DIY Data: Web Scraping with Python and BeautifulSoup
Getting sufficient clean, reliable data is one of the hardest parts of data science. Web scraping automates the process of visiting web pages, downloading the data, and cleaning the results. With this technique, we can create new datasets from a large compendium of web pages.


Getting sufficient clean, reliable data is one of the hardest parts of data science. While course projects and online competitions usually provide ready-made datasets, many real-world questions do not have readily available data. Collecting data is often the starting point for most analysis and provides tremendous business value by allowing you to explore previously unanswerable questions. Web scraping is one method of data collection. Web scraping automates the process of visiting web pages, downloading the data, and cleaning the results. With this technique, we can create new datasets from a large compendium of web pages.
This article will cover a project from data collection through exploratory data analysis. Web scraping is difficult to generalize because the code you write depends on the data that you’re seeking and the structure of the website you’re gathering from. However, the approach stays the same. The first step is to determine which links you will need to collect to have a complete scrape. Then, find common characteristics among the pages that will allow you to collect the data with a few functions. Finally, cover any edge cases and clean the data. We will follow this pattern in this article.
Today, we will scrape Hacker News. Specifically, we will gather data from the monthly "Who is Hiring" and "Freelancer? Seeking Freelancer?" threads from April 2011 through June 2019. Hundreds of people per month post opportunities on these threads (it's how I found out about writing for FloydHub). This is a good set for practicing web scraping because we are considering a number of similar, highly structured pages, but there are still complications like extracting parent comments and following "more" links. Our resultant corpus will be fairly small, we will have two csv files with about 100 rows each.
We'll be harvesting every top-level comment from each thread. This will give us the number of jobs posted and the associated descriptions each month. From the freelancing thread, we'll collect information about people looking for work and gigs available, again with the full text of each. Examining the submissions page, we expect that each row in hiring.csv will have over 500 comments and each row in freelance.csv will have over 100 comments. Running wc hiring.csv reveals that it is nearly eight million word corpus, while freelance.csv weighs in at almost one million words. We will use this data to gain an understanding of how the market and platform have evolved over the past eight years.
You could perform "web scraping" by loading every web page, examining it, performing your calculations on an abacus, and then chiseling your results into a stone tablet. However, we have better tools: Python, Beautiful Soup 4, pandas, and Jupyter notebooks. This analysis was run on a Jupyter notebook in a Floydhub workspace on a 2-core Intel Xeon CPU. Try it for yourself with the button below.

Caching is important in web scraping because web requests take a long time. Jupyter notebooks are well-suited to web scraping because splitting the scraping code into cells lets you examine intermediate results without re-running queries. However, if you have to shut down your kernel you will have to perform the scrape again. To avoid this, after collecting the comments, we write them to a CSV file so that we can perform our analysis without re-scraping the data. In this case, we are only making a few hundred requests, so it should take no more than half an hour to run, as hacker news is slow and we do a bit of processing between each request.
Scraping the Data
This is a two-stage scrape. We start by finding the actual pages that we will scrape, then we scrape them. Finding the pages requires navigating through the post history of the user "whoishiring." We start by visiting https://news.ycombinator.com/submitted?id=whoishiring and notice that the posts are paginated. Paginating is the strategy of breaking up a large amount of data, in this case a couple hundred links, over multiple pages for a better user interface and faster load times. To overcome this pagination, we keep an eye out for the "More" link at the bottom of the page, and follow it until we get to the last page, a strategy we will revisit for the posts themselves.
# Define get links function and get all whoishiring user submissions
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
from bs4 import BeautifulSoup
ROOT_URL = "https://news.ycombinator.com/"
http = urllib3.PoolManager()
posts = []
def get_links(url, posts):
req = http.request('GET', ROOT_URL + url)
if req.status != 200:
print("Error:", req.status, "skipping page", url)
return
page = req.data
soup = BeautifulSoup(page, "html.parser")
posts += soup.find_all("tr", {"class": "athing"})
next_url = soup.find("a", {"class": "morelink"})["href"]
return next_url, posts
next_url, posts = get_links("submitted?id=whoishiring", posts)
while next_url:
try:
next_url, posts = get_links(next_url, posts)
except TypeError:
next_url = None
Now that we have links to all of the posts, we have to filter them by title so that we only get "Who is Hiring?" and "Freelancer? Seeking Freelancer?" posts. During this step, we can also tag each post with its month, which is conveniently in parenthesis at the end of each title, otherwise we would have to calculate it from the post age.
# Get links to all Who is Hiring and Seeking Freelancer posts
hiring = []
freelance = []
for post in posts:
title = post.find("a", {"class": "storylink"}).string
link = post.find("a", {"class": "storylink"})["href"]
if "who is hiring?" in title.lower():
month = title.split("(")[1].split(")")[0]
hiring.append({"month": month, "link": link})
elif "freelancer?" in title.lower():
month = title.split("(")[1].split(")")[0]
freelance.append({"month": month, "link": link})
Now that we have two arrays of webpages, we can extract the data from the pages themselves. One important consideration is that we only want top comments, as they are the actual job postings, so we have to examine the structure of a hacker news comment carefully to determine how to tell top comments from child comments. Hacker news is an older website that still uses a table-based layout, nesting several tables to give the desired placement of elements on the page. Within a comment, we have the following structure.
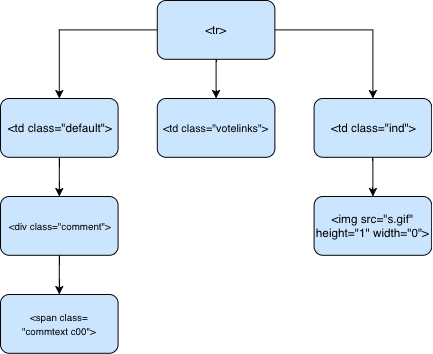
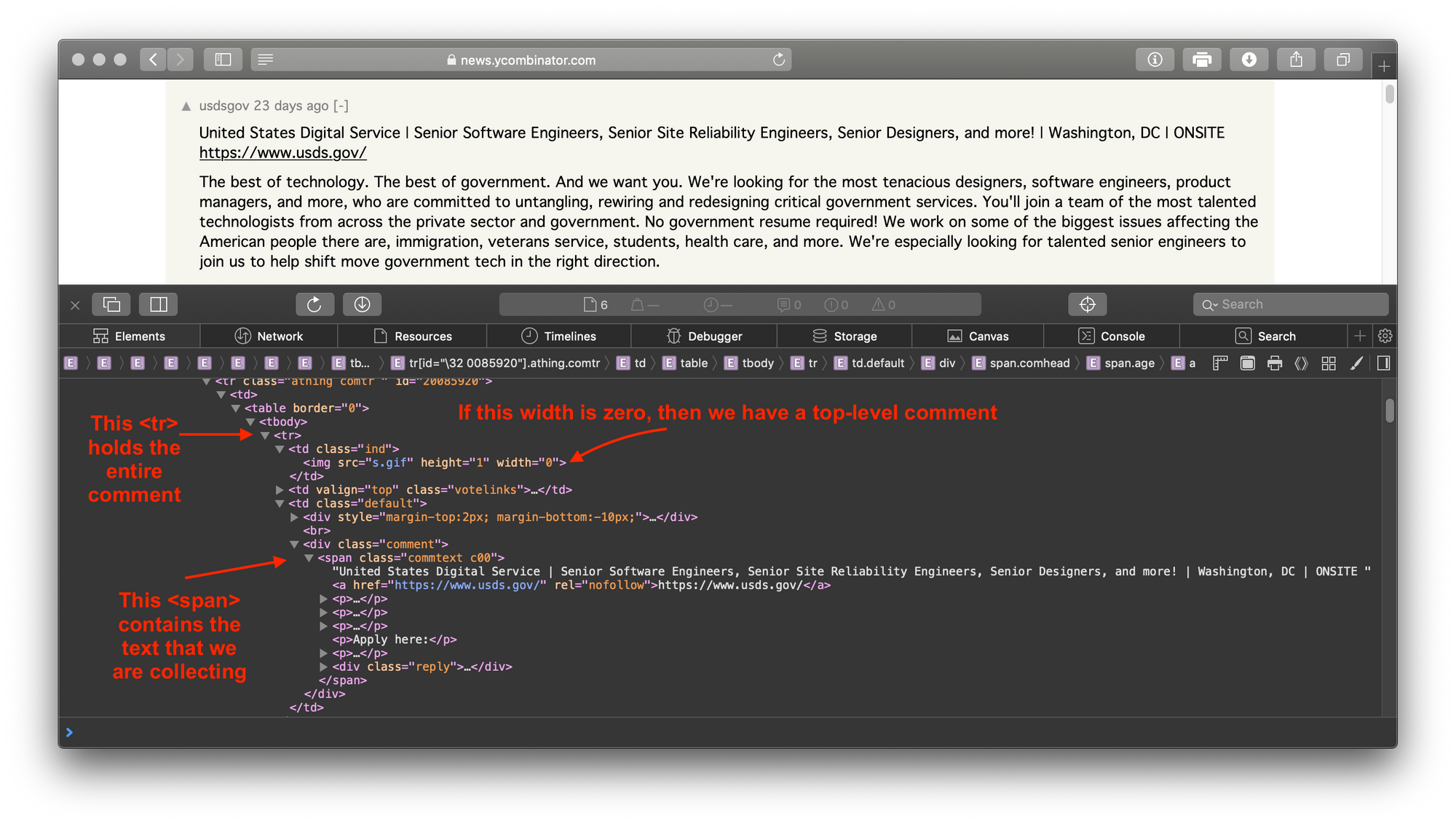
The information that we care about is stored in the span on the bottom left, but the differentiating factor between top and other comments is in the bottom right img. The width of img is zero for the top comment and some non-zero value for other comments to provide visual indent. Thus, we define the is_top() function to filter comments.
# Comment processing functions
def is_top(comment):
td = comment.find_parent("td", {"class": "default"})
ind = td.find_previous_sibling("td", {"class": "ind"})
width = ind.find("img")["width"]
if int(width) == 0:
return True
return False
Thus equipped, we proceed to functions for collecting the comments. Web scraping code needs to be flexible to deal with inconsistency while running for minutes or hours over a wide range of pages. You face a tradeoff between the precision of your results (by being very strict about what you accept) versus the robustness of your scraper (passing instead of failing on unexpected formatting or contents). These functions each have two key pieces of flow control to provide that flexibility. The while(more) loop follows the "More" link that we discussed earlier, allowing us to gather comments from pages of any length. The try block around finding the comment protects us from crashing due to unexpected formatting or contents, simply skipping any information that does not fit our structure.
def read_hiring_post(post):
more = True
data = []
i = 1
while(more):
req = http.request('GET', ROOT_URL + post["link"] + "&p=" + str(i))
if req.status != 200:
print("Error:", req.status, "skipping page", post["month"])
return
page = req.data
soup = BeautifulSoup(page, "html.parser")
comments = soup.find_all("div", {"class": "comment"})
for comment in comments:
if is_top(comment):
try:
data.append(str(comment.find_all("span")[0]))
except:
pass
more = soup.find("a", {"class": "morelink"})
i += 1
return data
def read_freelance_post(post):
req = http.request('GET', ROOT_URL + post["link"])
if req.status != 200:
print("Error:", req.status, "skipping page", post["month"])
return
page = req.data
soup = BeautifulSoup(page, "html.parser")
data = {"seeking_work": [], "seeking_freelancer": []}
comments = soup.find_all("div", {"class": "comment"})
for comment in comments:
if is_top(comment):
try:
text = str(comment.find_all("span")[0])
except:
text = ""
if "seeking freelancer" in text.lower():
data["seeking_freelancer"].append(text)
elif "seeking work" in text.lower():
data["seeking_work"].append(text)
return data
Now, we run these functions. This step also writes the data to a CSV file so that we can use it in the future without re-scraping the pages. Now would be a great time to grab a coffee, as these loops will take upwards of fifteen minutes to run.
Despite the long runtime, this is still a simple example, we are only getting a few hundred pages from a single website. For larger queries or scrapes spanning multiple sites, you’ll want to investigate parallel and asynchronous networking. Our urllib3.PoolManager() is already doing a lot of work to make all of the web requests that we send. One strategy for increasing request rate is to create multiple pools in concurrent processes to manage higher load. However, this does introduce all of the complexity of multithreaded programming to your scraping task.
# Process comments and write to csv
import pandas as pd
for h in hiring:
h["comments"] = read_hiring_post(h)
for f in freelance:
f["comments"] = read_freelance_post(f)
hiring_df = pd.DataFrame(hiring)
hiring_df.to_csv("hiring.csv")
freelance_df = pd.DataFrame(freelance)
freelance_df.to_csv("freelance.csv")
We now have our own formatted data set, something we could not have just downloaded from a repository. We will use this data that we have collected to gain insight into hiring trends on hacker news.
Let’s do an EDA
First, we will examine the growth of the threads over time. In the eight years that "whoishiring" has been posting, we see steady growth on the platform. For the hiring thread, we only have to count the comments for each month to make a bar chart. The coloring on the bar chart is arbitrary, you could make it all one color using the color=myColor argument in sns.barplot(), but I think that the multicolored plot is easier to look at.
# Make a bar chart of number of jobs posted over time
import seaborn as sns
import matplotlib.pyplot as plt
counts = []
months = []
for h in hiring:
counts.append(len(h["comments"]))
months.append(h["month"])
plt.figure(figsize=(16,6))
ax = sns.barplot(months, counts)
ax.set(xlabel='Month', ylabel='Jobs')
plt.xticks(rotation=90)
plt.show()
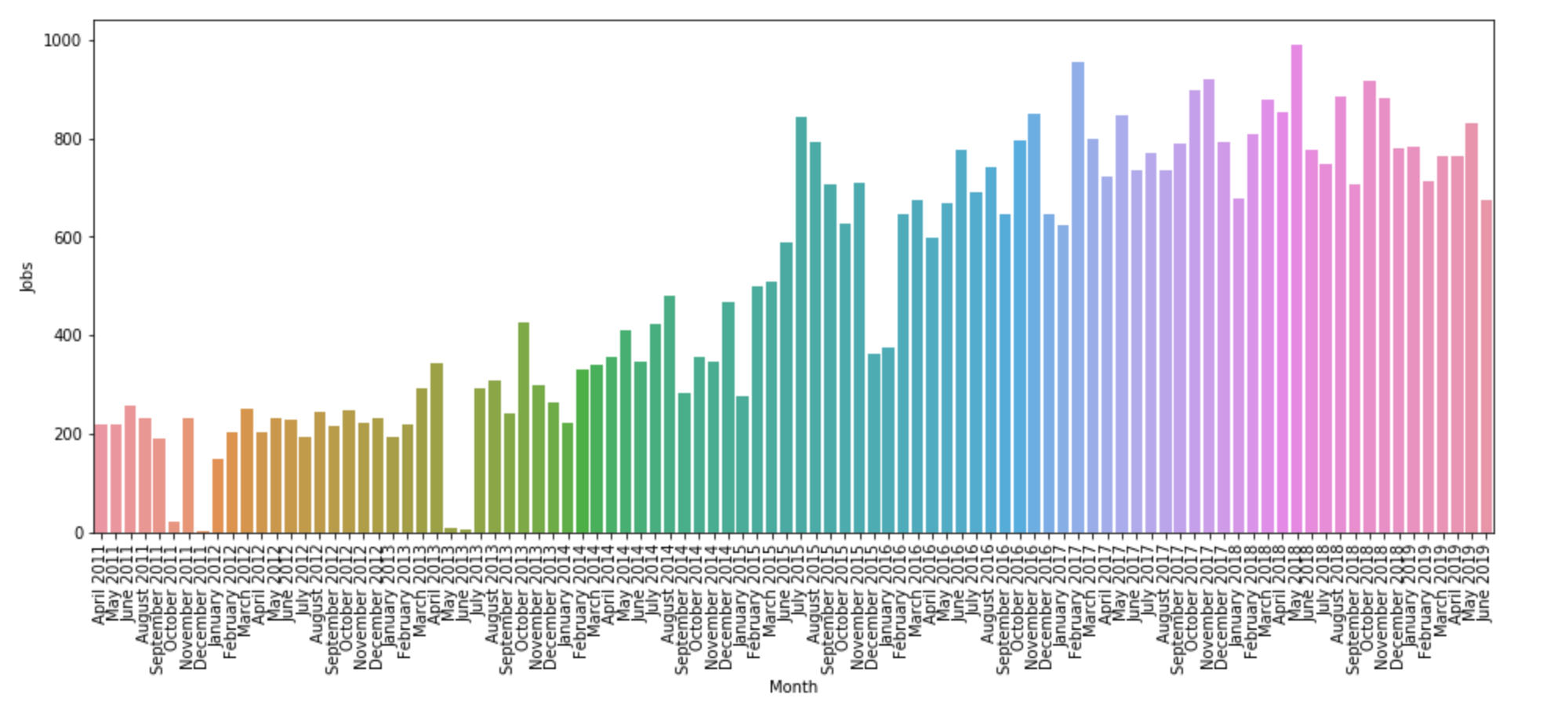
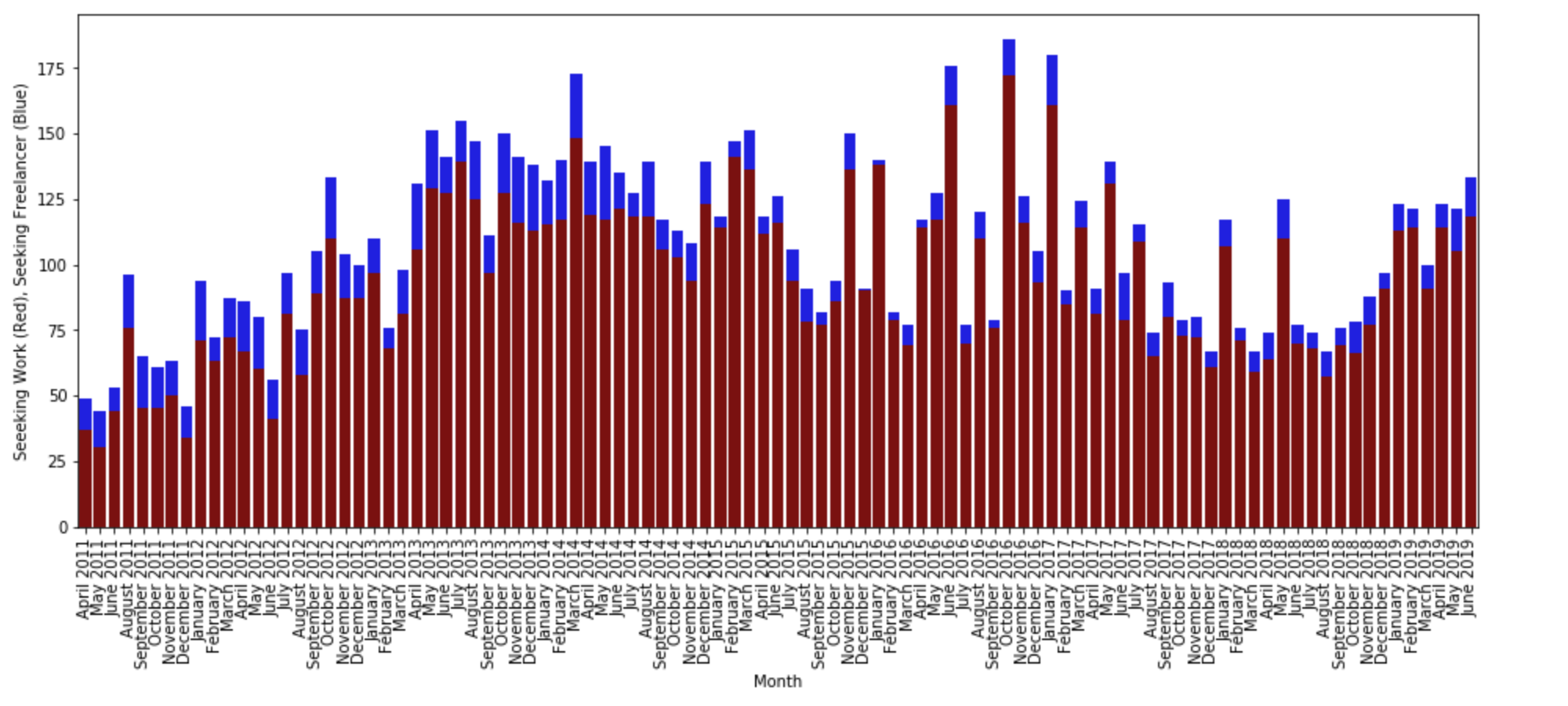
However, for the freelancer post, we want to differentiate between freelancers looking for work and gigs available for freelancers, so we color-code the chart according to the y axis. The chart shows that the people seeking work far exceed the gigs posted, and the thread's growth over time is not as clear as the hiring thread.
# Make a bar chart of number of freelancers and gigs posted over time
%matplotlib inline
total_counts = []
seeking_freelancer_counts = []
seeking_work_counts = []
months = []
for f in freelance:
total_counts.append(len(f["comments"]["seeking_freelancer"]) + len(f["comments"]["seeking_work"]))
seeking_freelancer_counts.append(len(f["comments"]["seeking_freelancer"]))
seeking_work_counts.append(len(f["comments"]["seeking_work"]))
months.append(f["month"])
plt.figure(figsize=(16,6))
sns.barplot(months, total_counts, color="blue")
ax = sns.barplot(months, seeking_work_counts, color="darkred")
ax.set(xlabel='Month', ylabel='Seeeking Work (Red), Seeking Freelancer (Blue)')
plt.xticks(rotation=90)
plt.show()
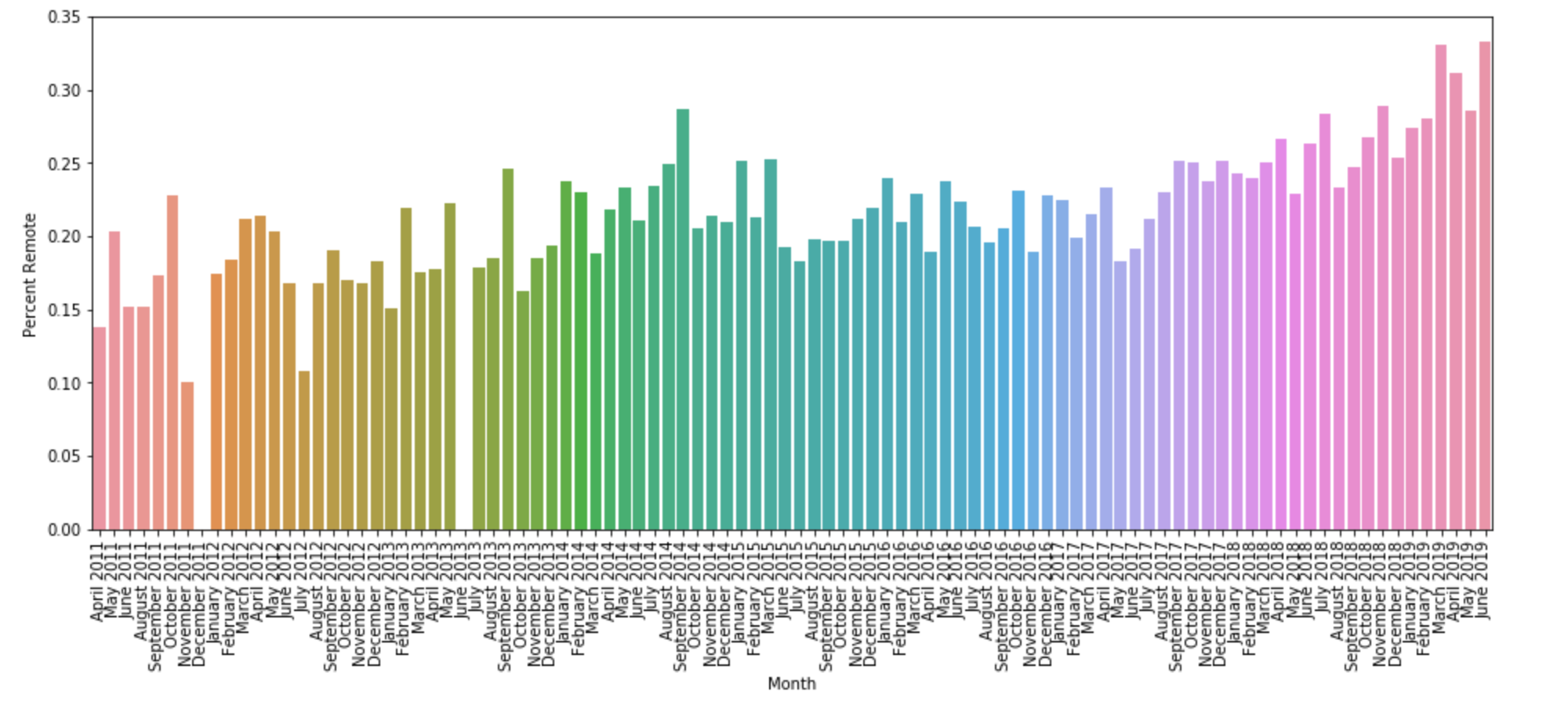
Returning to the jobs thread, we can ask more questions. Remote work has become more popular in the past eight years, does that trend exist in these threads? To investigate, we filter each comment by if it contains the word "remote". This is a rough filter: though it is case insensitive, it flags false positive like "not remote" or even "remote control." However, tagging posts with "REMOTE" to indicate the option of working remotely is standard practice on these threads, so the results should be mostly good. Indeed, the chart shows clear growth in the percent of comments per thread that use the keyword.
# Make a line chart of % of job postings with "remote" keyword
percents = []
months = []
for h in hiring:
remote = [comment for comment in h["comments"] if "remote" in comment.lower()]
percents.append(len(remote) / len(h["comments"]))
months.append(h["month"])
plt.figure(figsize=(16,6))
ax = sns.barplot(months, percents)
ax.set(xlabel='Month', ylabel='Percent Remote')
plt.xticks(rotation=90)
plt.show()
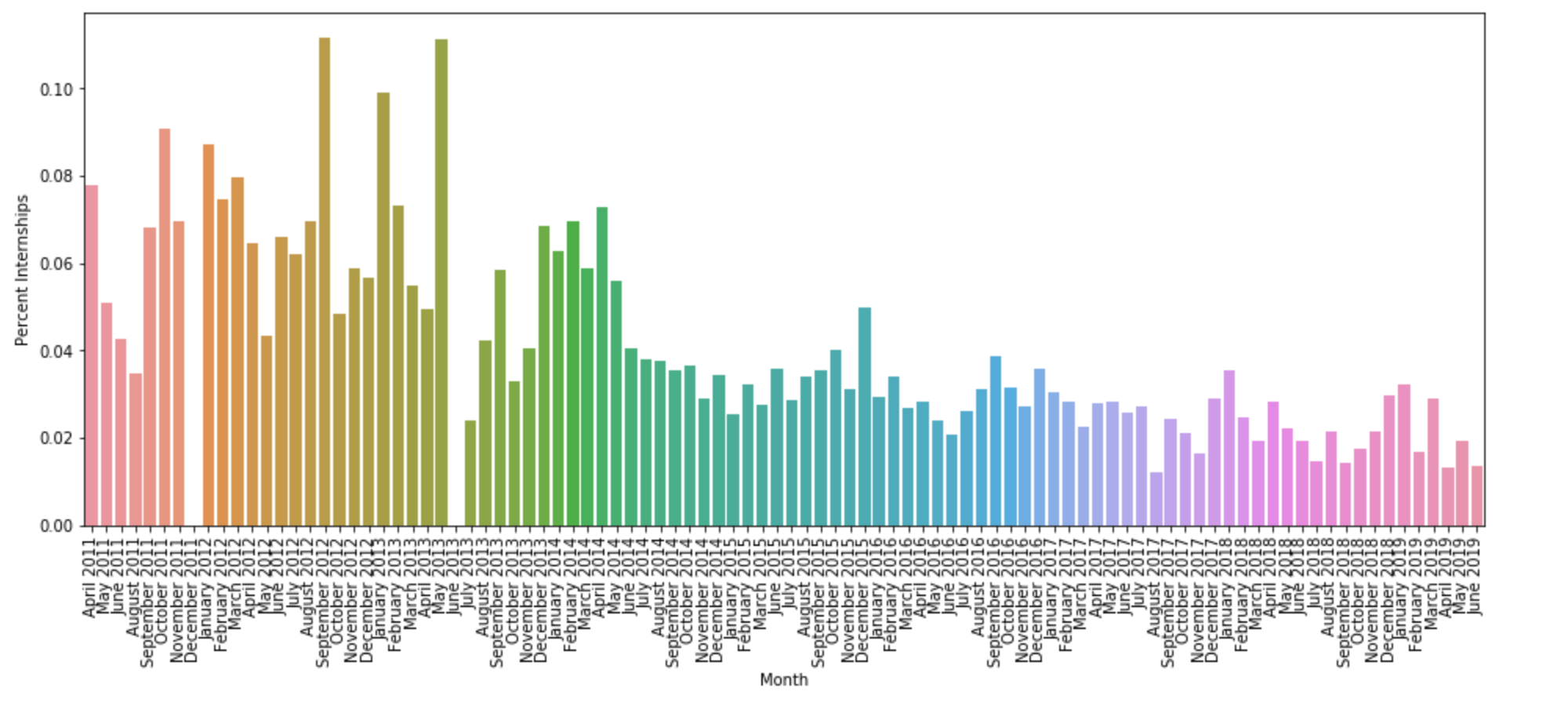
We can perform a similar keyword search for "intern". In this case, "intern" has more common false positives like "internal", so we filter to "intern " and "interns ", both with a space, and accept the increased potential for false negatives. Internship availability has fluctuated over time. I was hoping to identify a clear annual cycle, but the data does not support any such claim.
# Make a line chart of % of job postings with "intern" keyword
percents = []
months = []
for h in hiring:
interns = [comment for comment in h["comments"] if "intern " in comment.lower() or "interns " in comment.lower()]
percents.append(len(interns) / len(h["comments"]))
months.append(h["month"])
plt.figure(figsize=(16,6))
ax = sns.barplot(months, percents)
ax.set(xlabel='Month', ylabel='Percent Internships')
plt.xticks(rotation=90)
plt.show()
Finally, all of this keyword search has me interested in the most common words used in these threads. Remember, the hiring thread is a dataset of almost 8 million words and the freelance thread has nearly 1 million. However, many of these words are going to be common stop words like "the" or "and", as well as leftover html syntax like "<span>" or "<p>". After filtering those out, we can generate word clouds to visualize the frequent words.
# Word clouds of most common words in hiring posts
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk import download
from wordcloud import WordCloud
download('stopwords')
hiring_corpus = []
for h in hiring:
for comment in h["comments"]:
hiring_corpus += word_tokenize(comment)
stop_words = set(stopwords.words('english') + ["<", ">", "span", "class=", "rel=", "href=", "p", "commtext", "c00", "http", "https", "nofollow"])
filtered_hiring_corpus = [w for w in hiring_corpus if not w in stop_words]
plt.figure(figsize=(16,8))
wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(" ".join(filtered_hiring_corpus))
plt.imshow(wordcloud)
plt.show()
freelance_corpus = []
for f in freelance:
for comment in f["comments"]["seeking_freelancer"]:
freelance_corpus += word_tokenize(comment)
for comment in f["comments"]["seeking_work"]:
freelance_corpus += word_tokenize(comment)
filtered_freelance_corpus = [w for w in freelance_corpus if not w in stop_words]
plt.figure(figsize=(16,8))
wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(" ".join(filtered_freelance_corpus))
plt.imshow(wordcloud)
plt.show()
Running this yields the following hiring wordcloud:

And the following freelance word cloud:

Finding out that people want "full-time full-stack software engineers in San Francisco" (big surprise) is just the beginning on what you can do with web scraping, or even this data.
In Conclusion

Web scraping is a powerful tool, and with that comes the responsibility to use it carefully. Before I started this project, I checked Hacker News' site policies to see if they forbade web scraping. The only thing I found was a warning saying that too many requests would lead to an IP ban that I could submit a manual request to have removed. In this case, I knew that I was not requesting very many pages and that the load would be reasonable. One other thing you can check is the site's robots.txt file, which lives at the site root. This file tells search engines how to index the site, and may include a directive like Crawl-delay N asking search engines to wait N seconds between requests. If you are worried about the load your scraping will have, sleep for N seconds between requests to behave like a search engine (understand that this will seriously extend the time that the scrape takes). You also may want to contact the site administrator before performing a much larger scrape than this one. Finally, it is important to consider the ownership and use permissions of the data that you're collecting. In this case, we were scraping comments from a public forum, but just because you can access a given piece of data doesn't necessarily mean that you can use it.
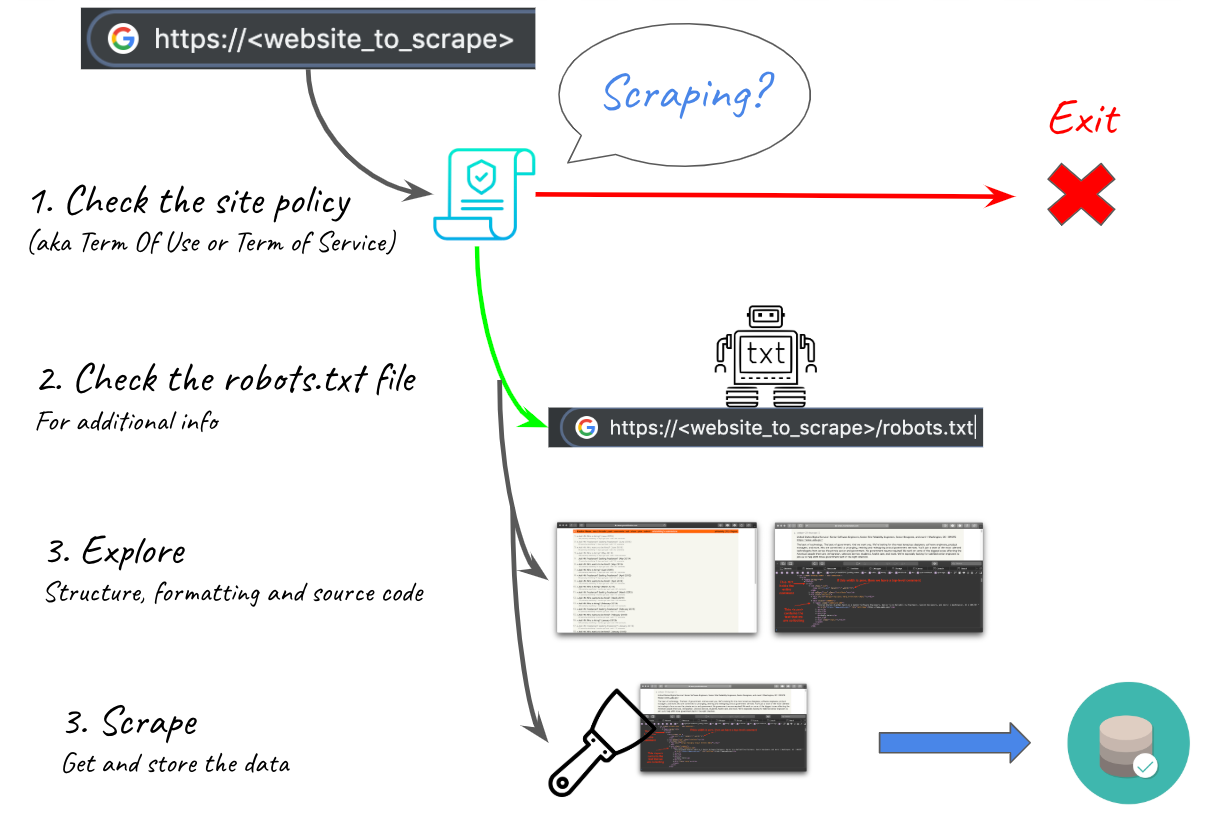
Responsible web scraping is incredibly useful across numerous domains. Despite the significant differences in the code that you have to write to cover different websites, the iterative process of data extraction stays constant and becomes natural after a few projects like this one. You can think of scraping like a build-your-own API for accessing site data and modify your results to use whatever format fits your application. As we've seen, web scraping gives us data that lets us use very simple methods to answer a variety of questions. Web scraping is useful for projects in archiving, mapping, network generation, sentiment analysis, and countless other domains. Go forth and gather.
Resources
- Official Beautiful Soup Documentation
- Chrome Developer Tools
- StackOverflow: Asynchronous Networking in Python
- Web Scraping with Python, 2nd Edition, Ryan Mitchell
- More on robots.txt
FloydHub Call for AI writers
Want to write amazing articles like Philip and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Philip Kiely
Philip Kiely writes code and words. He is the author of Writing for Software Developers (2020). Philip holds a B.A. with honors in Computer Science from Grinnell College. Philip is a FloydHub AI Writer. You can find his work at https://philipkiely.com or you can connect with Philip via LinkedIn and GitHub.