Reading Minds with Deep Learning
Explore the latest trends in Brain-Computer Interfaces - and train a deep learning model to predict what people are doing from fluctuations in their brain voltage readings.

To live is to translate. When we listen, vibrating air particles are translated into words. When we see, bouncing electromagnetic (EM) waves become vision. The signals that surround us, whether they're EM waves or vibrating air, are constantly being transformed by our brains into information and understanding.
In the last few years, machine learning algorithms have caused much excitement as they too have proven adept at such tasks. Accessing and interpreting the nervous system’s signals is the domain of Brain Computer Interfaces (BCI).
The implications for BCI technology could be staggering.
If we could just learn to translate these signals, then we could read thoughts, use our devices without our hands, and (according to Elon Musk) merge ourselves with the A.I. of the future.
In this post, I'll demonstrate how you can predict what people are doing from fluctuations in their brain voltage readings using some basic deep learning techniques.
Here's what we'll cover in this post:
- Overview of the current companies advancing BCI
- Implementing our own BCI neural network
- Ideas for the future direction of BCI
Far from fantasy: the current state of Brain Computer Interfaces
Not only are there big names and huge sums of money backing BCI companies, but there are already surprisingly accurate and fascinating results.
CTRL-labs

Last year, CRTL-labs showed a staff member typing characters at regular speed without touching a keyboard. In another demo, he played Asteroids with his hands in his pockets.
The idea behind this magic is actually quite simple. You gently enact the finger motions you would do when playing a game, meanwhile a bracelet on your wrist records the nervous signals and translates them into their corresponding actions.
CRTL-labs intercepts what you might call the low-hanging fruit of the nervous system: reading nervous signals from the spinal cord and arms, rather than going for the inaccessible brain itself.
This pragmatic approach has shown much promise, and circumvents BCI’s unfashionable issue of having to wear sensors on your head.
Most interestingly, their work aims to question the limitations of the brain:
If, one day, we can communicate with computers via nervous signals alone, could our nervous system learn to operate more ‘digits’ than the ten we currently employ?
The idea that we may be able to work on a computer like Spiderman's rival Dr. Octopus is a tantalizing one, indeed.
MindMaze

Many of the immediate applications of BCI are medical. Controlling computers (or even prosthetic limbs) with thoughts would allow paralyzed people to regain independence.
MindMaze goes a step beyond this application, developing seamless virtual reality (VR) experiences for people recovering from strokes so that they can relearn how to control their muscles.
Their current chip promises to translate your thoughts to actions, which will then be enacted by an avatar within a VR space. In my project below, I explore this idea in more detail, showing how this initial translation from thought to action can be achieved with a simple example.
Kernel
The founder of Braintree (which sold to eBay for $800m), Bryan Johnson, has also dived into the BCI field with his company Kernel, along with $100m of his own cash.
Their short-term aim is to translate the brain’s memories to a computer chip. They claim to be doing so with about 80% success currently. But we're still waiting to learn more about what exactly what this 80% success rate means in practice.
Nonetheless, the fact that Kernel is able to translate thought to bits in some capacity show BCIs to be far beyond their infancy.
NeuraLink

NeuraLink is another one of Elon Musk's brainchildren. The company keeps its activity rather discreet, though its mission promises exciting things to come.
Unsurprisingly for an Elon Musk creation, Neuralink lies at the extremes of the BCI spectrum. While the company has some immediate and practical missions, such as improving medicine and the way we connect to our devices, the true purpose of Neuralink seems to be the fusion of humanity with the AIs of the future.
Musk’s AI-induced existential fears are no secret and he is adamant that humanity’s only chance of long-term survival lies in evolving with AI. For Neuralink, BCIs offer us humans the route to salvation.
How I Read Brainwaves with a Convolutional Neural Network
Excited to see just how approachable this subject was, I took on my own challenge to translate electrical readings from the brain’s surface into their corresponding actions.
This Kaggle dataset provides EEG readings taken from 12 people while they performed a task with their hands (I've included a video of the tasks below).
My challenge was to devise a neural network that could predict what the hand was doing from the brain reading along. Ultimately, my model achieved an Area Under the Curve (AUC) score of 94%.
My approach is a simplified version of the current highest score, which achieved 98% AUC score. Given this efficacy, there is good reason to suspect that companies like Neuralink and CTRL+LAB might be using similar models behind the scenes.
The Task
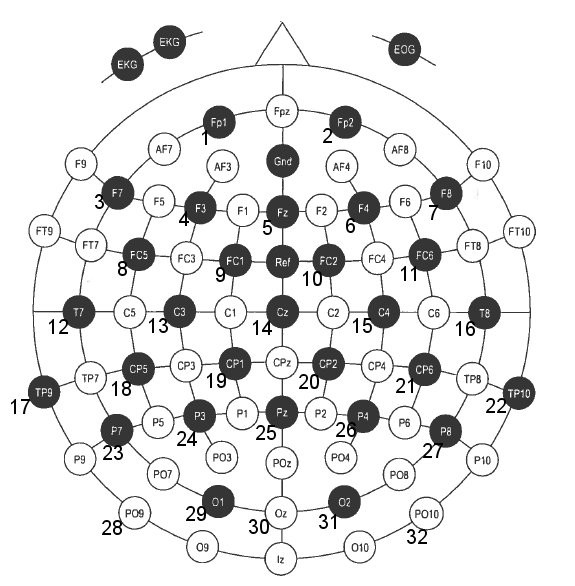
For this task, readings were taken from the 32 positions in black in the EEG diagram above.
The subject would be asked to pick up a weight, lift it, and release it. The challenge was to correlate readings from the EEG with these five actions:
- HandStart (light flashes telling subject to begin grasp and lift)
- FirstDigitTouch (touches object)
- BothStartLoadPhase (thumb and finger on object)
- LiftOff (pick up object)
- Replace (put down object)
- BothReleased (release object)
Exploring The Data
To begin looking at the data, I picked the first event HandStart. This event refers to the moment that a light flashes, telling the subject to begin the grasp and lift.
Looking at the first subject, this figure shows how the 32 values in their EEG readings changed during a time window of 200ms before HandStart until 300ms after.
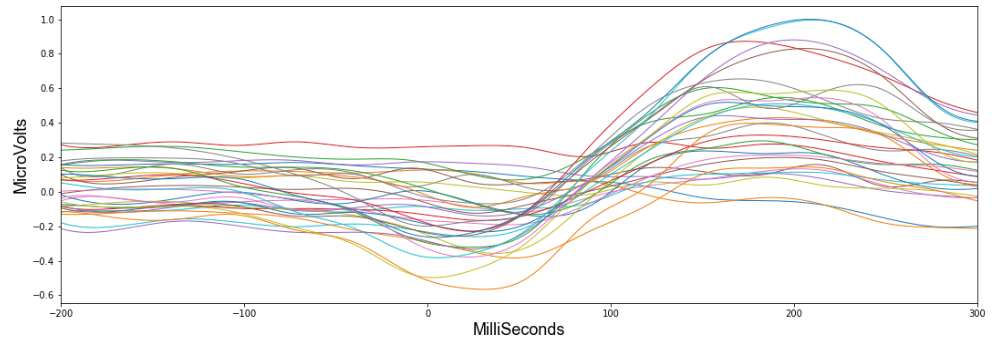
Already we can see a pattern – and if we average all the 32 values, it suddenly becomes much more clear.
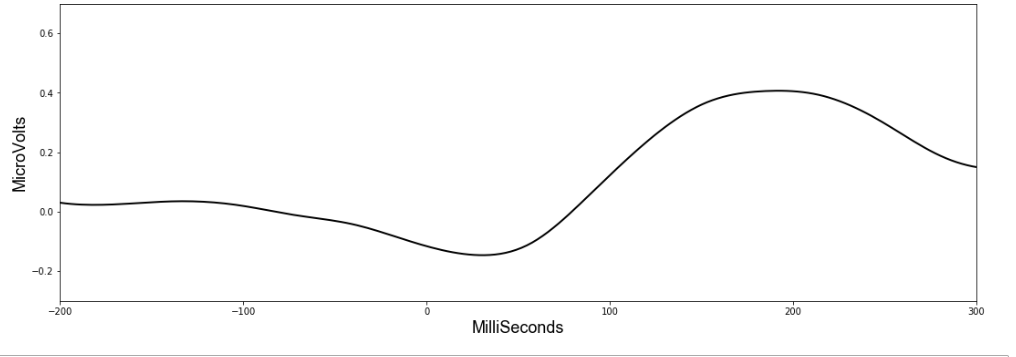
It seems HandStart is accompanied by a general lowering of the overall voltage readings followed by a spike. The model should be able to recognize these patterns when making predictions. Importantly, the data has a similar shape when we look at another subject:
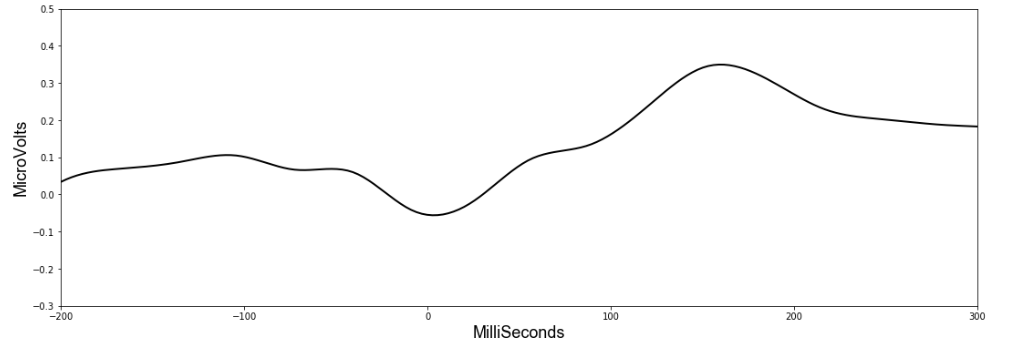
With such clear patterns, you might wonder who even needs a machine learning algorithm? Yet unfortunately things become less obvious as we look at the rest of the subjects.
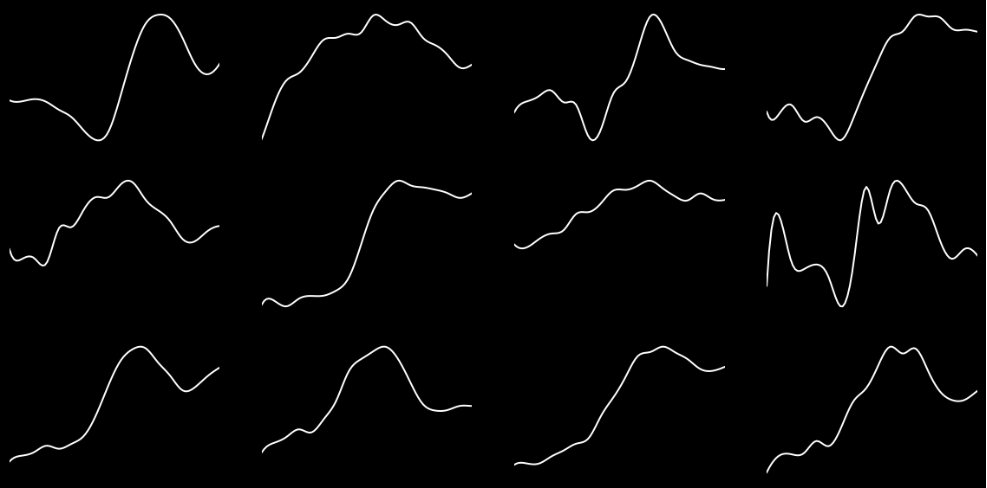
Though the downward and upward spike is seen relatively consistently across the board, the overall shape of the curve varies considerably. Apart from an overall increase in activity, a discernible pattern is not readily made out by the human eye.
Exploring a bit further, we can visualize where most of the variance is occurring as the grasp and lift is performed by using the python library MNE (specifically built for analyzing EEG results).

The analysis corresponds perfectly with neuroscience theory, which states the motor cortex (the green area in the diagram above) of the left hemisphere would be active during movements on the right side of the body. The red area from our EEG scan is exactly where the left hemisphere motor cortex is.
Approach
The key to understanding which action is taking place lies in seeing the current reading in its proper context.
So, for every reading we send into our machine learning model, we will also send in readings from across a previous time window. This way the model can ‘see’ the shape of the wave leading up to the current event.
Convolutional neural networks (CNN) work well with time series data, so this will be our model of choice.
Though reading minds may seem like an incredibly complex art, high-level deep learning libraries like Pytorch mean we can actually code a model in 13 lines:
class model(nn.Module):
def __init__(self, out_classes, drop=0.5, d_linear=124):
super().__init__()
self.conv = nn.Conv1d(32, 16, kernel_size=3, padding=0,
stride=1)
self.pool = nn.MaxPool1d(2, stride=2)
self.linear1 = nn.Linear(8176, d_linear)
self.linear2 = nn.Linear(d_linear, out_classes)
self.dropout = nn.Dropout(drop)
self.conv = nn.Sequential(self.conv, nn.ReLU(inplace=True),
self.pool, self.dropout)
self.dense = nn.Sequential(self.linear1,\
nn.ReLU(inplace=True), self.dropout,\
self.dropout3, self.linear2)
def forward(self, x):
x = self.conv(x)
output = self.dense(x.view(-1))
return torch.sigmoid(output)The above gives the code for a simple (but effective…) CNN perfectly capable of tackling the job.
It consists of a 1d convolutional layer, and two linear layers. While a full description of how these processes work is beyond the scope of this post, let’s at least get a quick overview.
A convolutional layer simply consists of a kernel that slides along our data and applies its weights to the data values. This animation I made explains better than words alone:
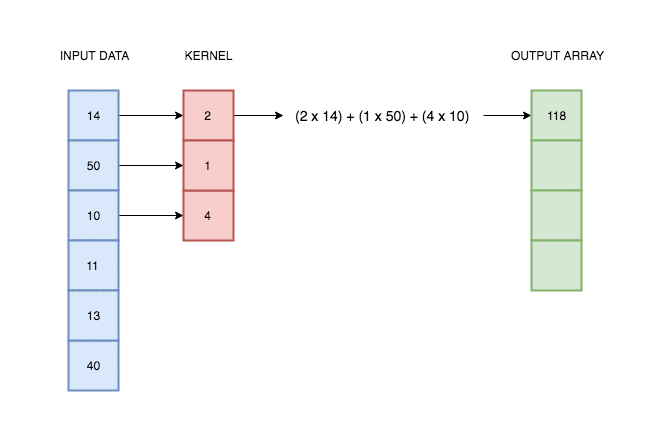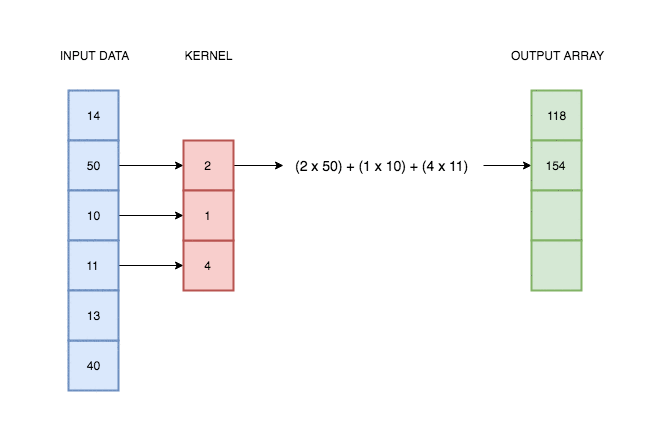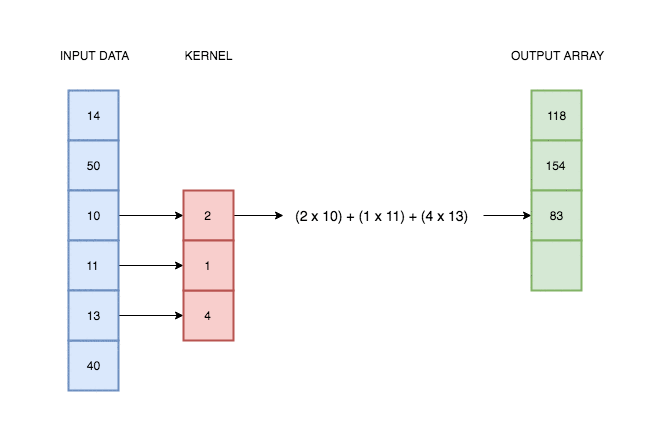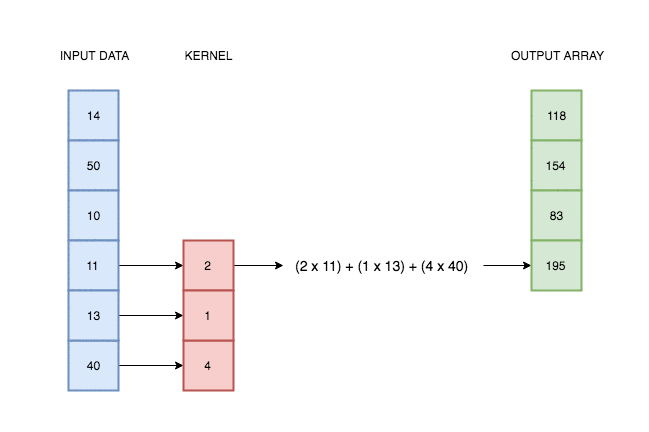
In reality, deep learning networks will have multiple kernels, producing multiple output arrays. In the network coded above, we use 64 kernels each with their own weights, and hence produce 64 different output vectors. Each of these kernels can react to a different kind of pattern in the input.
There will also be multiple input channels (32, in fact, to match our EEG inputs), each one containing the previous readings for each EEG position.
The outputs from the convolutional layer are then all lined up in a single vector and put through a neural network with two layers. Here is an animation of a simple two layer neural network with three inputs, a first layer with two nodes, and a final layer with one:

In our neural network, the process is the same – although much bigger (8,128 input nodes, 124 nodes in the first layer, and 6 nodes in the final layer). There are 6 final nodes because there are 6 possible actions, and we determine an action is happening if it’s corresponding node scores above a certain threshold.
Two linear layers in a neural network is a pretty standard setup, it allows for XOR calculations (see this post for more details) and means we don’t reduce the input immediately from 8,196 nodes to 6 nodes. Deciding the exact number of kernels and linear nodes is more of an art than science, and requires some fiddling around.
The weights in the convolutional kernel and the linear layers are initially random, but a process called back-propagation corrects them as we train the network on the data. For an in-depth tutorial on this process, I’d recommend Andrew Ng’s free machine learning Coursera course and my previous tutorials.
When trained, the interactions between all these weights allows the network to detect patterns in data and make accurate predictions.
Results
Running this model over all the data once (taking less than an hour) was enough for the network to discern patterns in the EEG readings and generate a validation score with 94% AUC.
However as I was to learn, 94% AUC is not the same thing as 94% accuracy. AUC is a measure used in academia to compare results as it gives a score independent of class imbalances and thresholds. In its simplest terms, it gives the probability that the classifier will rank a randomly chosen positive example higher than a randomly chosen negative example (read more here).
Yet how does this translate into actual results? The best way to gain a true gauge of how the model fared is to dig into some visuals.
Let’s look at some data previously unseen by our model. In this series, the subject performs the grasp and lift 28 times. The figure below shows when the subject carried out the actions (True) in blue and when the model predicted the actions were occurring (Prediction) in orange.
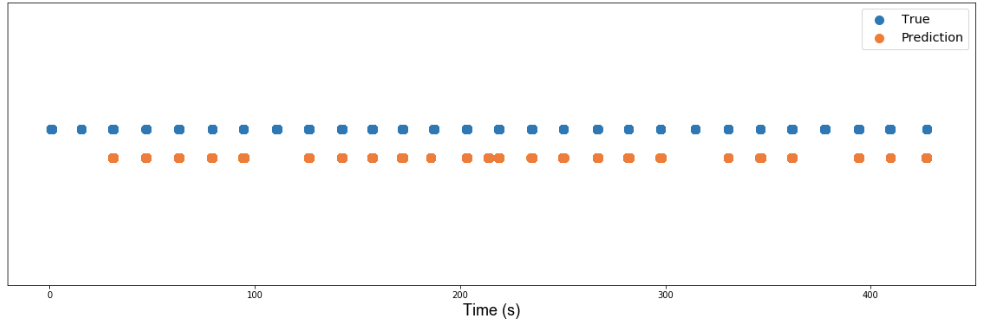
The model correctly predicts 23 out of the 28 lifts, and mistakenly predicts a lift when the subject isn’t performing one.
If we closely examine a singular incident of the subject performing the grasp and lift, we can see how correctly the model predicted the exact action that was occurring. In the figure below, we focus on the third grasp and lift in the series; blue represents the prediction and orange when it actually occurred.
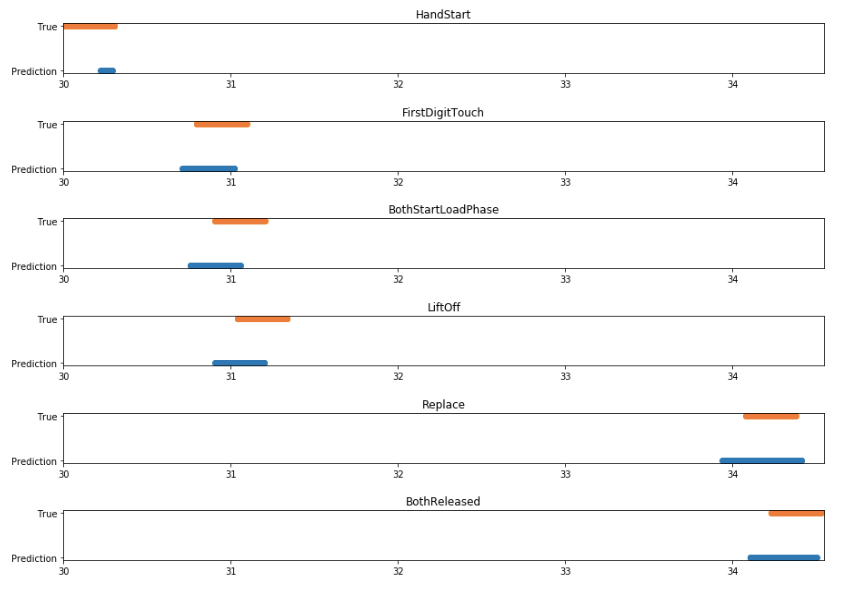
I think these results are particularly impressive. Although the predictions don’t line up exactly with the data labels, this is not important in a functional sense.
The orange bars reflect a time window of +-150ms around the action. Despite the model not predicting the entire time window, it does output a correct prediction when each event actually occurs. The model could hence be used to successfully predict when an action is happening.
Notably, we see the model is better at predicting the time window before the action than after it. The brain activity for a motion occurs before the movement itself, as signals start in the brain and must make their way down to the hand, so perhaps this is to be expected.
The only exception to this pattern is seen in the HandStart event. This event refers to when a light flashes and the subject reacts to it. In this case, the nervous activity would actually occur after the light flashes and so it makes sense that our model predicts the event after it happens.
Conclusion
The above results fairly reflect how the model performed overall. If you would like to play around with the data and my model, please check out my Github repo. You can also open a Jupyter workspace on FloydHub with my project and trained model by clicking this button:

While 23 out of 28 predictions is not perfect, the predictions do show great degrees of precision in separating the actions, which is remarkable.
Nevertheless, the actions in the trials always occurred in the same order, and there is perhaps the risk that the model guesses actions based on a frame’s position in time. That is, it could be assuming that the subject is performing FirstDigitTouch solely because it detected HandStart occurred a few moments before. A dataset with varied orders or motions could prove interesting here.
The downsides of Deep Learning for BCIs
That a first-year student of machine learning can so quickly implement a mind-reading model seems an incredible testimony to the current state of AI technology. And with all this talk of singularities and human-AI hybrids, it’s easy to get carried away.
My results are far from perfect, but neither is the top score of 98% – and this is important with BCIs. Technology must be consistent; when we scroll a mouse we want the screen to move up every time, and we will expect the same consistency from BCIs.
Unfortunately, deep learning algorithms still can’t be trusted to identify a cat every time, and it's perhaps for these inconsistencies that back-flipping robotics leader Boston Dynamics is rumored to not use machine learning for their robots’ impressive acrobatics.
Additionally there is another downside for those of us with an interest in neuroscience.
Though our model only required 14 lines of code, contained within those lines are many thousands of weights. Theses values let the neural network reach its conclusions, but they don’t let us know how it does it.
This is disappointing to me. I would’ve hoped that once technologies were capable of interpreting brain signals, we would’ve also learnt how these signals were working. For example in this case, I'd love to know which areas of the brain were important in which actions, and how they coordinated together to produce the fine motor outputs in the task. The many mysteries of the brain remain unexplored.
There is surely promise…
Yet an upside to this phenomenon exists. With Deep Learning, we don’t always need to know how things work in order to get a solution.
Deep Learning networks discover the rules for us, and we move onward in their wake. Progress has taken this form for centuries; we used the wheel before we knew the laws of physics, we used electricity before we knew about electrons.
Our brains translate air and light into pulsing electric signals that become conscious experience. BCIs now promise to translate our thoughts to bits and chips. If a full symbiosis was to ever occur, we could perhaps one day feel the weights of a deep learning network and know exactly why it comes to the conclusion it does.
Though before we even get that far there is reason enough for excitement. Computers you manipulate with your nervous system are already here, and the limits of what the human brain can output stand to be tested.
Creating your own projects
Seeing how successfully we can predict a small set of motions from EEG readings, one can’t help but wonder what else could be achieved if we had access to our own electro-sensing devices?
I myself am utterly curious. If you are too, this website gives a list of EEG kits you can buy for various prices, while this 3d-printable model for $350 particularly caught my eye.
For my next project I intend to buy some sensors and try to create a rock-paper-scissors game that two people can play without moving their hands.
Whatever you get up to, make sure to use FloydHub to run your jobs, and let us know what you get up to!
FloydHub Call for AI writers
Want to write amazing articles like Samuel and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Samuel Lynn-Evans
For the last 10 years, Sam has combined his passion for science and languages by teaching life sciences in foreign countries. Seeing the huge potential for ML in scientific progress, he began studying AI at school 42 in Paris, with the aim of applying NLP to biological and medical problems. Sam is also an AI Writer for FloydHub.