When Not to Choose the Best NLP Model
The world of NLP already contains an assortment of pre-trained models and techniques. This article discusses how to best discern which model will work for your goals.


In the book “Deep Survival”, Laurence Gonzales notes that pilots often warn each other against trying to “land the model instead of the plane”. This reminds pilots not to get too obsessed with their expected models of the world and, as a result, ignore the most relevant information right in front of them. Statisticians echo a similar fear when they note that all models are wrong, but some are useful.
We need to have similar vigilance in Natural Language Processing (NLP) now due to the explosion of new model availability. While these models are indeed incredible and do show unparalleled results, they may not be suited for your NLP task or your business. In other words, the best NLP model may not be the best choice.
The best model might not be the most useful

It seems fair to say that in the field of NLP, the last year and a half has seen rapid progress unlike any in recent memory. New models are continuously showing staggering results in a range of validation tasks. We even have models that are so good they are too dangerous to publish.
You might be forgiven for thinking that you can take one of these shiny new models and plug it into your NLP tasks with better results than your current implementation. Why not? The new models can perform well with complex tasks such as inference or question and answering. This seems to indicate that they have some level of language comprehension. As a result, they should improve your particular task, right?.
Unfortunately, like most things in life, this is a little too good to be true. Regardless of how these models are trained, or the range of tasks on which they are trained, they do not appear to learn any form of general semantic comprehension. In other words, the models are not general language models, instead performing well on a broad range of tasks (namely those that they were trained to perform well on).
If these tasks don’t match your business use-case, the model may not be what you need.
To help you discern which models to use for your business, we will look at some of the recent models and compare their performance in a relatively simple and common NLP tasks. We will then look at the results and see what they tell us about the models themselves. The goal is to provide you with a basic framework to more efficiently evaluate future NLP models and their usefulness to your business.
Guidelines for evaluation

The goal here is to find a way to quickly evaluate the newest NLP models. To do this we will use pre-trained models that have been made publicly available. Most new NLP models provide a pre-trained version since they are trained on a massive array of data. Unless you have significant time and resources available, and are sure the model is something you want to invest effort in developing, it would defeat the purpose of the model itself to train it from scratch.
You can use the pre-trained models out of the box, or you can fine-tune them to your own tasks with a much smaller amount of data than they were initially trained on. The problem I have found with this is that it can take time (depending on your available resources or general knowledge of deep learning NLP models) to fine-tune these models, which would involve not only gathering and cleaning your own data but also transforming it into a model's specific format.
At this point, you probably have questions like:
- Hold on! What if the model is unsuited to my task in the first place?
- Is there an easier way to check this before investing any time on things like fine-tuning?
That is what we will try to do here. Let’s use the out-of-the-box, pre-trained models and see what we get and whether this helps us discover which model to choose for further investigation.
Is there an easier way to check this before investing any time on things like fine-tuning
Let’s dive right in!
Before getting into any specific details about the models, let’s first just dive in and do some coding. Don’t worry if you don’t know much about the models for now. The whole point of this is to try and get started quickly and easily by testing some models and then reverse engineering the results to see if they make sense to you and are worth further investigation.
First, let’s choose our models:
- ELMo: This model was published early in 2018 and uses Recurrent Neural Networks (RNNs) in the form of Long Short Term Memory (LSTM) architecture to generate contextualized word embeddings
- USE: The Universal Sentence Encoder (USE) was also published in 2018 and is different from ELMo in that it uses the Transformer architecture and not RNNs. This provides it with the capability to look at more context and thus generate embeddings for entire sentences. You can find an example of how to automate your customer support with the USE, here.
- BERT: BERT is the model that has generated most of the interest in deep learning NLP after its publication near the end of 2018. It uses the transformer architecture in addition to a number of different techniques to train the model, resulting in a model that performs at a SOTA level on a wide range of different tasks.
- XLNet: This is the newest contender to the throne of “Coolest New NLP Model". It uses a different approach than BERT to achieve bidirectional dependencies (i.e. being able to learn context by not just processing input sequentially). It also uses an extension of the transformer architecture known as Transformer XL, which enables longer-term dependencies than the original transformer architecture.
Second, let's choose our task:
- Sentence similarity: There are a number of different tasks we could choose to evaluate our model, but let’s try and keep it simple and use a task that you could apply to a number of different NLP tasks of your own. Trying to find out whether one sentence is similar to another seems like a suitable task to use for our evaluation. Think about it. How many NLP tasks are based on being able to tell if one sentence is similar to another?
- Usage: You can use sentence similarity to identify groups of similar questions or answers. You can use it to see what questions are similar to other questions, as well as to provide suggestions or recommendations to your support staff. It can also be used as part of a chatbot to provide context directly to your customers. It is difficult to think of an NLP task that would not be improved, in some way, by a simple and effective method to identify similar sentences.
The code for the evaluation can be found here.

You can run this on FloydHub. The ELMo and USE models are available on TensorFlow Hub and can be run by simply downloading the models as shown in the code here. The only exception to this is BERT, which is not available in TF Hub. Instead, the BERT as a service code repository is a great resource which makes it easy to get started running a BERT pretrained model. All you need to do is follow the pip installation steps and then run the following cmd to create a server on your local instance. You can then just run the code in the example.
bert-serving-start -model_dir ../uncased_L-24_H-1024_A-16 -num_worker=4
Let's look at some results
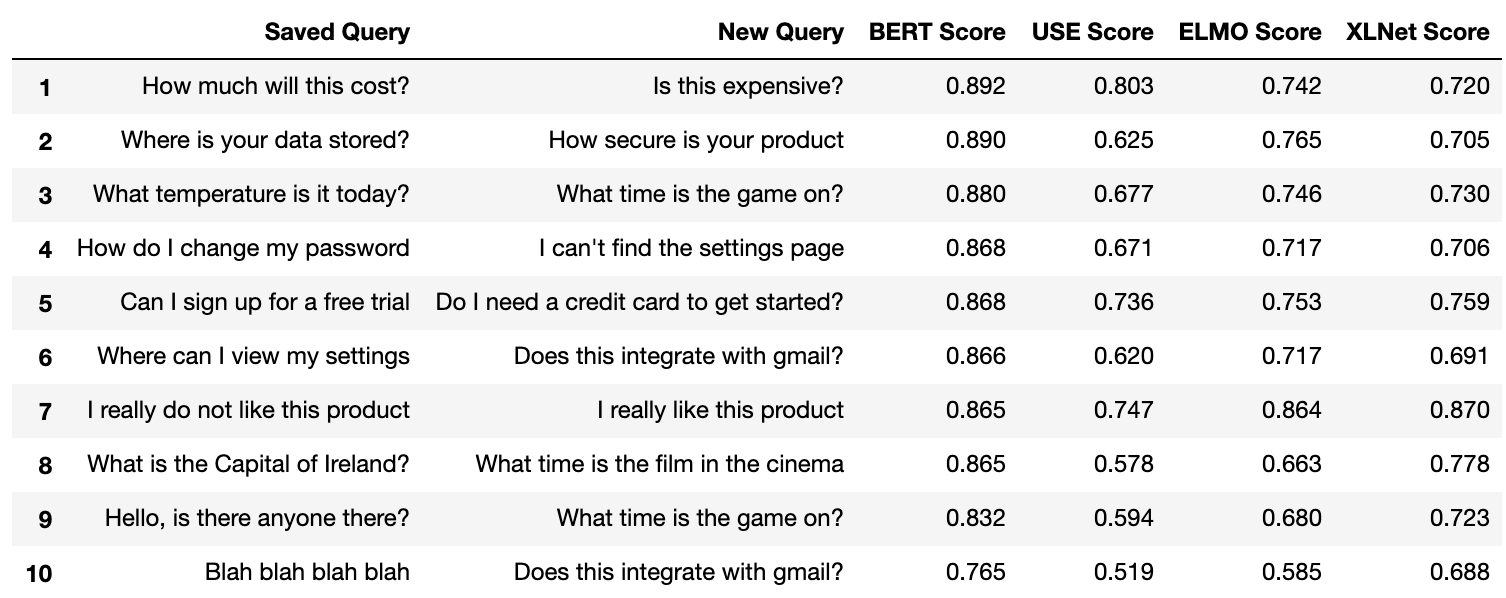
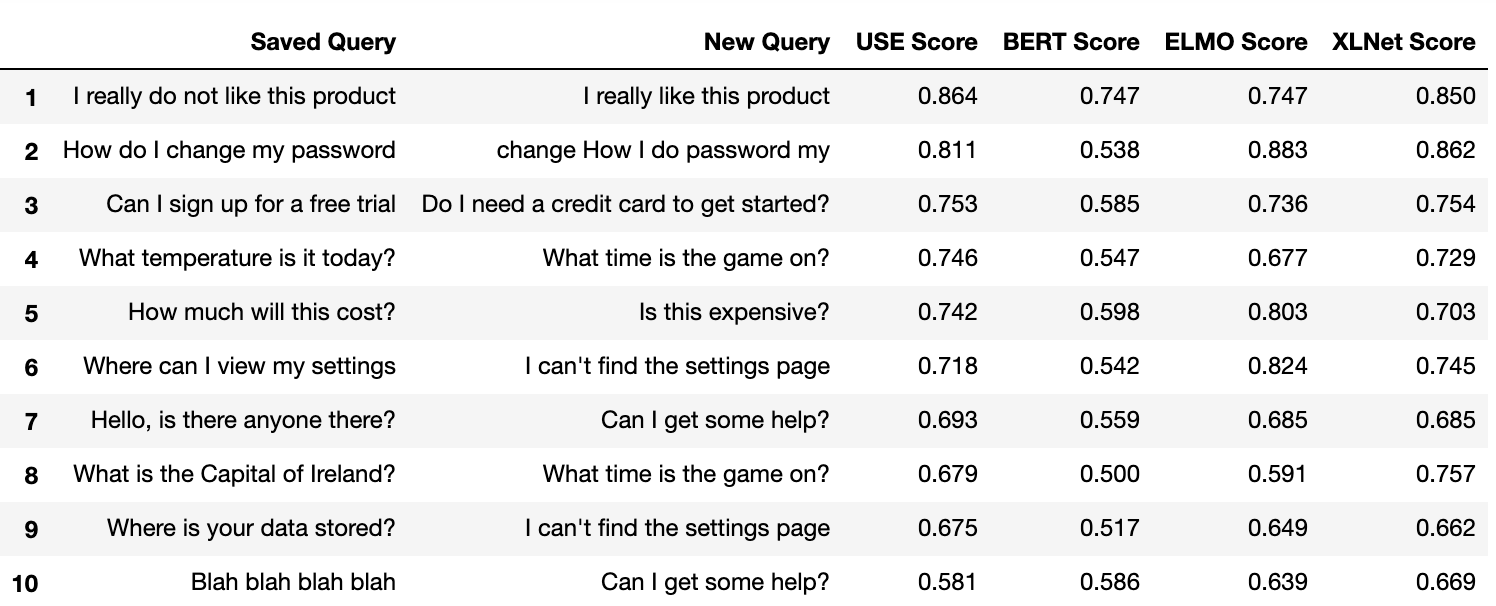
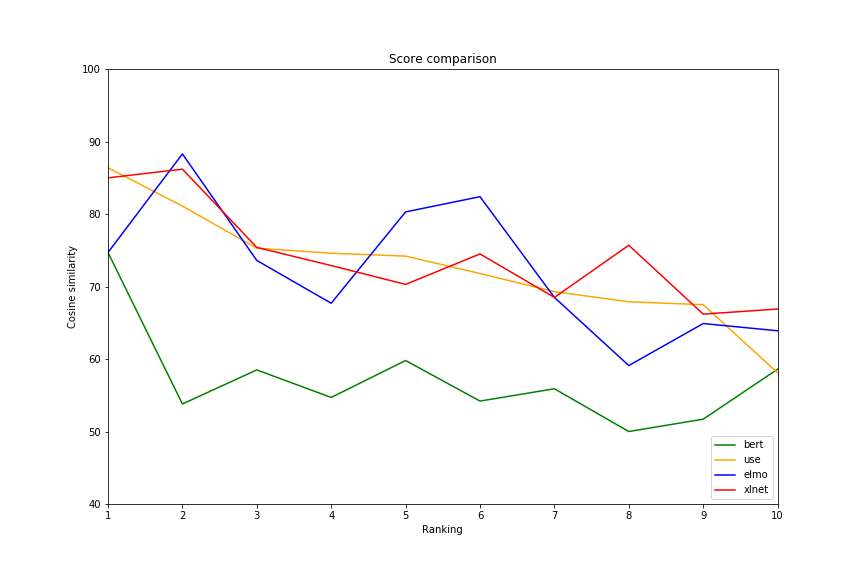
Since BERT is supposed to be one of the best NLP models available, let’s use that as the baseline model. This means we are going to go through each query and generate an embedding for it with the BERT model. After that, we will compare it against every sample’s new query using cosine similarity. Then we will choose the new query which most closely matches the saved query.

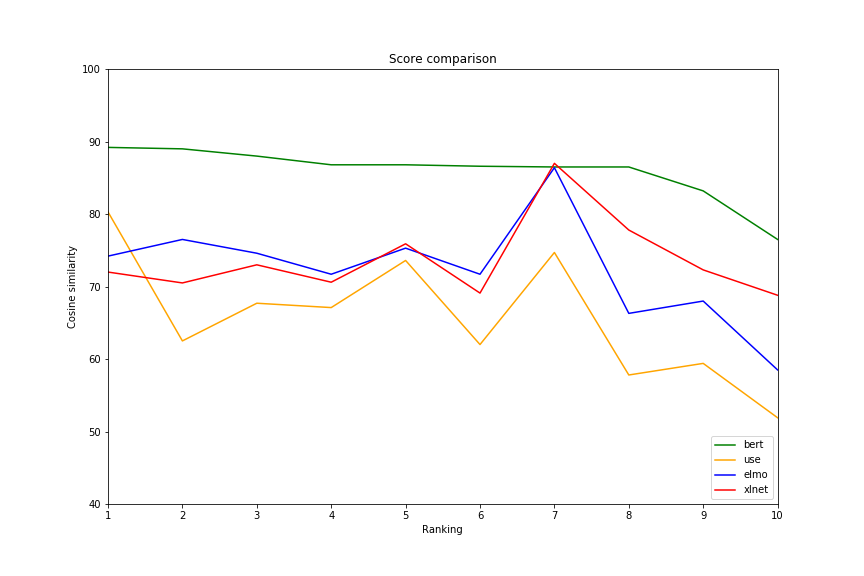
Take a sentence from the saved query column, compare it to all the new queries, and pick the most similar one. This leaves us with ten pairs of sentences. After that, we go through each pair and compare them using both ELMo and USE and then show the cosine similarity score for each pair. We also generate a line graph to show the distribution of similarities for each model to help visualize which has the largest spread. You can see the results below.
How do we interpret the results?
First, take a look at the graph and the table and see if any of it makes sense. Look at the sentences and see whether you think they are similar. Remember that this will be the first strong indicator of how accurate your pre-trained model will be. Just eyeball the data and judge for yourself. What do you see? If you're a nerd like me, you might notice a few things:
- There is not a large difference in the range of values for some of the models. BERT shows very little range, from 0.89 to 0.76, whereas USE shows more, from 0.8 to 0.5. Since some of these sentences are very different we would like to see more separation here.
- Some of these sentences do not match at all. Some of the matches BERT found are not similar, yet they show a high similarity score. This is important since you will need to set some threshold under which you consider any match to be invalid. However, if there are matches above this threshold which return a high score then it is difficult to be confident that a high score ensures a good match.
- There is some semantic matching going on. This is good. There is a match between “How much will this cost” and “is this expensive”. None of these words match directly but we know they are similar sentences, so that is encouraging and a good way to compare how different models consider these matches.
Secondly, it’s important to understand how the comparison works. Since BERT is receiving all the attention at the moment as the premier NLP model (XLNet is challenging for the title now, hence why we have included it here for comparison as well), we used that to initially find the best matching sentences. All of the models generate embeddings for the sentences, which are essentially very large vectors. The vectors are different sizes depending on the models, but the beauty of generating vectors means that it does not matter. We can use the same methods to compare the vectors for each model, in the same way, using cosine similarity.
Once we find the best matching sentences with BERT, we can then see how similar the other models find the relevant matching sentences. This way we can look at the sentences and see which value better represents our own intuition of how similar they are. We can use the graph to see the range of the values and the similarity difference for each model more easily than solely with the table.
Why are the models different?
We won’t get into a detailed examination of the models here. There are a number of great sources which I will provide at the end of the post where you can read about each model in much more detail.
BERT?
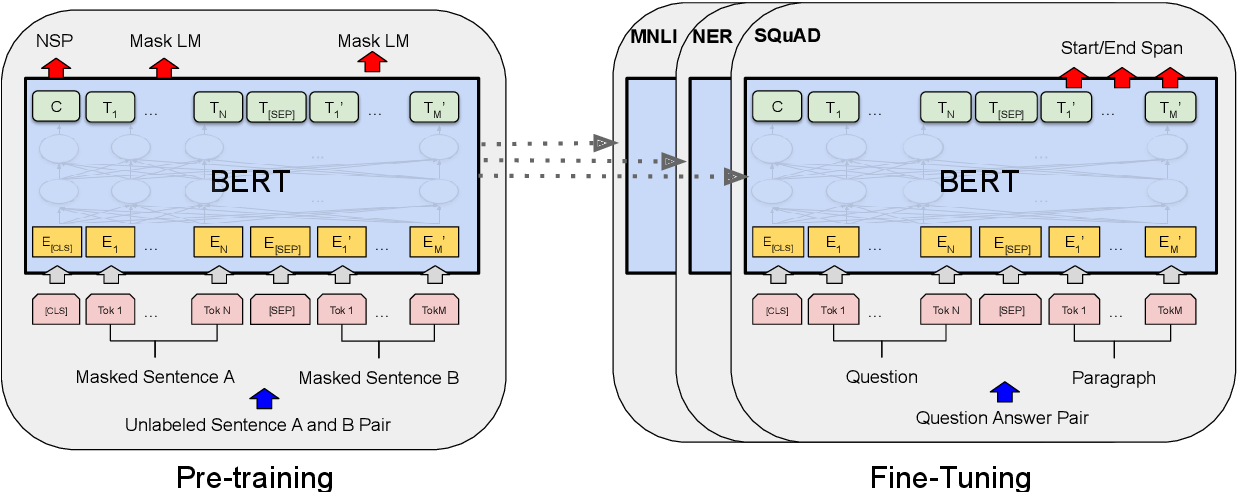
At a high level, without specific fine-tuning, it seems that BERT is not suited to finding similar sentences. The BERT as a service repo, which we use here for testing, notes that sentence similarity results in very high scores. Consequently, they suggest that you use it via a ranking or relative system to show that sentence A is more likely to be similar to sentence B than sentence C. It does not indicate the strength of the match.
However, all is not lost. There are some examples out there of people tackling exactly this issue and using the ranking order of sentence similarity to generate an absolute score. The BERTScore implementation is well worth checking out if you are interested in using it in this way.
BERT is trained on two main tasks:
- Masked language model where some words are hidden (15% of words are masked) and the model is trained to predict the missing words
- Next sentence prediction where the model is trained to identify whether sentence B follows (is related to) sentence A.
None of these tasks is specifically related to identifying whether a sentence is similar to another one. Usually, two sentences which are similar do not follow each other, e.g. “How much does this cost?”, “Is this expensive?”. There will be cases where similar sentences are also follow-on sentences, “it is very expensive”. But we can see from the simple test we performed that these tasks do not enable the model to easily distinguish between similar and dissimilar sentences.
What about USE and ELMo?
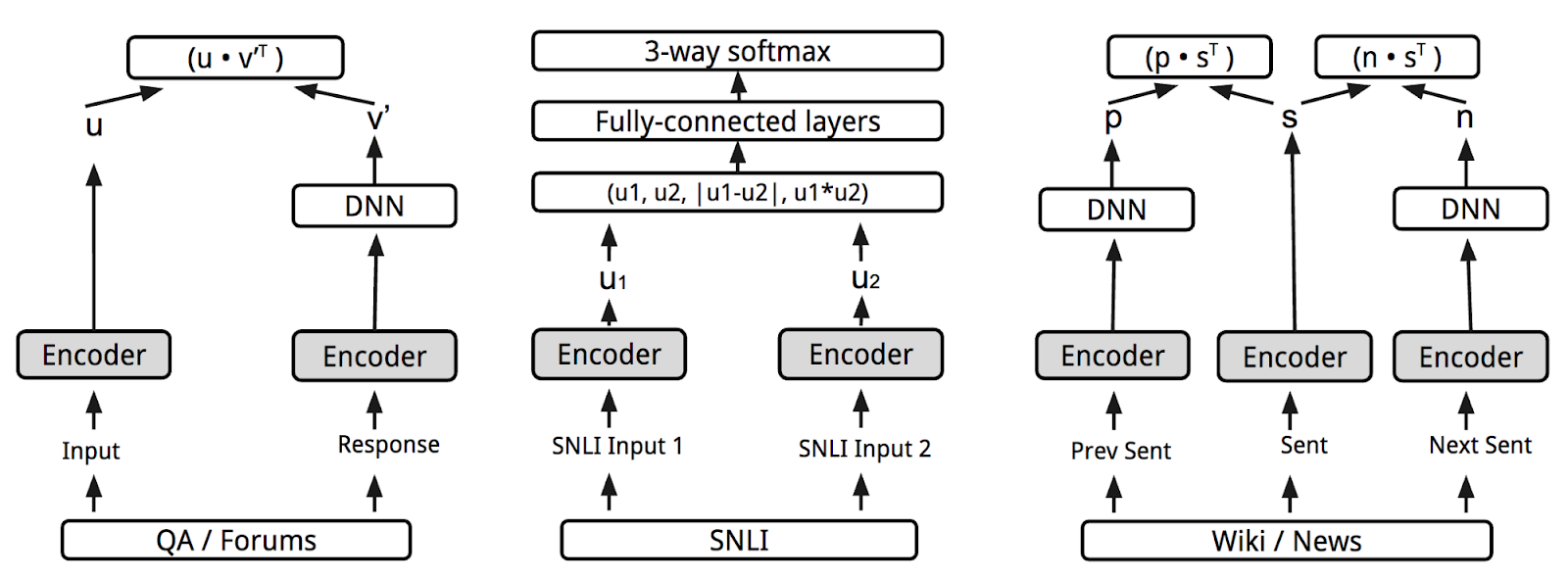
Why are they better suited to these tasks? The USE is trained on a number of tasks but one of the main tasks is to identify the similarity between pairs of sentences. The authors note that the task was to identify “semantic textual similarity (STS) between sentence pairs scored by Pearson correlation with human judgments”. This would help explain why the USE is better at the similarity task.
You can also run the evaluation using the USE to find the best matching scores and then see how the other models compare. These results seem to show that the matching sentences via USE are more relevant. Take a look and see what you think. You can also change the queries and see what results you get and if they match your intuition.
The interesting thing to note here is that the BERT architecture is a far more innovative approach since they designed specific tasks that would enable them to train the model in a bidirectional fashion.
Think about when you read a sentence- you generally get some context from the words around the word you are currently reading. A word is usually not read in complete isolation. BERT is designed so that it can be truly bidirectional and read sentences in both directions without cheating (i.e. knowing the missing word it is about to predict). But our main point still stands; no matter how new or innovative the task is, it still needs to match the basic requirements of the problem you are trying to solve.
And ELMo?
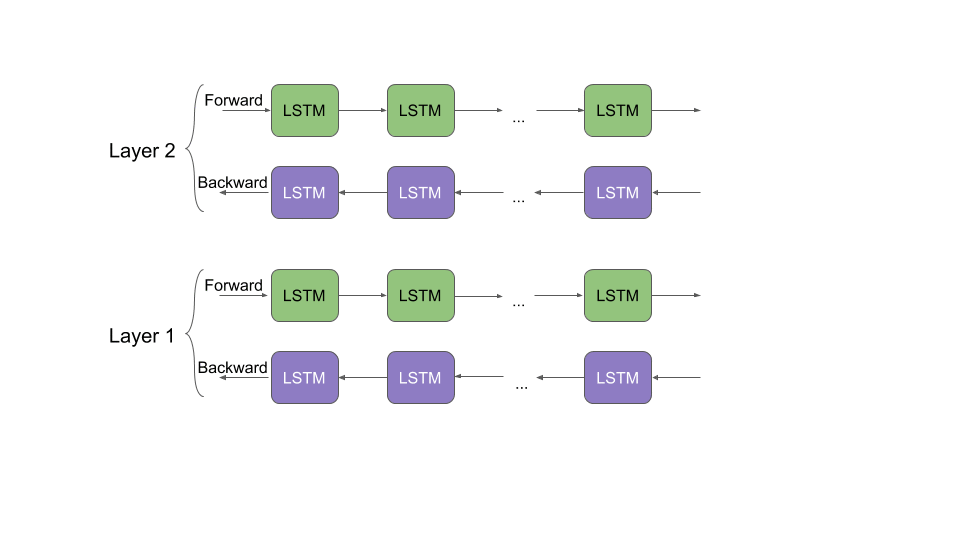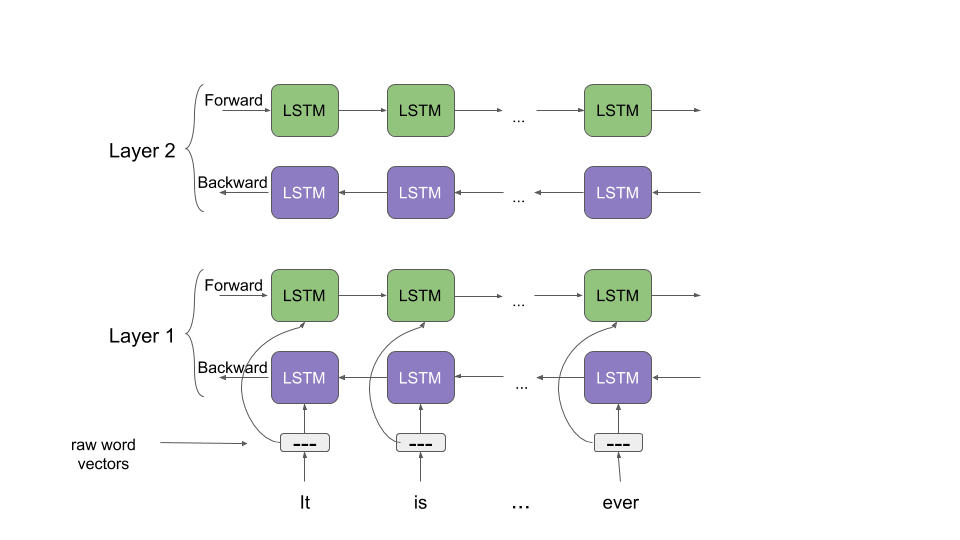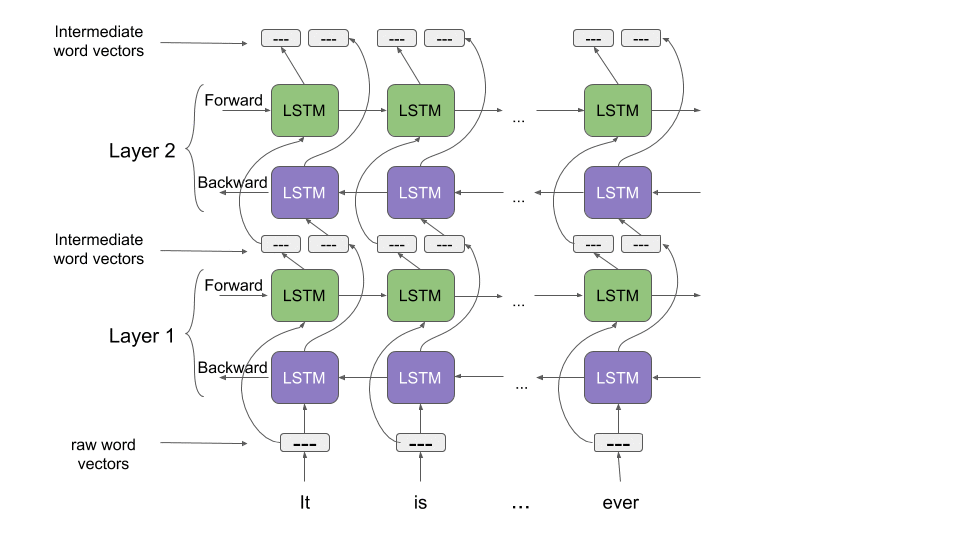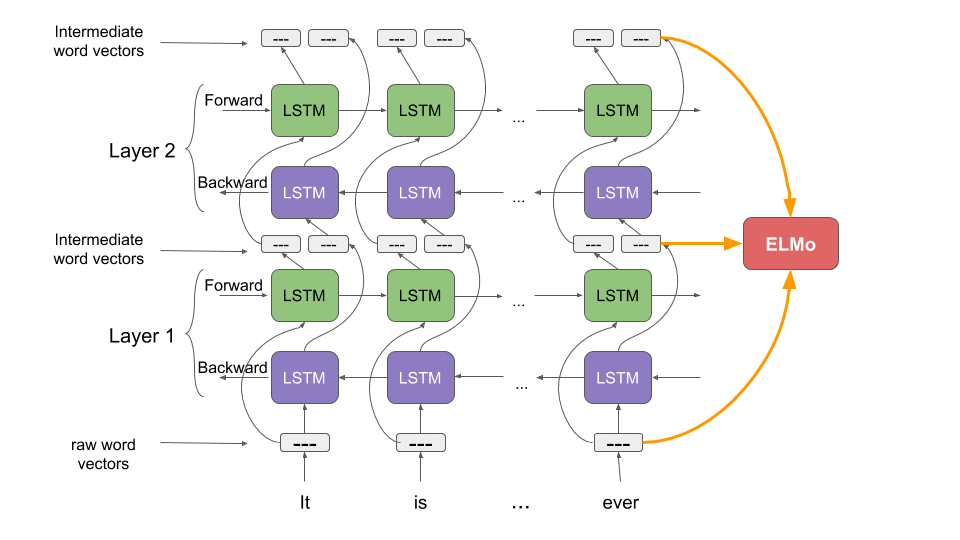
ELMo, unlike BERT and the USE, is not built on the transformer architecture. It uses LSTMs to process sequential text. ELMo is like a bridge between the previous approaches such as GLoVe and Word2Vec and the transformer approaches such as BERT.
Word2Vec approaches generated static vector representations or words which did not take order into account. There was one embedding for each word regardless of how it changed depending on the context, e.g. the word “right”, as in “it is a human right”, “take a right turn”, and “that is the right answer”.
ELMo was trained to generate embeddings of words based on the context they were used in, so it solved both of these problems in one go. ELMo does compare favorably with the USE as a model that could be used for sentence similarity. Since it does not use the transformer architecture, however, it struggles with context-dependency on larger sentences. This is the advantage of any model using the transformer architecture over the RNN/LSTM approach.
The new XLNet model improves on BERT since it uses the transformer XL, an extension of the transformer which enables it to deal with longer sentences than BERT.
Is XLNet not supposed to be the best model now?
Well, yes, it is scoring best according to all the NLP benchmarks they use to compare models. But hopefully, even from this brief post, you will know that this is the wrong question from an applied NLP approach. Instead, you should be saying:
"It's not a matter of which is the BEST model, but whether it is this the BEST choice to solve MY problem."
XLNet evolved from BERTs approach since it uses a more performant extension of the transformer architecture and a different approach to achieve bidirectionally. This means that XLNet should be better for fine-tuning and identifying longer-term dependencies. However, much like BERT, it also was not specifically trained for the task of sentence similarity so it does not seem to perform as well as the USE off the shelf.
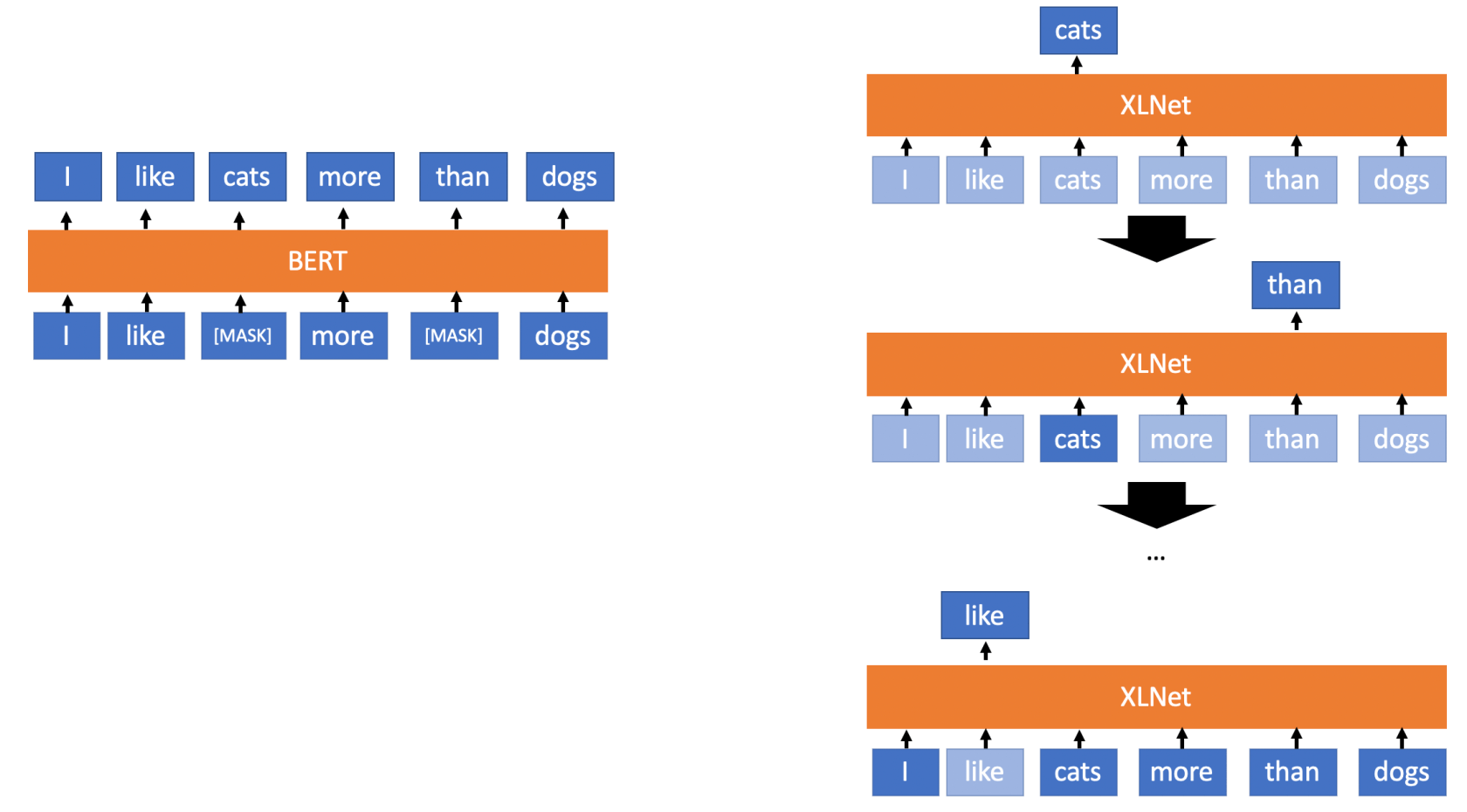
Note that the XLNet model was just released as part of the amazing Transformers repo by @huggingface. The embeddings were generated by following the example here.
🥁🥁🥁 Welcome to "pytorch-transformers", the 👾 library for Natural Language Processing! https://t.co/osNgd1qGy7 pic.twitter.com/PA8iNoWKHX
— Hugging Face (@huggingface) July 16, 2019
So, what's the takeaway?
We started this post by noting that pilots can get too caught up with their own expected models of behavior and lose sight of the task at hand. This can also happen in machine learning when we get carried away with impressive results from new deep learning NLP models. These models are usually trained on specific tasks or specific validation data which is used as a baseline for SOTA performance. Both of these, the tasks and the data, may be very different from the tasks and environment you are working in. By doing some simple testing you can quickly and easily see what models might be able to get you up and running quickly. Here are three takeaways that you should keep in mind:
- What task was the model trained for? If the task is not the same as the one you are trying to solve, it may not be the right choice. You may be able to get it working with a lot of fine-tuning and tweaking, but it may not be worth the effort if your task is very different. E.g. GPT2 received a lot of attention but its main task is to predict text. If you are not trying to predict text then it may not be what you need.
- Have your own simple baseline: When you read the results of the latest NLP models, the results section always claims that the results are SOTA. This is true, but in what tasks and with what data? Can you know from this whether it will be suited to your task? For example, if you are doing topic modeling, have a simple model and some data that you know works and then plug in the new model and compare them. You know how the task works and what a good result looks like, so you should be able to easily eyeball the results.
- Pre-trained models are your friend: Most of the models published now are capable of being fine-tuned, but you should use the pre-trained model to get a quick idea of its suitability. If it is impressive then you will know that it is worth further investment of your time and resources. E.g. In our simple example, I know that the USE is promising and is worthy of further investigation for this particular task.
Resources for further reading and study
- My previous article: Ten trends in Deep learning NLP
- Jay Alammers' illustrated post on the BERT and ELMo is a great place to get a detailed explanation of how these models work.
- This post goes through BERT and shows how it can be used to build a multi-label text classifier.
- If you want to go through the original BERT paper I strongly recommend following the Kaggle reading group video where they go through the paper in detail. This was one of the best resources I used to get my head around some of the core concepts.
- This post shows how to use ELMo to build a semantic search engine, which is a good way to get familiar with the model and how it could benefit your business.
- I found that this article was a good summary of word and sentence embedding advances in 2018. It covers a lot of ground but does go into Universal Sentence Embedding in a helpful way. I've also covered USE in one of my previous articles.
- Again, similar to BERT, the Kaggle reading groups video, which went over the USE paper, was a great resource for understanding the model and how it worked.
- This post provides a good comparison of BERT and XLNet and goes into detail on the XLNet implementation with some good illustrations.
- Best deep learning books & machine learning courses
If you want to cite an example from the post, please cite the resource which that example came from. If you want to cite the post as a whole, you can use the following BibTeX:
@misc{whennottochoosethebestnlpmodelblogpost,
title={When not to choose the best NLP model},
author={Horan, Cathal},
howpublished={\url{https://blog.floydhub.com/when-the-best-nlp-model-is-not-the-best-choice/}},
year={2019}
}
FloydHub Call for AI writers
Want to write amazing articles like Cathal and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community, and with your help we can inspire the next wave of AI. Apply now and join the crew!
About Cathal Horan
Cathal is interested in the intersection of philosophy and technology, and is particularly fascinated by how technologies like deep learning can help augment and improve human decision making. He recently completed an MSc in business analytics. His primary degree is in electrical and electronic engineering, but he also boasts a degree in philosophy and an MPhil in psychoanalytic studies. He currently works at Intercom. Cathal is also a FloydHub AI Writer.
You can follow along with Cathal on Twitter, and also on the Intercom blog.