Ten Techniques Learned From fast.ai
Right now, Jeremy Howard – the co-founder of fast.ai – currently holds the 105th highest score for the plant seedling classification contest on Kaggle, but he's dropping fast. Why? His own students are beating him. And their names can now be found across the tops of leaderboards all over Kaggle.


Right now, Jeremy Howard – the co-founder of fast.ai – currently holds the 105th highest score for the plant seedling classification contest on Kaggle, but he's dropping fast. Why? His own students are beating him. And their names can now be found across the tops of leaderboards all over Kaggle.

Please don't read this article describing how to beat me in Kaggle competitions. https://t.co/c2kOx97E6C
— Jeremy Howard (@jeremyphoward) August 1, 2018
So what are these secrets that are allowing novices to implement world-class algorithms in mere weeks, leaving behind experienced deep learning practitioners in their GPU-powered wake? Allow me to tell you in ten simple steps.
Read on if you're already practicing deep learning and want to quickly get an overview of the powerful techniques that fast.ai uses in their courses. Read on if you've already completed fast.ai and want to recap some of what you were supposed to have already learned. Read on if you're flirting with the idea of studying deep learning, and would like to see how the field is evolving and what fast.ai can offer beginners.
Now, before we begin, you should know that you'll need access to GPUs to run fast.ai content effectively. For my fast.ai projects, I've been using FloydHub. After much experimentation and research with other cloud-based solutions, I've found FloydHub is the best and easiest way to train deep learning models on cloud GPUs. I love being able to easily keep track of my experiments in Projects on FloydHub, making it especially easy to visualize and filter which models are performing best. They also have the simplest solution for managing (and automatically versioning) your datasets, which you'll learn is going to be super valuable down the road in any DL project.
Okay, let's get started.
1. Use the Fast.ai library
from fast.ai import *
The fast.ai library is not only a toolkit to get newbies quickly implementing deep learning, but a powerful and convenient source of current best practices. Each time the fast.ai team (and their network of AI researchers & collaborators) finds a particularly interesting paper, they test it out on a variety of datasets and work out how to tune it. If they are successful, it gets implemented in the library, and the technology can be quickly accessed by its users.
The result is a powerful toolbox, including quick access to best-current practices such as stochastic gradient descent with restarts, differential learning rates, and test-time augmentation (not to mention many more).
Each of these techniques will be described below, and we will show how you can rapidly implement them using the fast.ai library. The library is built upon PyTorch, and you can use them together quite fluidly. To get going with the library on FloydHub, check out their 2-min installation.
2. Don’t use one learning rate, use many
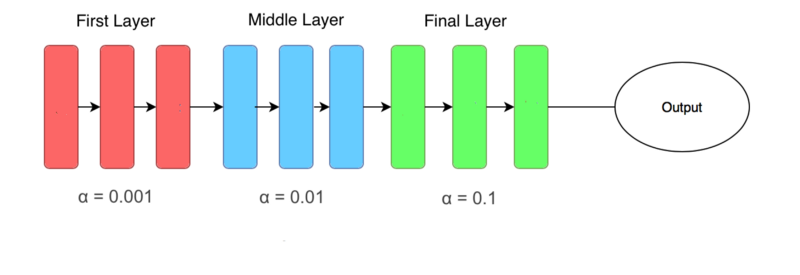
Differential Learning rates mean higher layers change more than deeper layers during training. Building deep learning models on top of pre-existing architectures is a proven method to generate much better results in computer vision tasks.
Most of these architectures (i.e. Resnet, VGG, inception…) are trained on ImageNet, and depending on the similarity of your data to the images on ImageNet, these weights will need to be altered more or less greatly. When it comes to modifying these weights, the last layers of the model will often need the most changing, while deeper levels that are already well trained to detecting basic features (such as edges and outlines) will need less.
So firstly, to get a pre-trained model with the fast ai library use the following code:
from fastai.conv_learner import *
# import library for creating learning object for convolutional #networks
model = VVG16()
# assign model to resnet, vgg, or even your own custom model
PATH = './folder_containing_images'
data = ImageClassifierData.from_paths(PATH)
# create fast ai data object, in this method we use from_paths where
# inside PATH each image class is separated into different folders
learn = ConvLearner.pretrained(model, data, precompute=True)
# create a learn object to quickly utilise state of the art
# techniques from the fast ai libraryWith the learn object now created, we can solve the problem of only finely tuning the last layers by quickly freezing the first layers:
learn.freeze()
# freeze layers up to the last one, so weights will not be updated.
learning_rate = 0.1
learn.fit(learning_rate, epochs=3)
# train only the last layer for a few epochsOnce the last layers are producing good results, we implement differential learning rates to alter the lower layers as well. The lower layers want to be altered less, so it is good practice to set each learning rate to be 10 times lower than the last:
learn.unfreeze()
# set requires_grads to be True for all layers, so they can be updated
learning_rate = [0.001, 0.01, 0.1]
# learning rate is set so that deepest third of layers have a rate of 0.001, # middle layers have a rate of 0.01, and final layers 0.1.
learn.fit(learning_rate, epochs=3)
# train model for three epoch with using differential learning rates3. How to find the right learning rate
The learning rate is the most important hyper-parameter for training neural networks, yet until recently deciding its value has been incredibly hacky. Leslie Smith may have stumbled upon the answer in his paper on cyclical learning rates; a relatively unknown discovery until it was promoted by the fast.ai course.
In this method, we do a trial run and train the neural network using a low learning rate, but increase it exponentially with each batch. This can be done with the following code:
learn.lr_find()
# run on learn object where learning rate is increased exponentially
learn.sched.plot_lr()
# plot graph of learning rate against iterations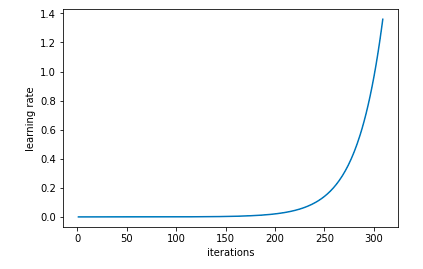
Meanwhile, the loss is recorded for every value of the learning rate. We then plot loss against learning rate:
learn.sched.plot()
# plots the loss against the learning rate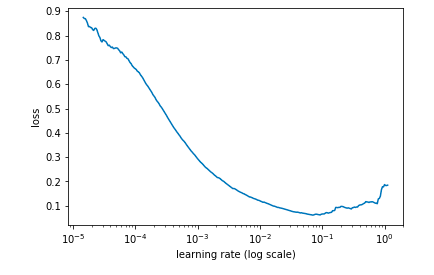
The optimum learning rate is determined by finding the value where the learning rate is highest and the loss is still descending, in the above case about this value would be 0.01.
4. Cosine annealing
Me too! BTW CLR is worse than Leslie's newer 1cycle training in all cases that we're aware of. We use an even better cosine-annealed version that isn't (AFAIK) published but is described in our docs https://t.co/4e6nnUUmnK?
— Jeremy Howard (@jeremyphoward) August 5, 2019
With each batch of stochastic gradient descent (SGD), your network should be getting closer and closer to a global minimum value for the loss. As it gets closer to this minimum, it hence makes sense that the learning rate should get smaller so that your algorithm does not overshoot, and instead settles as close to this point as possible. Cosine annealing solves this problem by decreasing the learning rate following the cosine function as seen in the figure below.
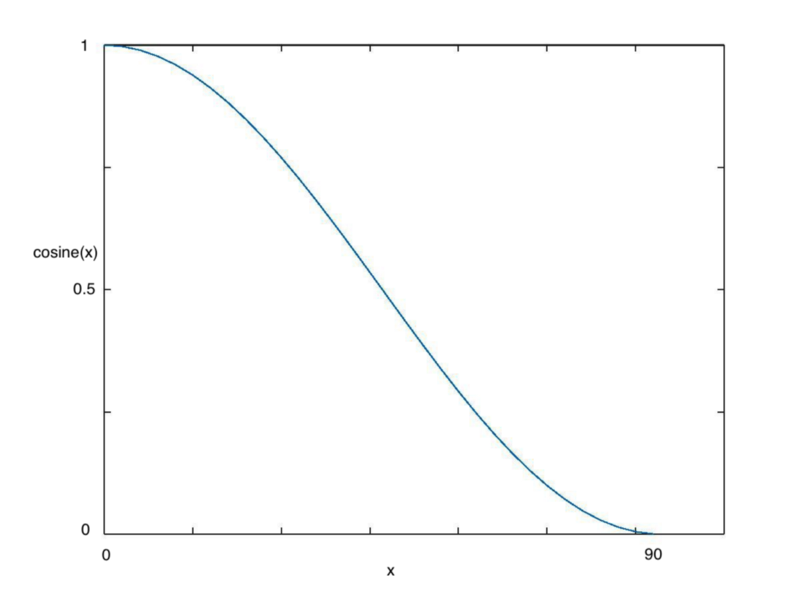
Looking at the figure above, we see that as we increase x the cosine value descends slowly at first, then more quickly and then slightly slower again. This mode of decreasing works well with the learning rate, yielding great results in a computationally efficient manner.
learn.fit(0.1, 1)
# Calling learn fit automatically takes advantage of cosine annealingThe technique is implemented automatically by the fast ai library when using learn.fit(). The above code would have our learning rate decrease across the epoch as shown in the figure below.
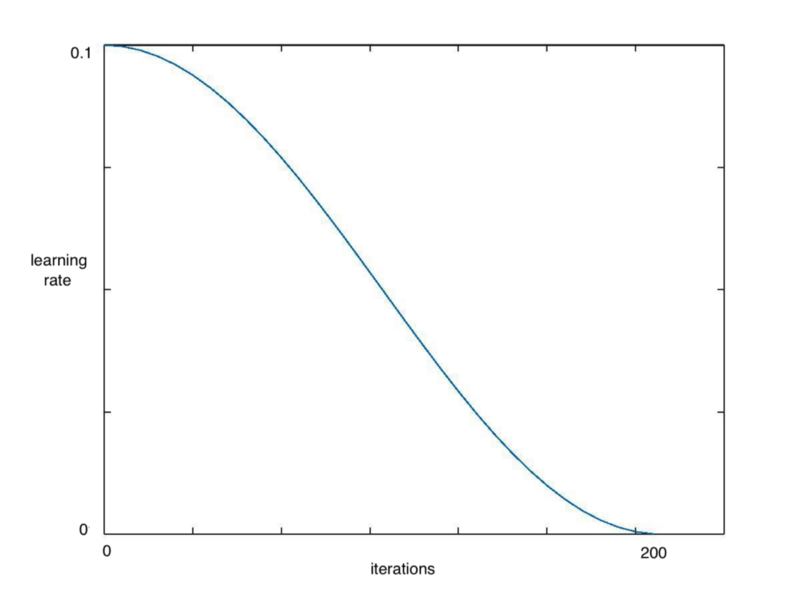
However we can go one step further than this even, and introduce restarts
5. Stochastic Gradient Descent with restarts
During training it is possible for gradient descent to get stuck at local minima rather than the global minimum.
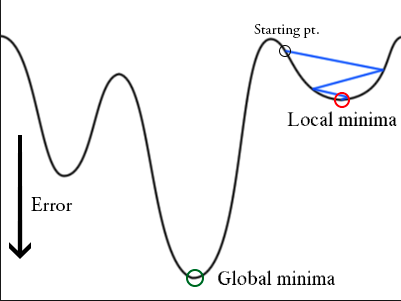
By increasing the learning rate suddenly, gradient descent may “hop” out of the local minima and find its way toward the global minimum. Doing this is called stochastic gradient descent with restarts (SGDR), an idea shown to be highly effective in a paper by Loshchilov and Hutter.
SGDR is also handled for you automatically by the fast ai library. When calling learn.fit(learning_rate, epochs), the learning rate is reset at the start of each epoch to the original value you entered as a parameter, then decreases again over the epoch as described above in cosine annealing.
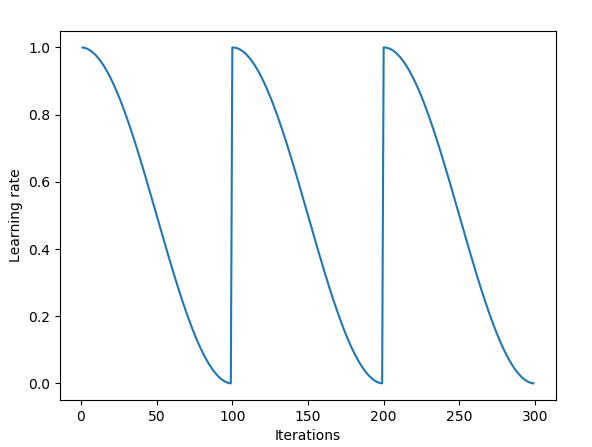
Each time the learning rate drops to it’s minimum point (every 100 iterations in the figure above), we call this a cycle.
cycle_len = 1
# decide how many epochs it takes for the learning rate to fall to
# its minimum point. In this case, 1 epoch
cycle_mult=2
# at the end of each cycle, multiply the cycle_len value by 2
learn.fit(0.1, 3, cycle_len=2, cycle_mult=2)
# in this case there will be three restarts. The first time with
# cycle_len of 1, so it will take 1 epoch to complete the cycle.
# cycle_mult=2 so the next cycle with have a length of two epochs,
# and the next four.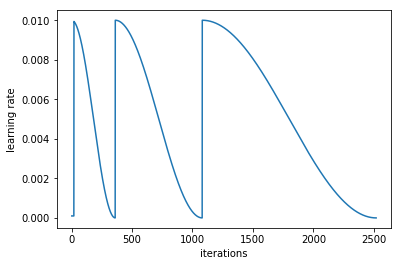
Playing around with these parameters, along with using differential learning rates, are the key techniques allowing fast ai users to perform so well on image classification problems.
Cycle_mult and cycle_len are discussed here on the fast.ai forum, while the concepts above regarding learning rate can be found explained more fully in this fast ai lesson and this blog post.
6. Anthropomorphise your activation functions
Softmax likes to pick just one thing. Sigmoid wants to know where you are between -1 and 1, and beyond these values won’t care how much you increase. Relu is a club bouncer who won’t let negative numbers through the door.
It may seem silly to treat activation functions in such a manner, but giving them a character ensures not using them for the wrong task. As Jeremy Howard points out, even academic papers often use softmax for multi-class classification, and I too have already seen it used incorrectly in blogs and papers during my short time studying DL.
7. Transfer learning is hugely effective in NLP
Just as using pre-trained models has proven immensely effective in computer vision, it is becoming increasingly clear that natural language processing (NLP) models can benefit from doing the same.
In the 4th lesson of fast.ai, Jeremy Howard builds a model to determine if IMDB reviews are positive or negative using transfer learning. The power of this technique is observed instantly, where the accuracy he achieves beat all previous efforts of the time presented in a paper by Bradbury et al.
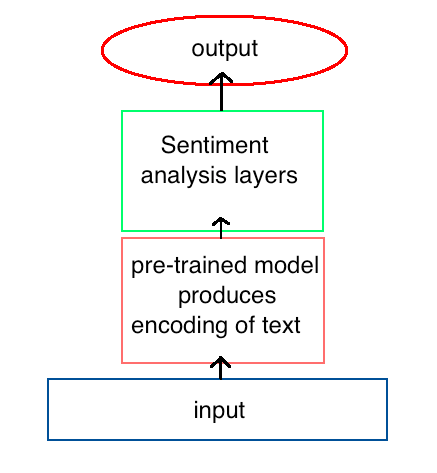
The secret to success lies in training a model firstly to gain some understanding of the language, before using this pre-trained model as a part of a model to analyze sentiment.
To create the first model, a recurrent neural network (RNN) is trained to predict the next word in a sequence of text. This is known as language modeling. Once the network is trained to a high degree of accuracy, its encodings for each word are passed on to a new model that is used for sentiment analysis.
In the example we see this language model being integrated with a model to perform sentiment analysis, but this same method could be used for any NLP task from translation to data extraction.
And again the same principles as above in computer vision apply here, where freezing and using differential learning rates can yield better results.
The implementation of this method for NLP is too detailed for me to share the code in this post, but if you are interested watch the lesson here and access the code here.
8. Deep learning can challenge ML in tackling structured data
Fast.ai shows techniques to rapidly generate great results on structured data without having to resort to feature engineering or apply domain specific knowledge.
Their library makes the most of PyTorch’s embedding functions, allowing rapid conversion of categorical variables into embedding matrixes.
The technique they show is relatively straight forward, and simply involves turning the categorical variables into numbers and then assigning each value an embedding vector:
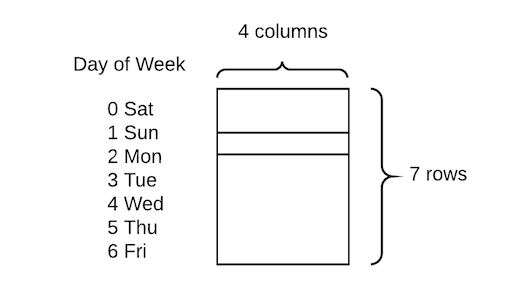
The advantage of doing this compared to the traditional approach of creating dummy variables (i.e. doing one hot encodings), is that each day can be represented by four numbers instead of one, hence we gain higher dimensionality and much richer relationships.
The implementation shown in this lesson (the code here) gained third place in the Rossman Kaggle competition, only beaten by domain experts who had their own code to create many, many extra features.
The idea that using deep learning dramatically reduces need for feature engineering has been confirmed by Pinterest too, who have said this to be the case ever since they switched to deep learning models, gaining state of the art results with a lot less work!
9. A game-winning bundle: building up sizes, dropout and TTA
On the 30th April, the fast.ai team won the DAWNBench competition (run by Stanford University) on Imagenet and CIFAR10 classification. In Jeremy’s write-up of the victory, he credits their success to the little extra touches available in the fast.ai library.
One of these is the concept of Dropout, proposed by Geoffrey Hinton two years ago in this seminal paper. Despite its initial popularity, it seems to be somewhat ignored in recent computer vision papers. However, PyTorch has made its implementation incredibly easy, and with fast ai on top it’s easier than ever.

Dropout combats overfitting and so would have proved crucial in winning on a relatively small dataset such at CIFAR10. Dropout is implemented automatically by fast ai when creating a learn object, though can be altered using the ps variable as shown here:
learn = ConvLearner.pretrained(model, data, ps=0.5, precompute=True)
# creates a dropout of 0.5 (i.e. half the activations) on test dataset.
# This is automatically turned off for the validation setFor more information on dropout see this video.
Another incredibly simple and effective method they used for tackling overfitting and improving accuracy is training on smaller image sizes, then increasing the size and training the same model on them again.
# create a data object with images of sz * sz pixels
def get_data(sz):
tmfs = tfms_from_model(model, sz)
# tells what size images should be, additional transformations such
# image flips and zooms can easily be added here too
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
# creates fastai data object of create size
return data
learn.set_data(get_data(299))
# changes the data in the learn object to be images of size 299
# without changing the model.
learn.fit(0.1, 3)
# train for a few epochs on larger versions of images, avoiding overfittingA final technique that can raise accuracy by one percent or two is test time augmentation (TTA). This involves taking a series of different versions of the original image (for example cropping different areas, or changing the zoom) and passing them through the model. The average output is then calculated for the different versions and this is given as the final output score for the image. It can be called by running learn.TTA().
preds, target = learn.TTA()This technique is effective as perhaps the original cropping of an image may miss out a vital feature. Providing the model with multiple versions of the picture and taking an average makes this less likely to have an effect.
10. Creativity is key

Not only did the fast.ai team win prizes for fastest speed in the DAWNBench competition, but these same algorithms also won the prize for being cheapest to run. The lesson to be learnt here is that creating successful DL applications is not just a case of chucking huge amounts of GPU at the issue, but should instead be a question of creativity, of intuition and innovation.
Most of the breakthroughs discussed in this article (dropout, cosine annealing, SGD with restarts, the list goes on…) in fact were such exact moments, where someone thought of approaching the problem differently. These approaches then brought increases in accuracy greater than those that would have been achieved by simply throwing another thousand images at the problem with a handful of IBM computers.
So just because there are a lot of big dogs out there with a lot of big GPUs in Silicon Valley, don’t think that you can’t challenge them, or that you can’t create something special or innovative.
In fact, perhaps sometimes you can see constraints as a blessing; after all, necessity is the mother of invention.
ULMFit has code, pretrained models, and tutorials, requires 50x fewer resources than GPT, yet *still* beats it on some tasks, and has been used in numerous competition wins.
— Jeremy Howard (@jeremyphoward) February 21, 2019
No need to only mention things from big well funded labs! :)
Dear friends,
I spent last weekend coding and training a few neural networks on my laptop. I enjoy many different types of work, but playing around in a Jupyter Notebook with TensorFlow/Keras is still one of my favorites!
You can do a lot with just a laptop. The idea that you need thousands of dollars of GPUs to do anything is oversimplified. I’ve mentioned many times that one cutting edge of deep learning is scalability. We still need faster computers, and scaling up existing supervised and unsupervised learning methods will drive significant improvements. (I consider both GPT-2 and BERT recent examples of this.) Faster computers will also open up new research directions.
But people were training on MNIST (60,000 examples, albeit tiny 28x28 images) before there were GPUs. And there’s plenty of cutting edge work to be done with Small Data. Last weekend I was playing with a manufacturing problem where I had 3 labeled examples, and the challenge was getting the network architecture right, not scaling it up. My model trained in 20 seconds on my Mac, without any GPUs.
If you’re in a position to push scalability, please keep doing so--we need that! But if you don’t have a supercomputer at your disposal, you can still do plenty of of cutting edge research with some creativity and a laptop.
Keep learning!
Andrew Ng - The Batch, August 7, 2019
FloydHub Call for AI writers
Want to write amazing articles like Samuel and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Samuel Lynn-Evans
For the last 10 years, Sam has combined his passion for science and languages by teaching life sciences in foreign countries. Seeing the huge potential for ML in scientific progress, he began studying AI at school 42 in Paris, with the aim of applying NLP to biological and medical problems. Sam is also an AI Writer for FloydHub.