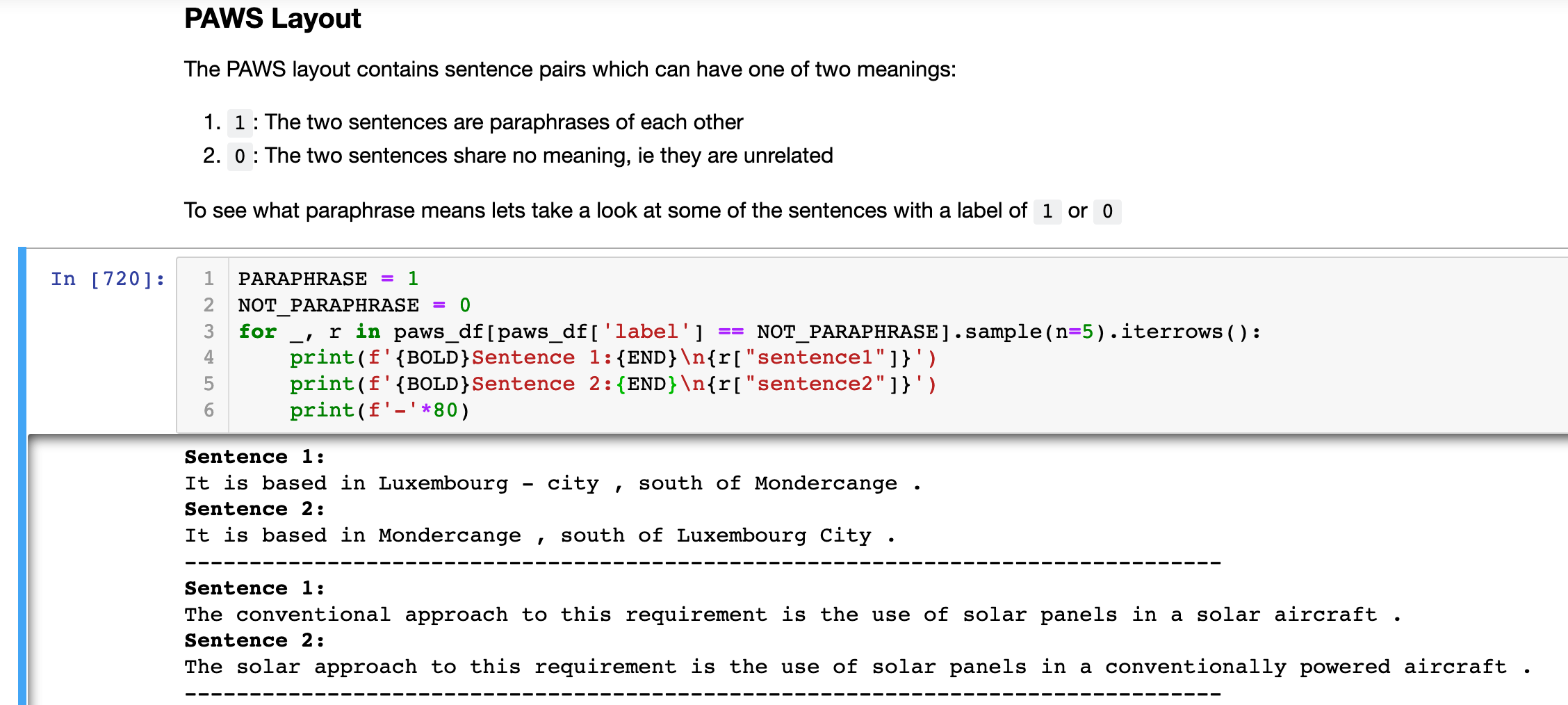
One of the issues PAWS attempts to deal with is that other NLP entailment datasets were, essentially, too easy. Remember, that neural networks are lazy, lazy lazy entities. They will try and lie and cheat and do as little as possible to get to where you want them to go. Some entailment datasets did not have much “lexical overlap” where sentences were not paraphrases. In other words, any sentences which contained similar words were usually paraphrases. This creates an opportunity for a neural network to “cheat” by just guessing that if there is some lexical similarity then it is very likely that the two sentences are paraphrases of each other.
The example they use in the paper is “flights from Florida to New York” and “flights from New York to Florida”. While similar these are obviously different things. You would not like your chatbot to think these are the same things when you try and book your flight back to New York✈️🗽 But most datasets don't have this level of subtlety so it can be easy for a shifty model to get a high score in some tasks. PAWS has specifically addressed this by word “swapping” or “scrambling” between pairs of sentences to generate negative paraphrase examples.
Your dataframe for these tests should look something like this:

Where you can see the labels describing whether sentences are either:
- 1: Both sentences are paraphrases of each other
- 0: The sentences have a different meaning, note, this does not necessarily mean they are contradictory. Just that they are unrelated.
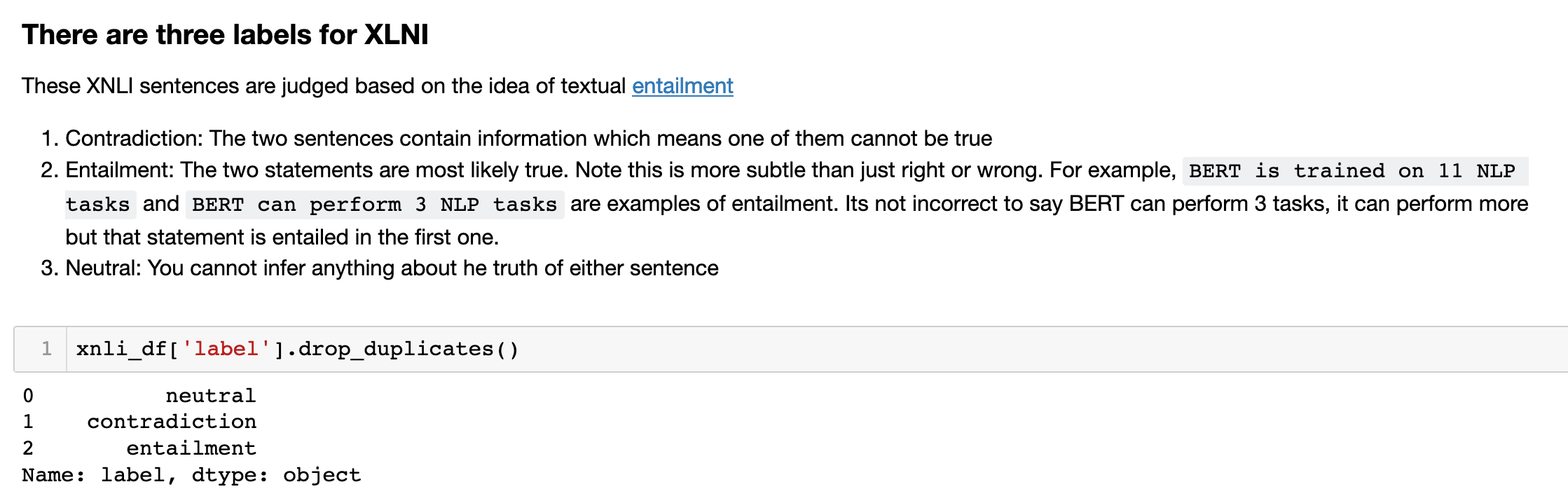
Cross Lingual Natural Language Inference (XNLI)

The XNLI dataset has more buckets than PAWS-X as something can contradict, entail or just be neutral. It extends work already undertaken with natural language classification to a large number of low resource languages. The goal being to provide a way to perform sentence classification beyond english without needing separate datasets for every language.
This avoids having to train a system from scratch for each language and instead is trained on one language and evaluated on data from other languages. This, the authors claim, is more “scalable” than different systems all evaluating different languages. It is great that training, testing and standardising mode for low resource languages is seen as a priority. This will hopefully make it much easier to find pre-trained models for most languages that you are looking for in future.
The layout of XLNI is quite similar to PAWS in that there are pairs of sentences with a label. The difference from PAWS is that there is more nuance to the label. The label can be:
- Neutral: Indicating that there is no relationship between the sentences
- Contradictory: The sentences contain information contradicting each other.
- Entailment: The sentences are paraphrases of each other.

Sentence Retrieval

Beyond sentence classification we move up the stack of complexity to sentence retrieval tasks. Again, its not a hard and fast rule in terms of the hierarchy of complexity but with classification we usually have defined buckets of outcomes. With the XLNI dataset, for example, classification tasks had three bins which a result could fall into. By contrast, with sentence retrieval, the outcome is less defined.
Building and Using Comparable Corpora (BUCC)
The BUCC is an interesting dataset since it tries to reduce the potential for models to use external cues, such as metadata, e.g. URLs, to “cheat” and gain heuristic insight when trying to identify similar sentences. The BUCC dataset thus has no such metadata and they have even made it difficult to obtain the original dataset from which the sentences were obtained. This makes it almost impossible for someone to find the sentence in the original dataset and thus avail of the meta-information heuristic cues.
The BUCC approach appears to be a series of workshops that brings people together to create better training data from both a computational, cross-lingual and linguistics approach. This is innovative approach since it involves both the linguistic and computational (i.e. machine learning, deep learning, statistical and so on) communities working together to create better text corpora. Combining the skills of both communities is a great way to find the best way forward in this domain.
The BUCC dataset in XTREME contains a “gold” file for each language pairing. This contains the matching pairs for the corresponding files. That way you can match the english sentence with, for example, with its German counterpart.

Tatoeba Sentence Translations
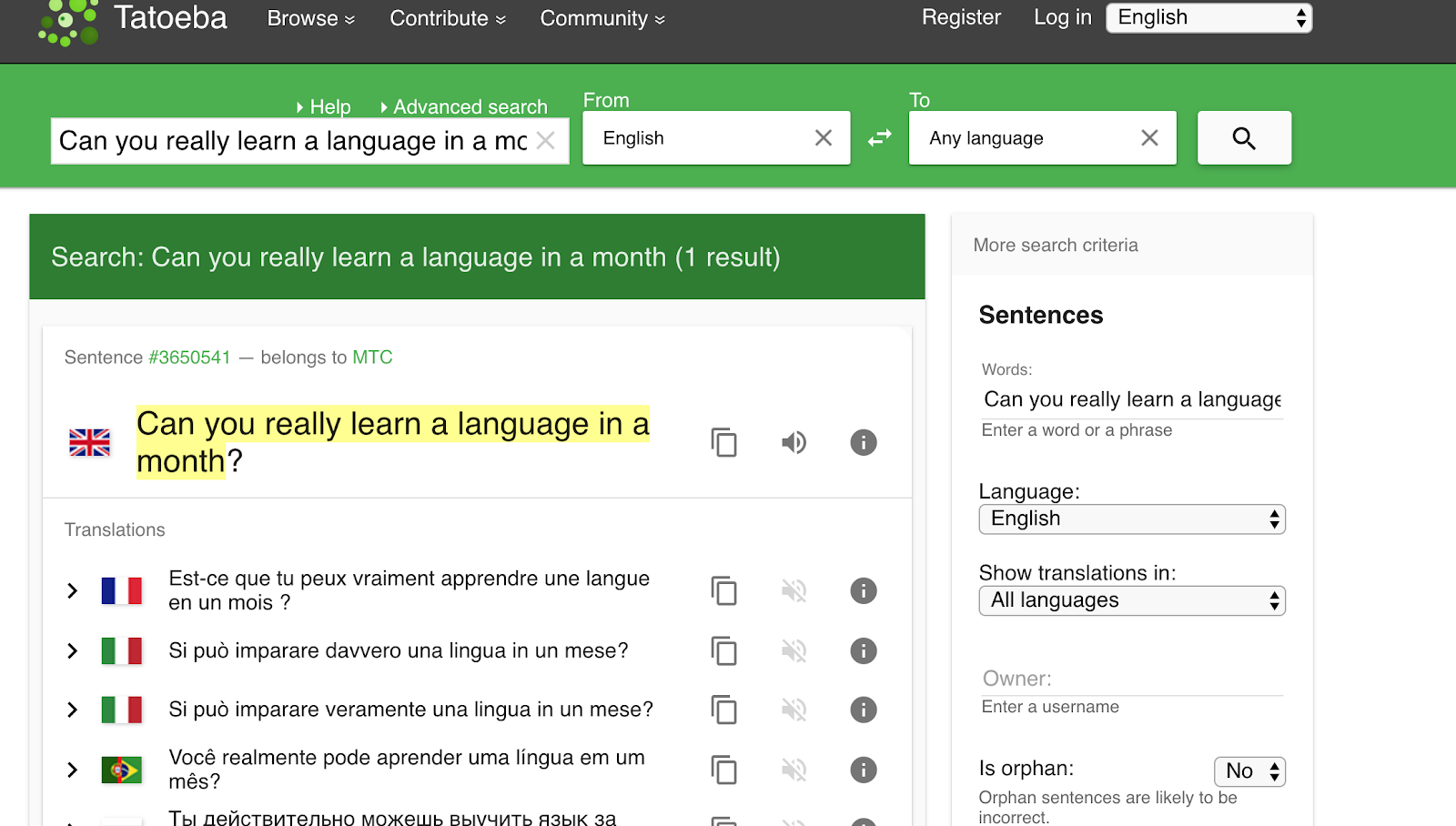
Tatoeba is an open source project which aims to create sentence translation pairs by getting people to translate from a foreign language they know into their native language. You can checkout their website here where you can play around with the dataset interactively.
You can enter a word and then find sentences in different languages which contain that word. You can then click on a sentence to check out other sentences in different languages.
The tatoeba dataset is described in this paper and is used to find a much wider based on language translations to train on. The files consist of 1000 english aligned sentences for each pair. So you can look at a French to English translation for example. For this there will be an English file and a French file which should align so you can identify the corresponding sentence pairs. The original source for this data can be found in the LASER github repo if you want to check that out.
Note that in the XTREME dataset there appears to be only a test set available for the Tatoeba dataset. You can see this here as the sentences do not align properly

In most of the other datasets in XTREME there are some data available so that you can fine tune your model on different languages and test its zero shot learning capabilities. But with this dataset it seems to only allow for testing you model.
However, we can download the dataset itself following some of the steps in the download_data.sh script

Question Answering (QA)
And, last but not least we come to the question answering tasks. By now you should be seeing a pattern where the tasks require a little more from our models in terms of their linguistic capabilities. For example, in similarity tasks a model can look for statistical or heuristic cues to guess that something is likely to be related.
This is also a factor for QA, but it is more difficult to find these cues since the nature of a questions are more open ended. There can be a variety of responses, or none if there are no answers, to a particular question. The structure of the dataset will define the difficulty of the task by, for example, not including an answer for every question, or including a specific answer for each question. These factors will influence how the model behaves in the real world when it comes to searching through a document to find an answer to someone's query. Datasets that are designed to resemble real-world type scenarios will ensure models perform better out in the wild since they do not expect the data to be too clean or perfectly aligned.
Stanford Question Answering Dataset (SQuAD)
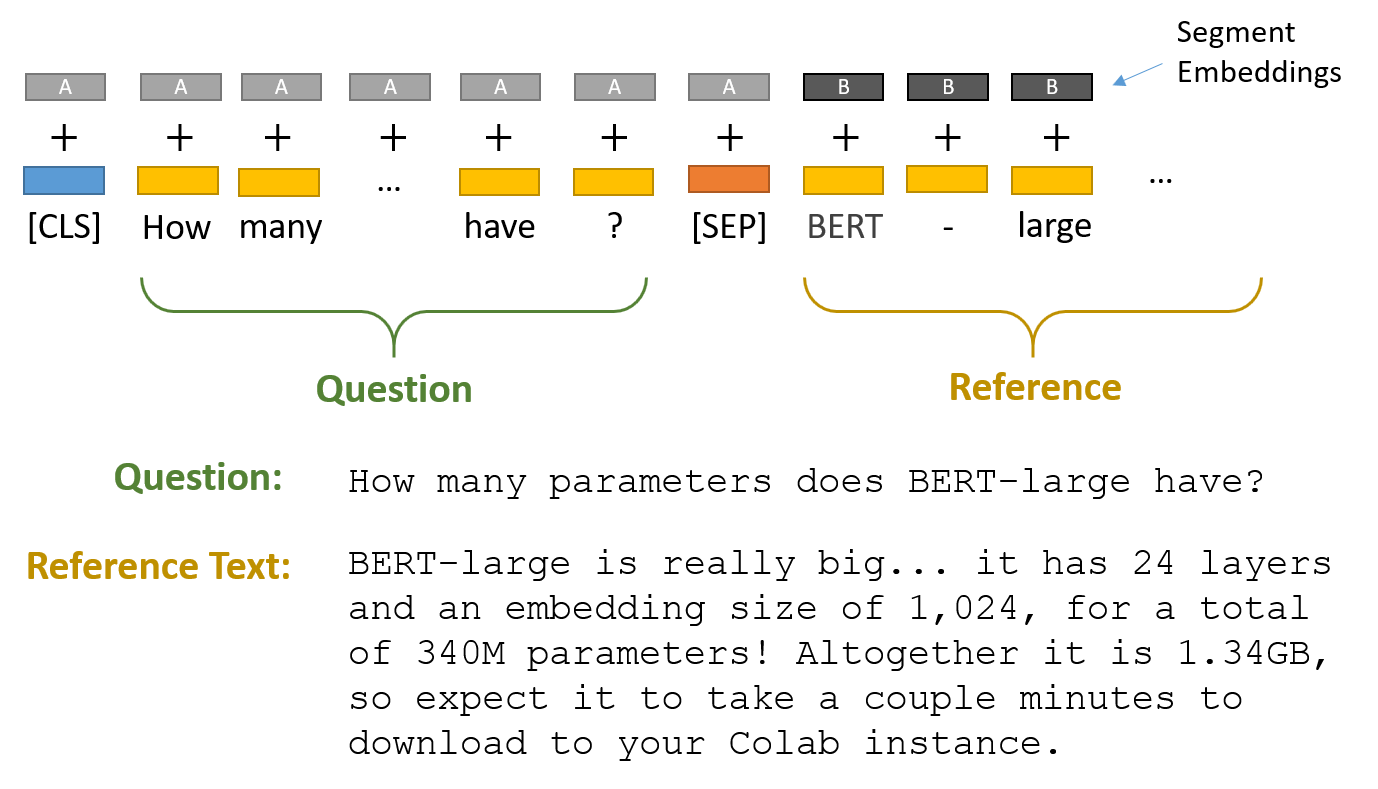
The first thing to note about the three QA datasets is that they all follow what is known as the SQuAD format. SQuAD is a crowdsourced dataset which is created by volunteers who write questions based on wikipedia articles. So they look at an article and then create a question whose answers is contained within a certain span of text for that article. There are two versions of the SQuAD dataset, SQuAD2.0 and SQuAD1.1.
One of the main differences between these versions is that in version 1.1 all the questions were answerable. So the model could “cheat” and now that there was always an answer (remember, neural networks are lazy and will take the line of least resistance if you let them). In version 2.0 there are 50,000 unanswerable questions so models now need to establish if there is indeed an answer to each question before providing an answer.
The dataset is basically a json file which contains sets of questions and answers with a corresponding context paragraph. For example, here are some questions on the happy topic of the “Black Death” which you can check out on the interactive demo page for the project.

The fact that the QA datasets in XTREME are all in this format is great for us since it means we can explore them in the same way and don’t need to learn a new format for each one. This means we can create a simple class that uses a generator so that we can easily look through the examples one by one and then use that on all the QA datasets
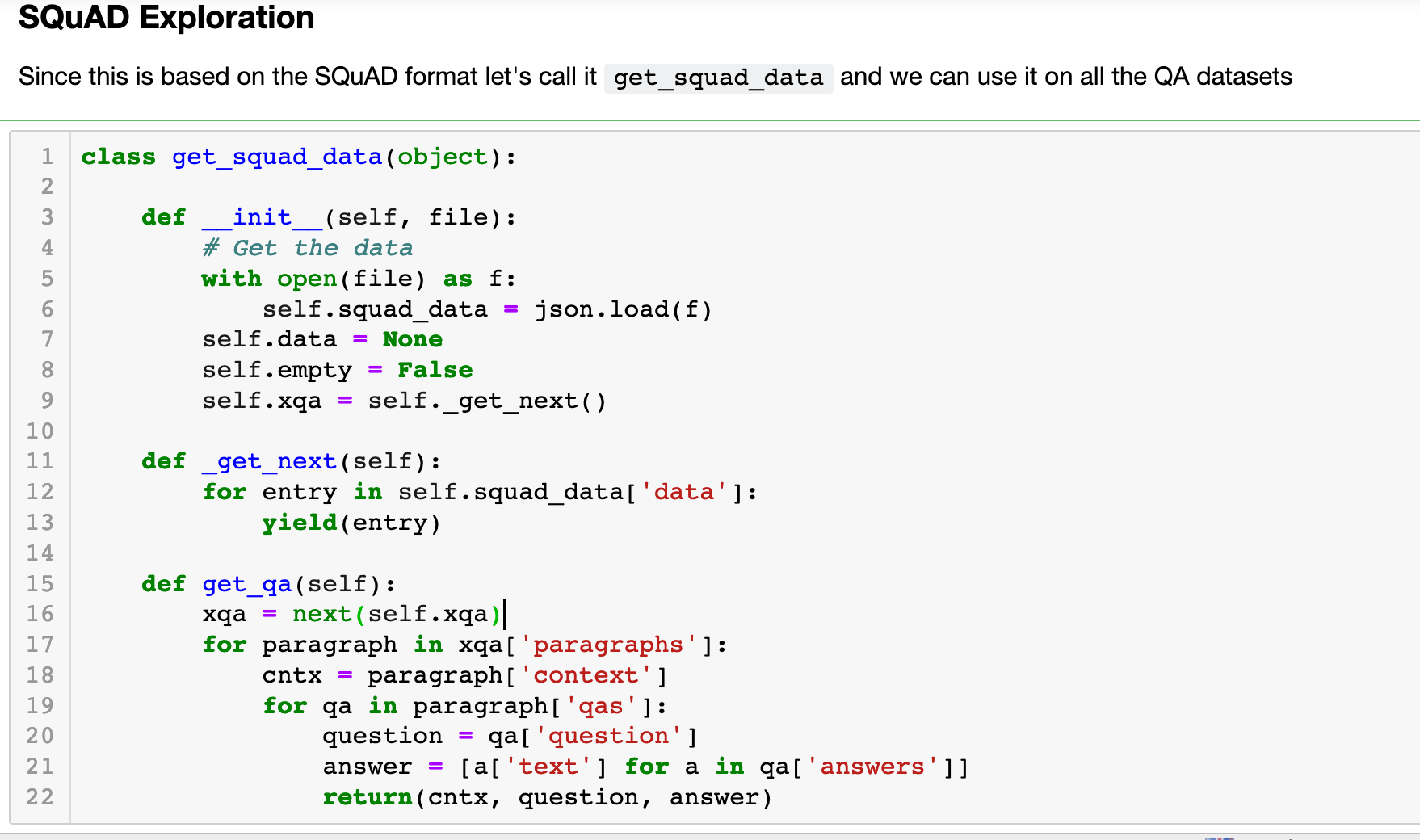
get_qa will iterate through the examples one by oneCross-lingual Question Answering Dataset (XQuAD)
XQuAD is basically the SQuADv1.1 dataset but expanded for multiple languages. This paper provides a great overview of what the authors were aiming for when they created the XQuAD dataset.
Firstly, they wanted to ensure that these datasets were available for languages other than english. But, secondly, they wanted to show that it is possible to train a model on one language and then use transfer learning to enable it to learn another language. This is in contrast to other approaches which require pre-training on each individual language in order to develop a multilingual model.
This has lots of benefits, if you can use monolingual models then we can train them on high resource languages such as english where we have lots and lots of nice training data. This is a key goal of the entire XTREME dataset itself, so it is trying to do what XQuAD was doing in QA to a range of NLP tasks. Training on a high resource language means we can use the shared language understanding of these models to learn other languages without requiring re-training on a translated or related version of that dataset in another language.
In the author's own words, this shows “that deep monolingual models learn some abstractions that generalize across languages”. Which, when you think of it is pretty neat, maybe HAL is closer than we think? My "colourless green ideas are definitely sleeping furiously now 🛌😴"
The XQuAD version in XTREME does not have the answers to the questions so you can download the original dataset if you want to checkout the answers. There is an example of this in the notebook and you can see an example question and answer below
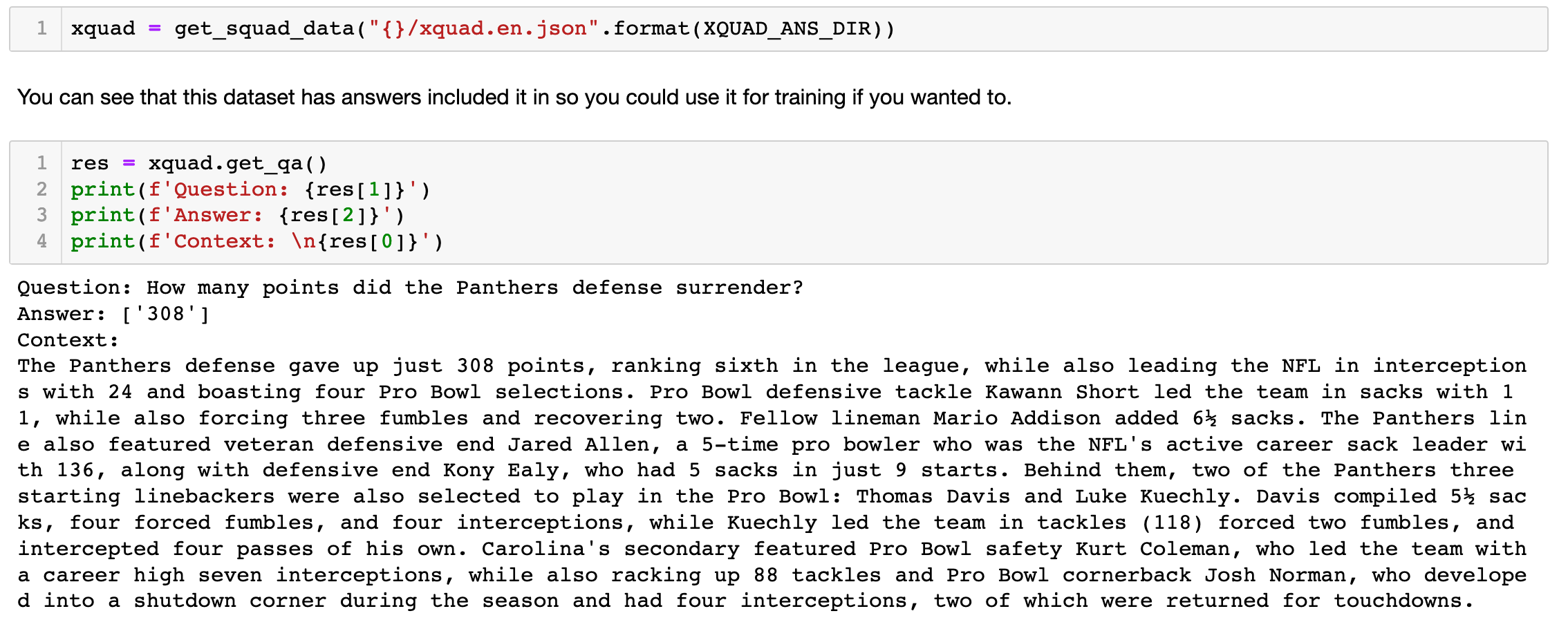
MultiLingual Question Answering (MLQA)
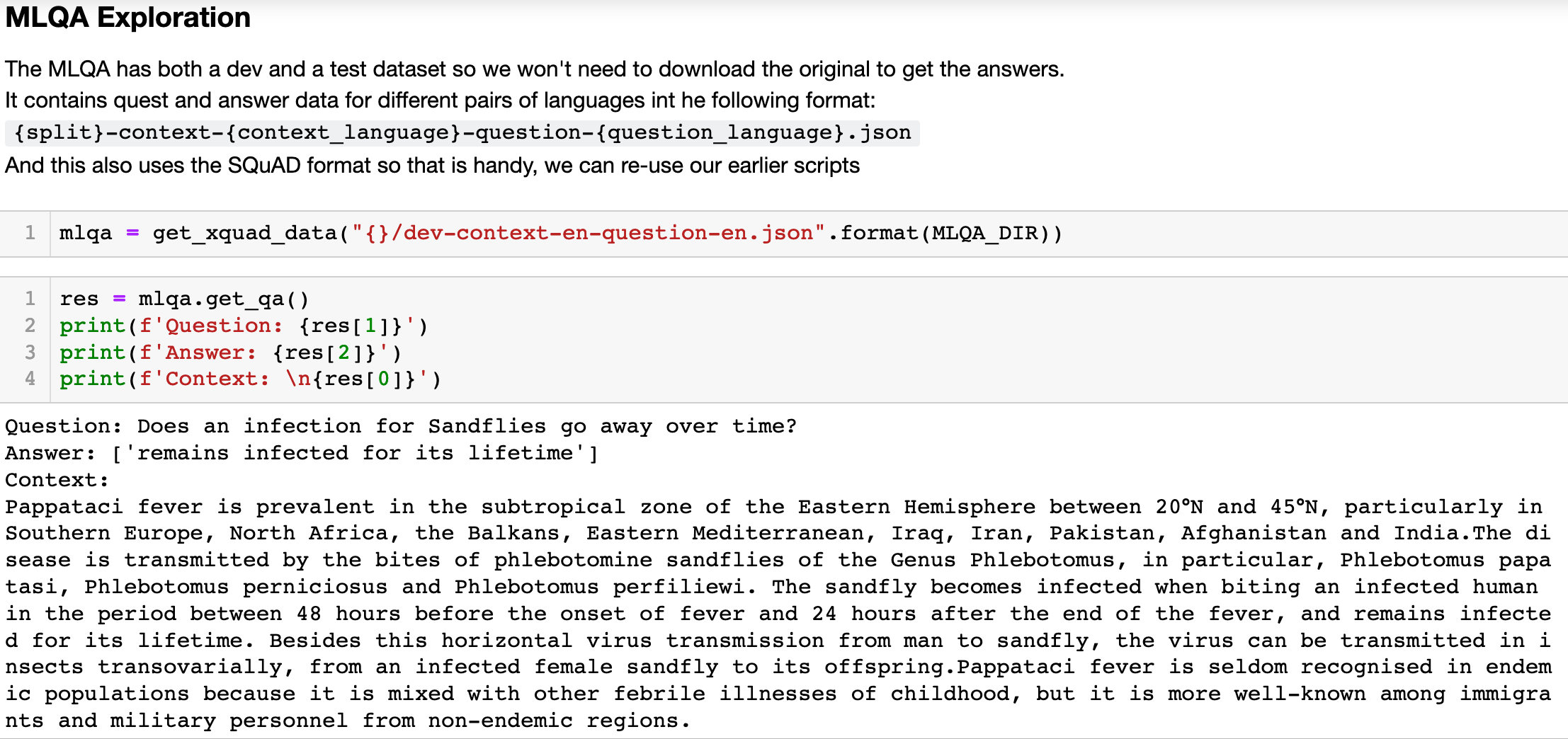
MLQA is also aimed at making it easier to develop, test and evaluate multilingual QA models. As noted it uses the SQuAD format to create a multilingual purpose built evaluation benchmark which covers a wide range of diverse languages.
The interesting thing about MLQA is the way it is constructed:
- English sentences are identified in Wikipedia which have the same or similar meaning in other languages
- These are extracted with surrounding sentences to create a context paragraph
- Questions are then crowd sourced for these English paragraphs. The questions should relate to the sentence identified in 1.
- The questions are then translated into all the relevant languages and the answer span is noted in the context paragraph for the target language
In this way you can find questions in English which have an answer in a corresponding English paragraph or you can find a question in Spanish, for example, with a corresponding English answer.
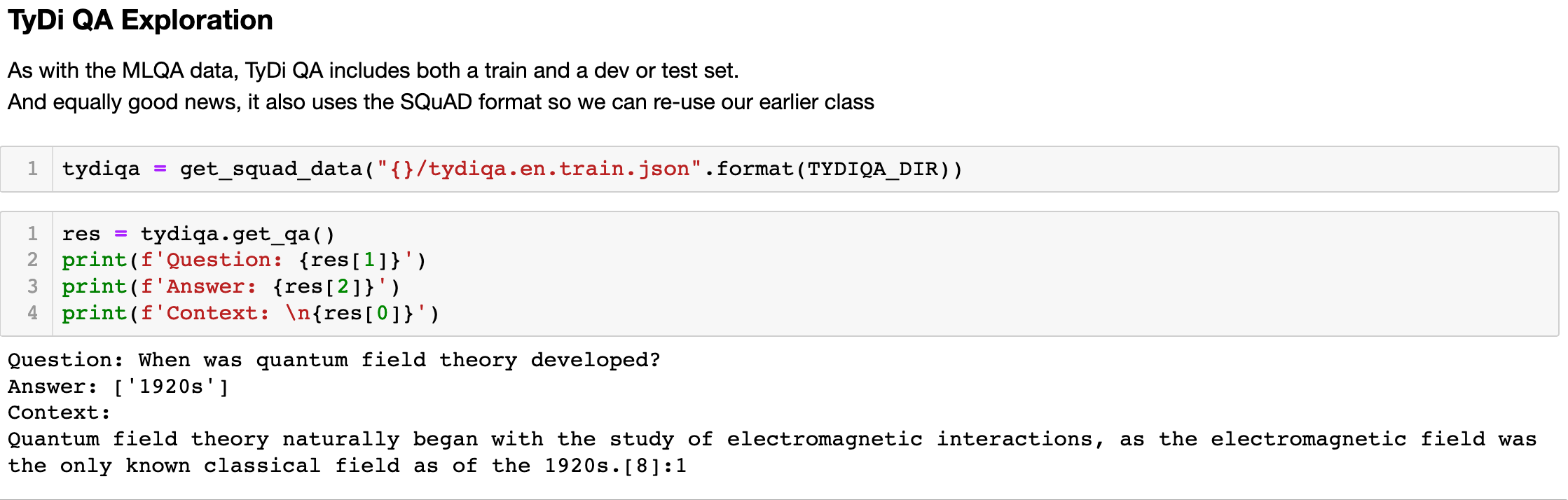
Typologically Diverse Question Answering: (TyDiQA)
TyDiQA is another great new addition to the QA evaluation framework. Again, it is aimed at providing the tools to train and evaluate cross lingual deep learning models. The TyDiQA dataset attempts to raise the bar in terms of the skill required to answer a question. They do this by getting people who want to know the answer to generate the questions before they know the answer. In other dataset, such as SQuAD, people read the answer before creating the question so this could influence how the question is curated.
The hope here is that this will help create more natural questions and prevent models from relying on “priming” issues (i.e. creating questions when you already know the answer) and using statistical cues to “cheat” and find the answer. This will, hopefully, help models generalise over many different languages. As with the other datasets in this section, the paper is a great resource if you want to understand the QA space in mode detail.
Datasets are key for Software 2.0
As we noted at the start of this post, we are in the midst of a transition from traditional software architecture to a new software paradigm where we no longer provide machines with a set of instructions and data. Instead, we provide neural networks with a general goal or outcome and then provide them with lots of data. So instead of giving someone a starting point A and directions on how to get to point B, we provide them with the point A and B and tell them to figure out how to get there. This new paradigm requires a lot of data. It needs datasets to first figure out the rules but, just as critically, datasets are required to find out if someone came up with the the correct instructions. What if there are different instructions? Which one gets you from A to B in the shortest time or via the best route?
XTREME is an example of a new key foundational block in the future development of software 2.0. It allows us to see which models are actually creating the best rules to understand different human languages and adapt that knowledge to other tasks. As such, this will help both people using the models and those developing them. With the rise in transfer learning and fine tuning, a dataset such as XTREME will help you understand how to create your own domain specific dataset to tune the model to your specific business requirements. And who knows, maybe we will be streaming a movie on Netflix with Adam Driver fighting the good cause of better deep learning datasets.
About Cathal Horan
Cathal is interested in the intersection of philosophy and technology, and is particularly fascinated by how technologies like deep learning can help augment and improve human decision making. He recently completed an MSc in business analytics. His primary degree is in electrical and electronic engineering, but he also boasts a degree in philosophy and an MPhil in psychoanalytic studies. He currently works at Intercom. Cathal is also a FloydHub AI Writer.
You can follow along with Cathal on Twitter, and also on the Intercom blog.