Ten trends in Deep learning NLP
Let's uncover the Top 10 NLP trends of 2019.


2018 was a busy year for deep learning based Natural Language Processing (NLP) research. Prior to this the most high profile incumbent was Word2Vec which was first published in 2013.
In the intervening period there has been a steady momentum of innovation and breakthroughs in terms of what deep learning models were capable of achieving in the field of language modelling (more on this later).
2018, however, may prove to be the year when all of this momentum finally came to fruition with a treasure trove of truly groundbreaking new developments for deep learning approaches to NLP.
There was an especially hectic flurry of activity in the last few months of the year with the BERT (Bidirectional Encoder Representations from Transformers) model being published amid much fanfare. And a new challenger has already emerged in 2019 via the OpenAI GTP-2 model which was “too dangerous” to publish. With all this activity it can be difficult to know what this means from a practical business perspective.
What does it mean for me?
Can this research be applied to everyday applications? Or is the underlying technology still evolving so rapidly that it is not worth investing time developing an approach which may be considered obsolete with the next research paper? Understanding which way NLP research is trending is important if you want to apply the latest approaches in your own business. To help with this here are ten trends for NLP we might expect to see in the next year based on this recent bout of research activity.
Trends in NLP architectures
The first trends we can look at are based on the deep learning neural network architectures which have been at the core of NLP research in recent years. You do not necessarily need to understand these architectures in detail in order to apply them to your business use cases. You do, however, need to know if there is still significant doubt about what architectures can deliver the best results.
If there is no consensus about the best architecture than it is difficult to know what, if any, approach you should employ. You are going to have to invest time and resources to find ways to use these architectures in your business. So you need to know what trends to expect in this area in 2019.
- Previous word embedding approaches are still important
- Recurrent Neural Networks (RNNs) are no longer an NLP standard architecture
- The Transformer will become the dominant NLP deep learning architecture
- Pre-trained models will develop more general linguistic skills
- Transfer learning will play more of a role
- Fine-tuning models will get easier
- BERT will transform the NLP application landscape
- Chatbots will benefit most from this phase on NLP innovation
- Zero shot learning will become more effective
- Discussion about the dangers of AI could start to impact NLP research and applications
1. Previous word embedding approaches are still important
Word2Vec and GLoVE have been around since 2013. With all the new research you might think that these approaches are no longer relevant but you‘d be wrong. Sir Francis Galton formulated the technique for linear regression in the late 1800’s but it is still relevant today as a core part of many statistical approaches.
Similarly, methods like Word2Vec are now a standard part of Python NLP libraries such as spaCy where they are described as “a cornerstone of practical NLP”. If you want to quickly classify common text then word embeddings should do the job.

The limits of approaches such as Word2Vec are also important in helping us understand the future trends of NLP research. They set a benchmark for all future research. So where did they come up short?
- There is only one word embedding per word, i.e. word embeddings can only store one vector for each word. So “bank” only had one meaning for “I lodged money in the bank” and “there is a nice bench on the bank of the river”
- They are difficult to train on large datasets
- You couldn’t fine tune them. To tailor them to your domain you need to train them from scratch
- They are not really a deep neural network. They are trained on a neural network with one hidden layer.
For a detailed dive into the world or word embeddings see our previous FloydHub blog on word and sentence embeddings.
2. Recurrent Neural Networks (RNNs) are no longer an NLP standard architecture
For a long time RNNs have been the underlying architecture for NLP based neural networks. These architectures were true deep learning neural networks and evolved from the benchmark set by earlier innovations such as Word2Vec. One of the most talked about approaches last year was ELMo (Embeddings from Language Models) which used RNNs to provide state of the art embeddings that address most of the shortcomings of previous approaches. As you can see from the diagram below, in contrast to feed forward networks, RNNs allow looping of the hidden layers back to themselves and in this way are capable of accepting variable length sequences inputs. This is why they were so well suited to processing textual input.
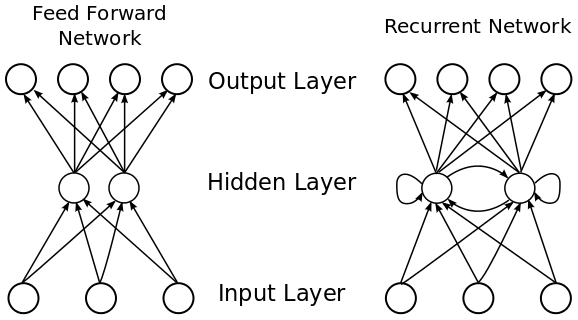
RNNs are important since they provide a way to process data where time and order are important. With text related data, for example, the ordering of words is important. Changing the order or words can alter a sentences meaning or simply render it gibberish. In feed forward networks the hidden layer only has access to the current input. It has no “memory” of any other input that was already processed. An RNN, by contrast, is able to “loop” over its inputs and see what has come before.
As a practical example let’s return to one of our example bank sentences, “I lodged money in the bank”. In a feedforward network we would have no “memory” of the previous words by the time we get to the word “bank”. This makes it difficult to know the context of the sentence or generate a probability for predicting the correct next word. In an RNN, by contrast, we would be able to refer to the previous words in the sentence and then generate a probability for the next word being “bank”.
The full details of RNNs, and Long Short-Term Memory (LSTM), which are an improved type of RNN, are outside the scope of this post. But if you really want a deep dive on the subject there is no better place to start than Christopher Olahs’ brilliant post of the subject.
ELMo was trained on a multilayer RNN and learned word embeddings from context. This enabled it to store more than one vector per word based on the context it was used in. It shipped with a pre-trained model which was trained on a very large dataset and can create context based word embeddings dynamically rather than simply providing look-up tables as with by previous static word embedding approaches.
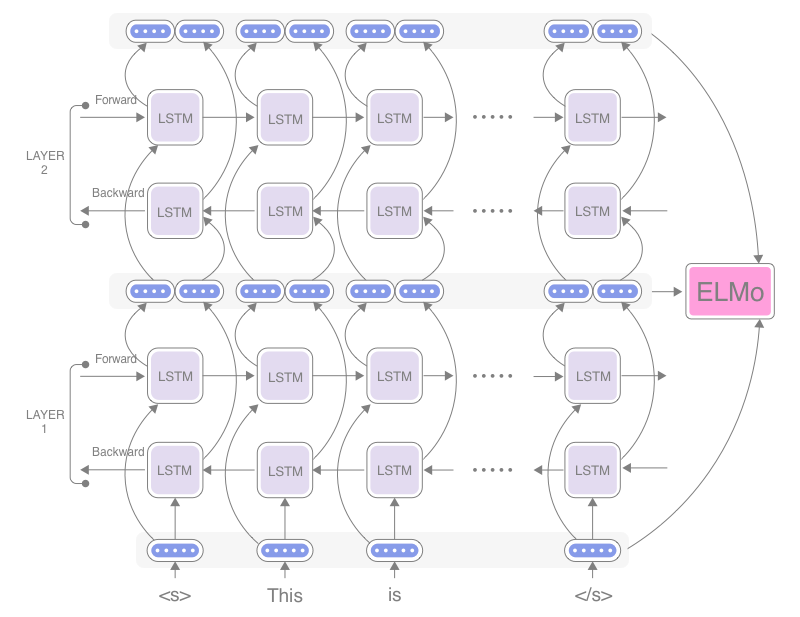
This diagram is an example of a two layer ELMO architecture. The more layers you have the more context you can learn from the input. Lower levels would identify basic grammar and syntactic rules while upper layers extract higher contextual semantics. The other aspect of ELMO which enabled it to be more accurate is that it employed bidirectional language modelling. So instead of simply reading an input from start to finish it also read it from finish to start. This allows it to capture the full context of the words in a sentence. Without this you must assume that either all the context for a particular word occurs before or after the word depending on which direction you are reading it.
It also allowed for fine tuning so it could be tailored to your domain specific data. This led some people to claim that this was NLPs ImageNet moment implying that we are getting closer having core building blocks of generally trained models which can be used for downstream NLP tasks.
So RNN architectures is still pretty cutting edge and well worth further investigation. Up until 2018 it was still the leading architecture for NLP. Some commentators think it is time we dropped RNNs completely, so, either way, it is unlikely they will form the basis of much new research in 2019. Instead, the main architectural trend for deep learning NLP in 2019 will be the transformer.
3. The Transformer will become the dominant NLP deep learning architecture
While ELMo was able to overcome many of the shortcomings of previous word embeddings architectures, such as being limited in how much context it could remember for a piece of text, it still had to process its input sequentially, word by word, or in ELMo’s case, character by character.
As noted earlier, this means a stream of text needs to be fed into the input layer. It is then processed by each hidden layer in sequence. As a result, the architecture must store all the state of the text as it is being processed to be able to understand the context. This makes it difficult to learn longer sequences of text such as sentences or paragraphs and also makes it slower to train.
Ultimately, this limits the size of the datasets it can train on which has a known on effect on the power of any model trained on it. In AI the claim is that “life begins at a billion examples”. The same is true for language modelling. Larger training sets mean your models output will be more accurate. So a bottleneck at the input phase can prove very costly in terms of the amount of accuracy you are able to generate.
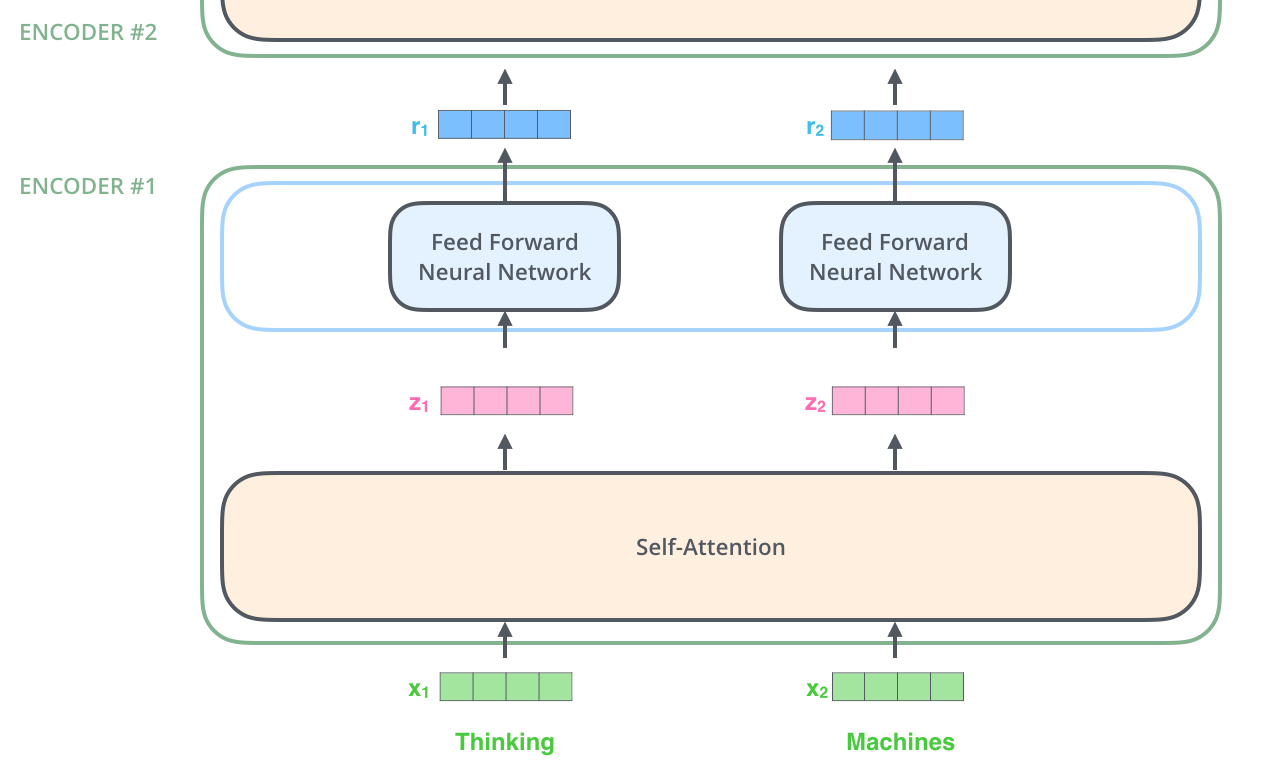
The transformer architecture, which was first published at the end of 2017, addresses this by creating a way to allow parallel inputs. Each word can have a separate embedding and be process simultaneously which greatly improves training times which facilitates training on much larger datasets.
As an example of this we only need to look at one of the early NLP sensations of 2019, Open AI’s GTP-s model. The release the GTP-2 model received much attention since the creators claimed that releasing the full pre-trained model would be dangerous considering the potential for generating “fake” content at scale. Regardless of the merits of their release approach, the model itself was trained on a transformer architecture. As leading AI expert Quoc Le noted, the GTP-2 release showed the power of the vanilla transformer architecture when it is just trained at scale...
Since our work on "Semi-supervised sequence learning", ELMo, BERT and others have shown changes in the algorithm give big accuracy gains. But now given these nice results with a vanilla language model, it's possible that a big factor for gains can come from scale. Exciting! https://t.co/fL4acZE2Cn
— Quoc Le (@quocleix) February 18, 2019
The transformer architecture itself has already taken a step forward in 2019 with the publication of the transformer-XL. This builds on the original transformer and enables longer sequences of input to be processed at one time. This means input sequences do not need to be broken up into arbitrary fixed lengths by instead can follow natural language boundaries such as sentences and paragraphs. This helps understand deeper context over multiple sentences, paragraphs and potentially longer texts such as articles.
In this way the transformer architecture opens of a whole new phase of development for new models. People can now try and train more date or different types of data. Or they can create new and innovative models on top of the transformer. This is why we will see many new approaches to NLP in 2019.
Trends in NLP approaches
The publication of the transformer architecture created a new baseline for NLP deep learning approaches. People could see the potential this new architecture provided and quickly tried to find ways to incorporate it into new more advanced approaches to NLP problems. We can expect these trends to continue into 2019.
4. Pre-trained models will develop more general linguistic skills
Even as late as 2017 pre-trained models were not something which came as standard with most new NLP models. Generally, if a new model was published it was not possible to easily try it out.
If you were lucky the authors may have made some code available in Github. Otherwise, you would need to either create it from scratch or try and find a version online created by someone else. Then a few things happened in 2018 to change this paradigm.
Firstly, the new architectures like the transformer made it easier to train models on datasets which would have previously been considered too large and computationally expensive to learn from. These datasets would not be available to most people to train on and it would likely still be unfeasible for everyone to retrain their own models even if the new architectures made it easier to do so. As a result it meant that people needed to make their pre-trained models available to use off the shelf or to build on and fine tune as required.
And secondly, TensorFlow Hub was launched which was an online repository for reusable machine learning models. This made it easy to quickly try out some advanced NLP model and it also meant that you could download models which were pre-trained on really large datasets. This coincided with the publication of ELMo and the Universal Sentence Encoder (USE). The USE was a new model which used the encoder part of the transformer architecture to create dense vector representations of sentences.

Expect this trend to continue in 2019 with more improvements to the transformer architecture giving rise to more contextually aware NLP models. With innovations in the way these models are trained, and the ability to be trained on more data, expect much more accurate general models to be made available. Their design should enable you to simply plug them into you application so that you can easily switch between the latest models.
As noted earlier, we have already seen amazing progress in the general linguistic ability of models such as GTP-2. The fact that the Open AI team did not publish the full model may seem to counter the general trend of making these pre-trained model available. However, much of the discussion related to this decision was negative. This shows that much of the NLP community has already accepted it as a given that pre-trained models should be available by default. So there is a little bit of wait and see here.
5. Transfer learning will play more of a role
With the new availability of pre-trained models it will become easier to plug them into your own specific task. Previously, doing things like sentiment analysis, text classification or named entity recognition meant you needed to train your own model or use an API to perform the functionality. Not so anymore. For example, check this post out to see how easy it is to create a multi-label classification application using the pre-trained BERT model.
With the availability of more pre-trained models it will be easier to implement your own NLP tasks since you can use the downloaded models as your starting point. This means you can build your own service on top of these models and quickly train it with small amounts of domain specific data. A great example of how to implement these downstream approaches in your own production environment is provided BERT as a Service by @hxiao.
This may shift the focus from the lower level training to more application specific tweaking. Expect more applications to be shipped which contain the base models and the code for tasks such as classification. All you will need to add is your own domain specific data.
This should mean that text cleaning tasks such as stop word removal or tokenization are no longer needed. You will still likely need to split your data into positive and negative samples to perform the high level tuning but expect the absolute amount of data needed to do this to start decreasing rapidly in 2019 with improvements in the general linguistic abilities of the pre-trained models.
6. Fine-tuning models will get easier
Transfer learning will enable firms to use pre-trained models to create applications to perform tasks such as text classifications, sentiment analysis and so on. As we saw in the previous section, this is where we put a layer on top of the pre-trained model and train it to perform an action such as classification.
The result, or the goal, of this approach is the end task itself. Think of industries like healthcare which use pre-trained models for some of the applications described below. Transfer learning will allow things like patient satisfaction to be easily and accurately measured. The output will be a score representing the likelihood the patient is satisfied or not.

In contrast, the output of the original models, the BERTs and the ELMos of the world, is a dense vector representation, or embedding. The embedding captures the general linguistic information from the large and general dataset it was trained on. You can also fine-tune the model to generate an embedding which is more contextually aware of your own closed domain. The output of this form of fine tuning would be another embedding. The goal of fine tuning is thus not to output a measure of sentiment or probability of classification but an embedding that contains domain specific information.
Previously fine-tuning these embeddings was difficult. Models made available on TensorFlow Hub can be used as inputs into applications such as classifiers and could be fine tuned for those specific tasks. But this does not produce embeddings as an output. The USE model, for example, can be fine tuned on your data and output a probability score for classification. It proves difficult to get access to the new embeddings produced as a result of this task.
This means it is difficult to perform your own similarity measures. Having access to the embedding means it is easy to build you own custom similarity models if you want to do something like compare two different sentences and then set your own thresholds for identifying how close they are in terms of semantic meaning.

When BERT was published fine-tuning was a key aspect of its set of features. It was designed with fine tuning in mind so as to make it easy for people to have access to the pure embeddings to create their own use cases. This will become a key part of NLP models in 2019 and beyond. As the innovation in the lower level architecture begins to stabilize we will see more competition and innovation to make it easier for people to fine tune models on their own data.
This could take the form of making fine tuning possible through some form of unsupervised learning or just smaller amounts of domain specific data needed for supervised learning. Either way, domain specific embeddings should become more widespread and this should have an impact on chatbots and conversational interfaces.
Trends in NLP applications
The underlying neural network architectures and the approaches they enable are important when understanding what is possible in 2019. This level of detail, however, may be more relevant to researchers and academics deeply embedded in the field. Most people will instead be interested in how these new technologies can be tweaked, tuned and hacked into cutting edge applications for their own business use cases. We will see significant innovation in applications of these NLP technologies in 2019.
7. BERT will transform the NLP application landscape
BERT BERT BERT BERT …. you will hear alot about BERT in 2019. Although it has only been published since October 2018 it has already taken the NLP world by storm. It combines many of the trends we already mentioned, the transformer architecture, pre-trained models and fine tuning. There have been models such as the USE which combined some of these trends already. But, until the publication of GTP-2, none of them had yet been as powerful or adaptable as BERT. While GPT-2 offers a tantalizing glimpse of what is possible is the field of language modelling, it is BERT that will be the more practical workhorse of new innovation in 2019.
BERT’s pre-trained general model is more powerful than any of its predecessors. It has been able to incorporate a new technique in training NLP models by using a bidirectional approach. This is more akin to the way humans learn meaning from sentences in that we don’t just understand context in one direction. We also project ahead when reading to understand the context of a word.
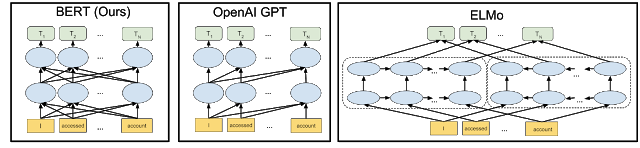
Previous approaches to NLP learning were only able to take one direction into account when processing a sentence. ELMo was the first to try and build up context be parsing a sentence in both directions but it was still limited by the sequential nature of its input. It read from one direction, and then the other, in this way it is described as “shallowly” bidirectional. The transformer architecture, by contrast, allows parallel processing of input sentences so BERT uses this to, in a sense, read all the input words at once. In a way it is non directional since it is not limited by the sequence to sequence approach of RNN based architectures such as ELMo. This means it is capable of learning a much better general linguistic model.

BERT also uses a technique called masking where random words are hidden and the goal or the learning objective is to predict the word given the sentence context. Predicting words in a sentence is a common approach in most language models. The difference with BERT is that masking is needed since it is a training the model bidirectionally. If it did not mask the words then BERT could “cheat” since each word has access to every other word in the input. Masking thus enables the model to be trained bidirectionally.
This, when combined with learning to predict sentence pairs, greatly enhances the power of the BERT pre-trained model to both be directly applied in NLP applications and its ability to be fine-tuned to domain specific tasks.
8. Chatbots will benefit most from this phase on NLP innovation
Until recently chatbots were designed using rule based systems with NLP for pattern matching purposes. A lot of if/then statements combined with text cleaning and NLP parsing to identify pre-defined answers. Open domain chatbots were seen as very difficult to implement since it would require an almost unlimited set of if/then rules to answer any potential question. Closed domain approaches were more attainable since the ruleset was more defined.
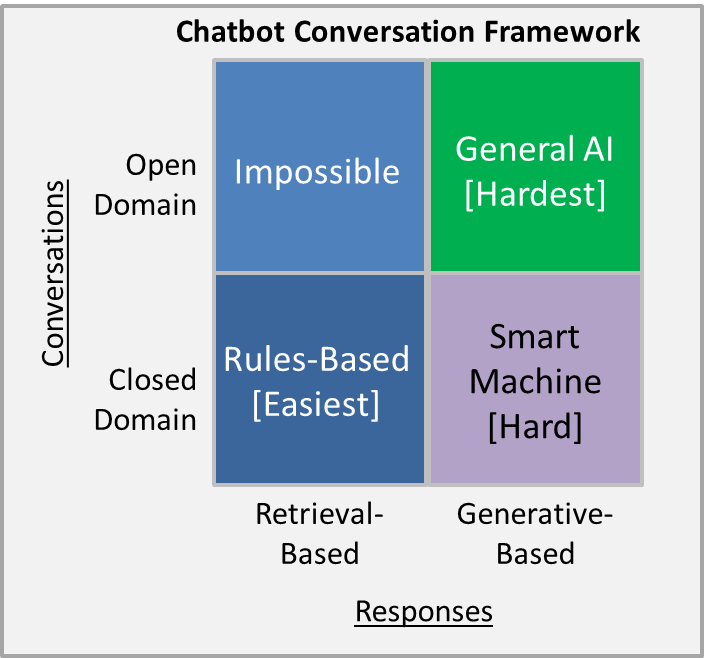
With approaches like GPT-2 and BERT this is no longer the case. Now we see that generally trained models can perform at near human levels in generating responses. While specific closed domain chatbots are more difficult since they need to be fine tuned. In 2019 there will be a shift to create tools for easier fine tuning of models such as BERT on smaller amounts of domain specific data. The big question for the coming year will be whether it will be easier to generate responses or instead use the new NLP models to match incoming customer questions to previously stored or curated response templates. This matching will be driven by finding similarity between questions and responses. The better the fine-tuning the more accurate the model will be at identifying a potentially correct answer to a new customer query.
These approaches will significantly reduce the number of steps you need to take to create a chatbot compared with the rule based approach. It will also open up opportunities to use models such as BERT and ELMo to cluster similar questions or answers based on their embeddings making it easier to find groups of similar questions. The big unknown in the coming year is whether larger datasets for training and innovative approaches to building on the transformer architecture will enable response generation rather than response retrieval. What this space!
9. Zero shot learning will become more effective
Generally language modelling requires you to train your model for the specific task you are trying to solve. So, if you want to translate text from english to french you train your model on lots of french and english text examples. If you want to train it for german then do the same for english to german and so on. Obviously this requires a lot of data since you need it for every language you are trying to solve.
Zero-shot learning is where you train one universal model on either a very large dataset or a very varied dataset. Then you can apply this model to any task. In the translation example you would train one model and use it as a kind of universal translator for other languages. A paper published at the end of 2018 did just this and was able to learn sentence representations for 93 different languages.
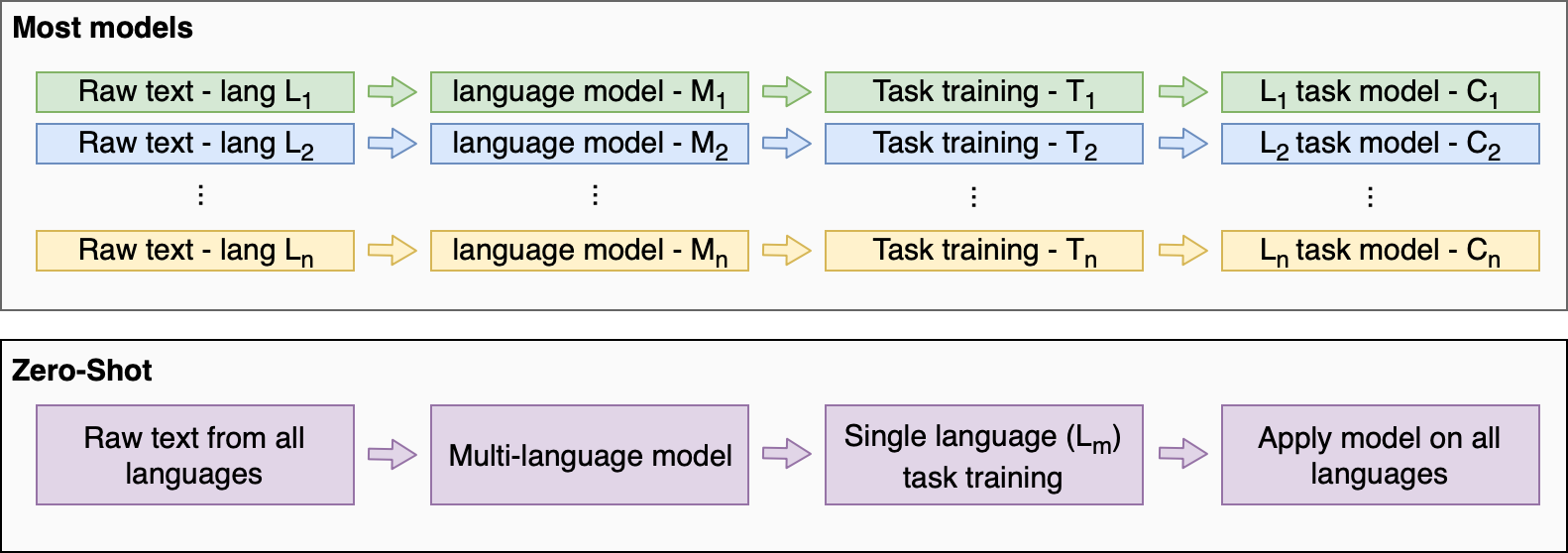
Another recent example of the potential for zero-shot learning is the publication of the GPT-2 model. This was trained on over 8 million different websites. The websites were all in english although some other languages did get through. The model was trained to predict the next word in the sentence.
Yet, despite being trained to only predict the next word in a sequence of text the model is able to perform tasks such as text summation and question and answer type use cases. This despite the fact that it was not trained to explicitly perform these tasks. This shows the potential to “scale it till you break it” with the transformer architecture. If you feed it enough data the model will learn in a general way that can be applied to many different tasks. In 2019 we should see many new applications of NLP models by people since they are no longer required to train every model for every specific task. So we might start to see NLP use cases in areas we did not previously consider. This creates significant opportunity for people that want to find new ways of applying these models.
10. Discussion about the dangers of AI could start to impact NLP research and applications
At the moment the field of deep learning NLP looks like one of the most exciting areas of AI. There is so much going on it is difficult to keep up with the latest trends and developments. This is great and it looks set to continue and grow even faster. The only caveat is that the speed of growth may be so drastic that we need more time to think about the potential impacts.

As we saw with the publication of GTP-2, there are new ethical issues being raised for NLP language modelling type approaches. While ethical considerations are not new for other areas of research it was not something that was top of mind for most of the NLP community. The previous fears about AI were generally associated with “Skynet” superintelligence and consciousness where AI developed its own self awareness. In the next year we will see more discussion about the dangers of unregulated deep learning approaches in NLP.
This is definitely a positive trend since it is difficult to ignore the potential to create fake news or spoof online identities if language modelling continues on its current evolutionary trajectory. We need to consider the implications of publishing pre-trained models such as GPT-2. Check out this article as an example of some of the potential dangerous implications of openly releasing these improved NLP models.
However, these discussions could also have a potentially negative impact. The GPT-2 media attention, and other similar AI related viral media sensations, show that it is easier to sell a story about scary, apocalyptic superintelligent AI rather than a more nuanced narrative of simply better models.
The Open AI people were quick to state that they are not saying they think it can be used for nefarious means but more that they are not sure that it could not be used in this way. It is important to note that difference. Open AI are saying there is some uncertainty about how it could be used so they want to take a breath and try to better understand the implication before releasing it. They are not saying it is so powerful they think it can definitely be weaponized.
This could all potentially lead to researcher not releasing their models and trying to prevent full disclosure of their findings. This could limit access to a few privileged state and corporate actors which ultimately is very damaging for the democratizing potential for deep learning NLP. Let’s hope this is one trend that does not come true in 2019.
Do you model for living? 👩💻 🤖 Be part of a ML/DL user research study and get a cool AI t-shirt every month 💥
We are looking for full-time data scientists for a ML/DL user study. You'll be participating in a calibrated user research experiment for 45 minutes. The study will be done over a video call. We've got plenty of funny tees that you can show-off to your teammates. We'll ship you a different one every month for a year!
Click here to learn more.
FloydHub Call for AI writers
Want to write amazing articles like Cathal and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Cathal Horan
Cathal is interested in the intersection of philosophy and technology, and is particularly fascinated by how technologies like deep learning can help augment and improve human decision making. He recently completed an MSc in business analytics. His primary degree is in electrical and electronic engineering, but he also boasts a degree in philosophy and an MPhil in psychoanalytic studies. He currently works at Intercom. Cathal is also a FloydHub AI Writer.
You can follow along with Cathal on Twitter, and also on the Intercom blog.