Found in translation: Building a language translator from scratch with deep learning
Build an English-French language translator from scratch using PyTorch.


Neural networks have won me over.
Why, you ask? It's really quite simple – they’ve allowed me, a fledgling student of artificial intelligence, to develop a language translator from scratch.
And it works.
It really works!
Now, let’s take a moment to consider this achievement.
Languages are extremely complicated. Having learnt a few in my time, I know years of study is the bare minimum for developing fluency.
This complexity is why, for decades, machine translation required teams of domain-specific experts. You can easily imagine the squads of linguistic geniuses, huddled together for warmth, devising intricate sets of rules to transform syntax, grammar, and vocabulary between languages.
But no longer.
Today, neural networks autonomously learn these rules.
And this means that a wee cafe-au-lait drinking computer science student in France, albeit one covered in croissant crumbs, can build an English-French translator from scratch.
And it doesn’t learn in years (like it would take this mere mortal), but days! And yes, again, it works (well, mostly – more on that later). Look, don’t take my word for it — let's instead look at my translator in action:

This was achieved using a database of 2 million sentences, trained over three days on a single 8GB GPU. For anyone familiar with Neural Machine Translation (NMT), this training time might seem short.
That’s because it is.
So, let’s next look a bit more deeply at some of our results. Then, together we’ll explore how NMT has worked until recently. Finally, and most interestingly, we'll dive into the recent model I used that just discards all the previous rules.
How good can a 3-day translator really be? Show me the results
Let’s start with the slightly crude, but still necessary, numerical evaluation of how my translator fared.
On my test set of 3,000 sentences, the translator obtained a BLEU score of 0.39. This score is the benchmark scoring system used in machine translation, and the current best I could find in English to French is around 0.42 (set by some smart folks as Google Brain). So, not bad.
But these are just numbers. Let’s see some actual output.
My first test, of course, is the most important translation for me. Its accuracy will define how successful my social life may be here in France for the next new years.

Excellent. Let’s ramp up the difficulty and see how it deals with a couple more clauses thrown in:

In this case, my translation is actually better than Google’s, which is surprising (they are definitely better overall). Google has changed ‘if so’ to just ‘if’, meaning their response does not quite make sense.
On the other hand, my model has translated ‘if so’ to ‘if this is the case’ (si tel est le cas). This is very exciting. It means the network is not translating literally word for word, but understanding the meaning of terms in context and translating appropriately.
Perhaps more remarkable still is my translator’s grammatical improvisations. The astute linguists among you may have noticed some shortcomings in the English input – namely its lack of commas and question mark.

In my output, we've seen the addition of commas to separate the clauses. Additionally the network has understood this to be a question and added a question mark. That's just awesome.
Finally, my translator has understood the word one in ‘buy you one’ to contextually mean ‘one beer/one of those’ and translated it as such to make sense in French (vous en achetere une).
Clearly, the model has developed a real feel for the form of French language.
Now let's try a more complicated sentence that I've taken from an article that I read today:

Another perfect result. In fact, I would say that mine beats Google again – they translated “way of war” to just “war."
It’s all too good to be true, you must be thinking.
Don't worry. I will now pick another example from the same article which breaks the magic:

Proper nouns and unknown words are the downfall of my implementation of this model. The network only learns meanings of words presented during training. This means unknown words (such as proper nouns) can lead to it crumble a little.
Understanding this weakness, I then combined my British-English linguistic capabilities with a niche knowledge of small English town-names to confound the network entirely:

My translator has fallen to pieces, barely understanding a word of the input, and only correctly translating ‘Tom’ and that he was apparently ravaged.
I realize that sharing this failure may now make it seem that my translator is not quite as good as I boasted. However, these errors only occur in these proper-noun (or obscure word) contexts, and the solution to these problems would not have been complex to deal with if I were to start again. (I explain how to fix this problem in the appendix of this post, so skip straight there if you’re interested).
But, hey, why focus on the downsides? Overall, the results are quite incredible, and I'm quite pleased – so let’s have a look at how it works.
You can also check out the code for my translator on GitHub, where you'll find a button to open up my code in a FloydHub Workspace, which is basically an interactive dev environment built for deep learning. It's easy to attach datasets to your workspace and also kick off model training jobs on FloydHub. I've included a Jupyter notebook in my repo called start_here.ipynb that explains how to use my code and also start a training job to reproduce my results.
Click here if you'd like to train your own transformer while reading this post:

Solving machine translation by using seq2seq
Seq2seq is one of the easier terms to remember in deep learning, standing simply for sequence to sequence. The initial concept was devilishly simple; one network encodes a sequence, and then another decodes it:
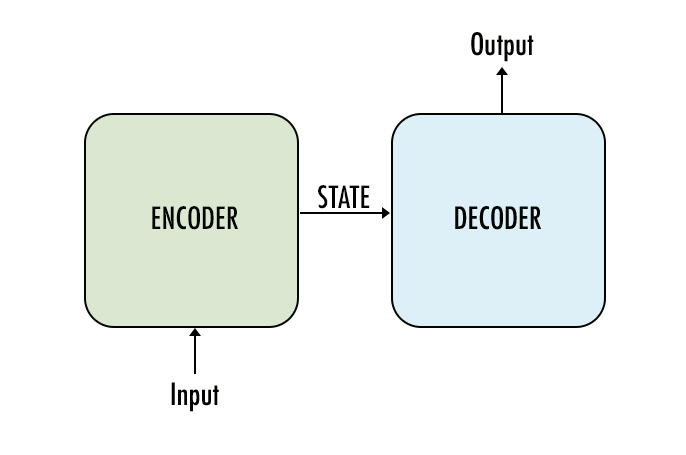
What I initially found most fascinating about this model was the state (see figure above). This is the vector (usually only about 200–500 numbers long) produced by the encoder that tries to capture all of the input sentence’s meaning.
The state is then fed to the decoder, which attempts to translate this meaning into the output language.
The remarkable thing, therefore, about the state is that it seemed almost like a whole new language itself. We are not directly turning English into French any longer, but English into a sort of machine language of its own creation, before then translating (or decoding) that again into French.
It is fascinating to think that so much meaning can be captured in a single array of numbers.
Seq2seq architecture: Encoders and Decoders built using RNNs
Recurrent Neural Networks (RNNs) have predominantly been used to build Encoders/Decoders as they can process variable length inputs (such as text).
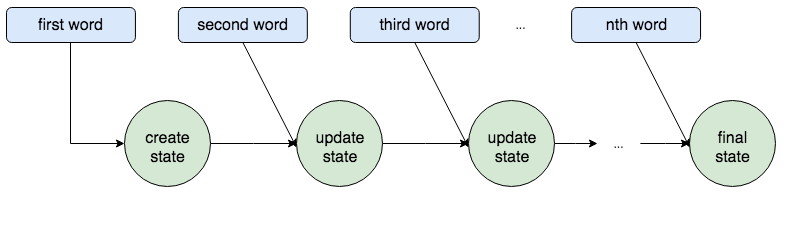
The above diagram reflects a Vanilla RNN, where the state is updated as each word is introduced into the loop. Not only does this mean an RNN can process variable length sentences, but it also means the words are processed in the correct order.
This is important because the positions of words are crucial in sentences. If all the words were simply fed into a network at once, then how might the network determine the context of each word?
A problem with basic RNNs though is they can have problems with recalling early details from a sentence. Elaborate RNN architectures such as LSTMs and GRUs went a great way toward solving these problems and you can read about how they work here. However, before you invest in studying them, I’d urge you to read on.
Attention Attention! Missing a trick with the RNN…
The encoder produces a state and the decoder uses that to make predictions. However, if we look again at how TensorFlow or Pytorch RNN architectures work, we’ll see we are missing a trick here:
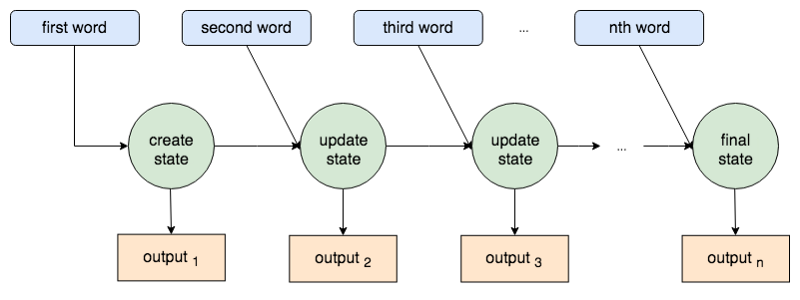
Not only does each word from the input contribute to the state, but each word also produces an output. It wasn’t long before researchers realized that all this extra information could also be passed from the encoder to the decoder, and help boost translation outcomes.
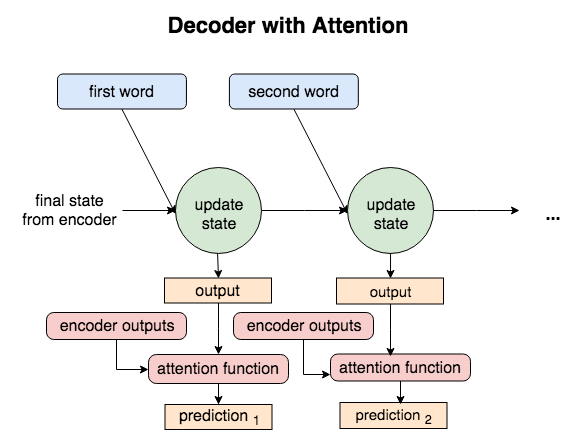
These were called attention-based models, as the decoder still used the state, but also ‘attended’ to all the encoder outputs when making predictions.
Attention models were put forward in papers by Badanhau and Luong. As each new word entered these decoders, all the outputs from the decoder and encoder would be fed to an attention function to improve predictions.
Problems I ran into with this RNN model
After painstakingly studying papers on LSTMs and attention-based GRUs, and implementing my own model, I noticed something that I’d been warned of before:
RNNs are really slow.
This is due to the use of iterative loops to process the data. While the RNN model worked well with my experiments on small datasets, trying to train large ones would’ve required a month on a GPU (and I don’t have that kind of time… or money).
Diving deeper into the research, I discovered an entirely novel seq2seq model that discarded all the rules I’d learnt so far, and this is the one we will explore further.
‘Attention is all you need!’ The Transformer model by Vaswani et al
The authors of this paper brilliantly hypothesized that perhaps the whole ‘state’ thing was unnecessary, that indeed all along the attention could be the most important factor.
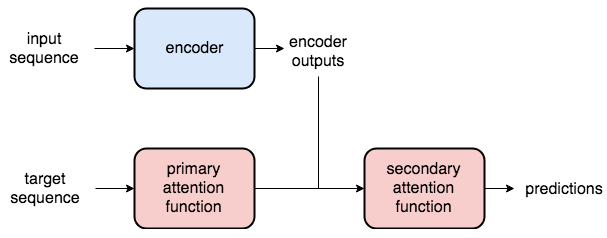
Not only could using only attention (i.e. using just the outputs from each input word) yield state of the art results, but also not needing a state meant we didn’t necessarily need an RNN.
The RNN had been useful in three ways; it produced a state, it could take multiple-length inputs, and it processed the order of the sentence.
Not relying any further on the state, Vaswani et al proposed a novel way of inputting the data using multi-dimensional tensors and positional encodings. This meant no more for-loops. Instead, it takes advantage of highly-optimized linear algebra libraries.
The time saved here could then be spent on deploying more linear layers into the network, leading not only to quicker convergence speeds, but better results. What’s not to love?
But first: obtaining the grand-daddy of all translation data
Before we delve into the model, let’s first discuss the dataset I used.
While there are many small parallel sets of data between French and English, I wanted to create the most robust translator possible and went for the big kahuna: the European Parliament Proceedings Parallel Corpus 1996–2011 (available to download here).

This beast contains 15 years of write-ups from E.U. proceedings, weighing in at 2,007,724 sentences, and 50,265,039 words. You know what they say – it is not the person with the the best algorithm that wins, but the person with the most data. Let's see how that pans out.
How does Neural Machine Translation deal with text?
Now, having reviewed our data, let's discuss how to process words in NMT.
Our English and French sentences must be split into separate words (or tokens) and then assigned unique numbers (indexes). This number will come into play later when we discuss embeddings.
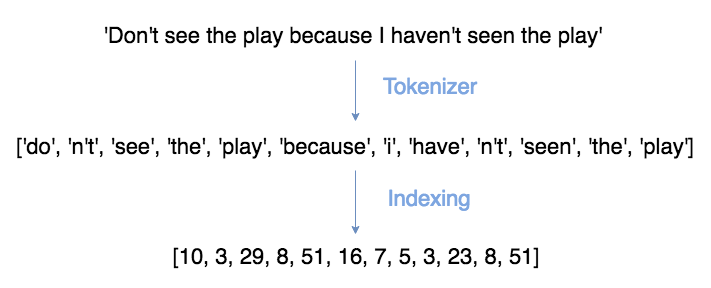
Tokenisation, indexing, and batching can be handled very efficiently using TorchText and Spacy libraries. See my guide on processing NLP data using these tools here.
The Mighty Transformer
*For a complete guide on how to code the Transformer, see my post here. Additionally check my GitHub repo here to run my Transformer on your own datasets.
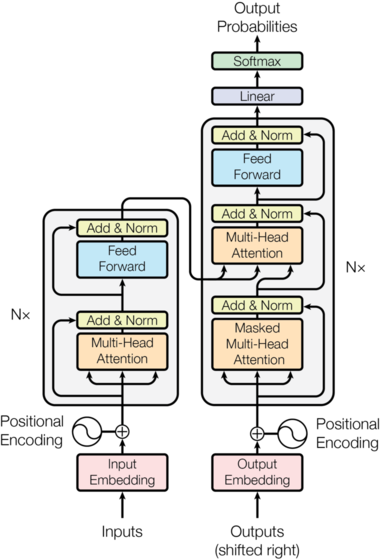
The diagram above shows the overview of my Transformer model. The inputs to the encoder are copies of the English sentence, and the ‘Outputs‘ entering the decoder are copies of the French sentence.
It looks quite intimidating as a whole, but in effect, there are only four processes we need to understand to implement this model:
- Embedding the inputs
- The Positional Encodings
- The Attention Layer
- The Feed-Forward layer
Embedding: What are embeddings and how do we use them?
A key principle in NLP tasks is embedding. Originally, when performing NLP, words would be one hot encoded, and so essentially each word was represented by a single value:

However this is highly inefficient. We are providing huge vectors to our neural network where all but one of each vector’s values are 0!
Additionally, words are highly nuanced and often have more than one meaning in different contexts. A one hot encoding hence provides a far lower amount of information about a word to a network than ideal.

Embeddings address this problem by providing every word a whole array of values that the model can tune. In our model the vector will be of size 512, meaning each word has 512 values that the neural network can tweak to fully interpret its meaning.
And what about preloaded word-embeddings such as GloVe and word2vec? Forget about them. Effective deep learning should be end-to-end. Let’s initialize our word vectors randomly, and get that model to learn all parameters and embeddings itself.
Giving our words context: The positional encoding
In order for the model to make sense of a sentence, it needs to know two things about each word: what does the word mean? And what is its position in the sentence?
The embedding vector for each word will express the meaning, so now we need to input something that tells the network about the word’s position.
Vaswani et al answered this problem by using a sine and cosine function to create a constant matrix of position-specific values.
However, I don’t want to bog this article down with the equations, so let’s just use this diagram to get an intuitive feel of what they did:
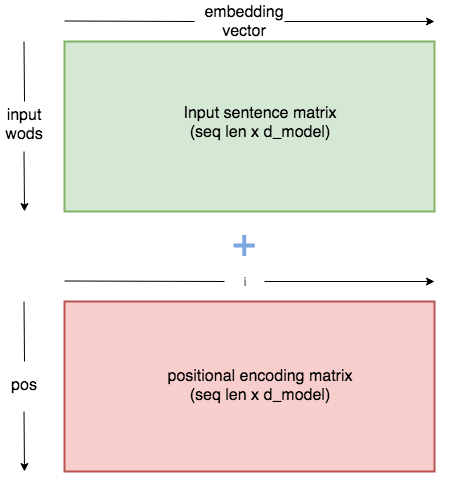
When these position specific values are added to our embedding values, each word embedding is altered in a way specific to its position in the sentence.
The network is hence given information about structure, and it can use this to build understanding of the languages.
The Attention function
Once we have our embedded values (with positional encodings), we can put them through our attention function.
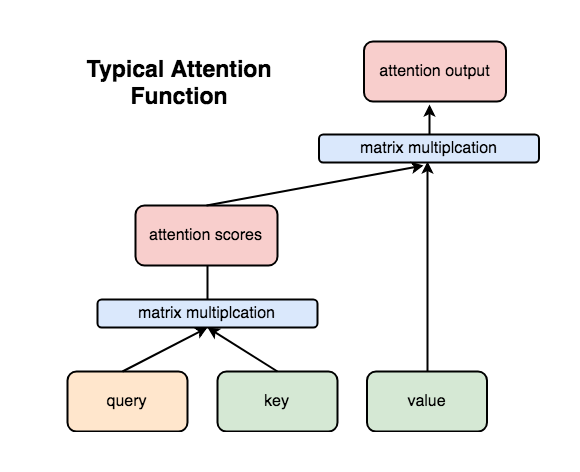
In the decoder, the query will be the encoder outputs and the key and value will be the decoder outputs. A series of matrix multiplications combines these values, and tells the model which words from the input are important for making our next prediction.
Here is a glance into the attention function from the decoder of my trained model, when translating the phrase “let’s look inside the attention function”.
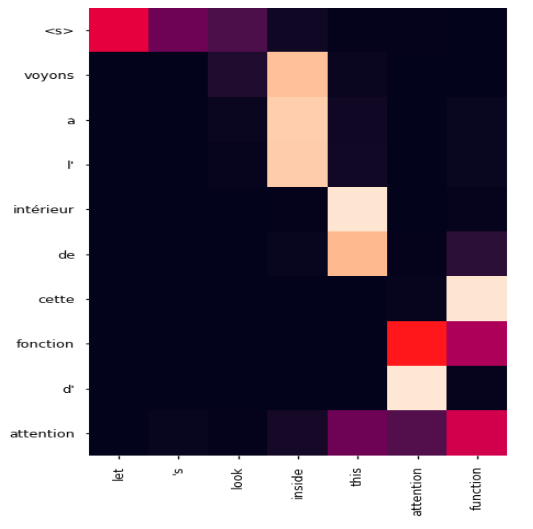
The first word we give the decoder to start translating is the <s> token (s for start). When it receives this we can see it is paying attention to let, ‘s, and look outputs from the encoder, realizing it can translate all those words to voyons.
It then outputs voyons. To predict the next word we can now see it pays attention to the word inside. Attending to inside, it then predicts a and then l’ and finally intérieur. It now pays attention to the next encoder output, translates this, and so on.
Most interestingly we can see that attention function in French is translated as fonction d’attention (it is written the other way round). When we get to this point in the sentence, the model learns to pay attention to function first and then attention. This is frankly astonishing – it has learnt in French the adjective must always come after the noun and we are seeing that in action.
The Feed-Forward Network
Okay, if you’ve understood things so far, give yourself a big pat on the back as we’ve made it to the final layer, and luckily this one’s pretty simple.
The feed-forward network just consists of two linear operations. That’s it.
Here the network can feed on all the information generated by the attention functions and begin deciphering useful patterns and correlations.
Training the model
After training the model for about three days on my 8GB GPU, I ended up converging at a loss of around 1.3 (using a simple cross entropy loss function).
And at this loss value, we got a high-functioning translator, capable of all the results explored in the introduction to this piece.
Let’s again reflect on this achievement.
One readily available dataset from the internet, one paper by Vaswani et al, and three days of training* and there we have it; an almost state of the art French-English translator.
And on that illuminating note, I’ll leave you with a final translation:

*plus three weeks of me smashing my against the wall trying to work out how to code it.
Appendix: tips and tricks
In total, this project took me one month (I’d imagined it would take a few weeks at most…). If you’d like to replicate it or learn more about the code and theory, check out my tutorial on Torchtext and the transformer.
I also learnt many lessons and tips that either helped improve my results, or will serve me well during my next deep learning project.
1. Spend more time researching
Deep learning is such a fast moving field that a lot of the immediate results for web queries can contain outdated models or information.
For example searching seq2seq yields heaps of information about RNNs, yet these models are becoming seemingly obsolete in face of the transformer and even more recently, temporal convolutional networks.
If I’d spent more time researching at the beginning, I could’ve immediately begun building the transformer (or even better this model I only just discovered), and got a quick-training translator straight away.
2. Be organized and store your training logs
I eventually learnt to store training logs (either as text files or figures). There were many times I thought my model wasn’t working (or had become slower) because I was comparing it to the wrong log. I lost countless hours searching for non-existent bugs due to this silly mistake. Platforms like FloydHub solve this problem – FloydHub automatically stores and version controls your training logs, metrics graphs, hyperparameters, and code.
3. Think more about your dataset
While the Europarl dataset is the largest I could find, it is far from perfect. The language used is incredibly formal, and it is missing some everyday words (such as love!) as they would not be used in parliamentary proceedings. Using only this means some simple and colloquial sentences don’t translate well. It would have been better to spend more time searching additional data and adding it to my dataset.
5. Synonym hack
Not having the computing power to handle huge vocabulary sizes, I implemented a synonym hack into my final model. When you enter words to translate my model doesn’t know, it looks them up in a thesaurus and tries to find a term the model does know, and substitutes them.
6. Train on smaller dataset first
Before training on the big dataset, I ran experiments on a smaller set of 155,000 sentences (download link). This way I could find which model and parameters seemed to work best, before investing time and money in training the huge dataset.
7. Beam search
For the best translation results, we should use beam search. I used it for the results shown at the top. This is a good video explaining it, and you can see my code here.
8. Try using byte-pair encodings to solve the open-ended language problem
In order to deal with proper-nouns or new vocabulary encountered by the machines, researchers have implemented word-byte encodings. These split words into sub-words and build the network on this input instead, read more here. Another solution for proper nouns word be slightly more hacky, and involve the neural network assuming words it doesn’t know to be proper nouns. Then it would not attempt to translate them, but repeat them exactly as they are in the output text. This could be achieved by editing how the data is processed.
About Samuel Lynn-Evans
For the last 10 years, Sam has combined his passion for science and languages by teaching life sciences in foreign countries. Seeing the huge potential for ML in scientific progress, he began studying AI at school 42 in Paris, with the aim of applying NLP to biological and medical problems. Sam is also an AI Writer for FloydHub.