Naïve Bayes for Machine Learning – From Zero to Hero
Bayes’ Theorem is about more than just conditional probability, and Naive Bayes is a flavor of the theorem which adds to its complexity and usefulness.


Before I dive into the topic, let us ask a question – what is machine learning all about and why has it suddenly become a buzzword? Machine learning fundamentally is the “art of prediction”. It is all about predicting the future, based on the past. The reason it is a buzzword is actually not about data, technology, computing power or any of that stuff. It’s just about human psychology! Yes, we humans are always curious about the future, aren’t we? And what’s more, it’s the age of data and we can make good data-driven predictions. This is the essence of machine learning. The efficacy of a prediction is based on two factors: how accurate it is and how early it is made. You may be able to predict rain with an accuracy of 99%, but if you can only tell just before the first drizzle, it’s of no use!! On the flip side, if you are going to predict rain a week ahead, but the chances of your prediction coming true is only 10% , hmmm, that’s no good either!
So the art of prediction is just about hitting that sweet spot between timing and accuracy. In general, to get early predictions right takes an enormous amount of intuition, since early predictions do not have a privilege called “historic data”. Early predictions are actually not data-driven. Imagine a situation where you are trying to predict whether it will rain the forthcoming week, backed with information relating to weather conditions of the 7 days before the actual “rainy day”, for the past 2 years. Now with this data by your side, if you are trying to make a prediction and you are getting it 70% right, what would have changed suddenly? Yes, it’s the historic data. You would try to assess what went wrong the previous time, consider the key factors, which affect the weather conditions, and try to give a better prediction the next time. This approach is called the Bayesian approach, wherein the past probabilities can be reversed if additional information is provided. We will see this in detail in the upcoming sections.
Probability Theory - A game of Randomness vs. Likelihood

It is not only important what happened in the past, but also how likely it is that it will be repeated in the future. Probability theory is all about randomness vs. likelihood (I hope the above is intuitive, just kidding!). It basically quantifies the likelihood of an event occurring in a random space. For example, if I flip a coin and expect a “heads”, there is a 50%, or 1⁄2, chance that my expectation will be met, provided the “act of flipping”, is unbiased (a fair, or unbiased coin has the same probability to get head or tail). This assumption of fairness is attributed to randomness and the chance of meeting the expectation is my probability.
Let’s take another classic example of rolling a dice. If I roll a dice and expect to get a “4”, what are my odds? It is quantified by (expected outcome / total no. of outcomes), which is 1/6, i.e. out of a total possible 6 outcomes, we expect one specific outcome of a number 4. The sample space contains or holds all possible events. Probability is always quantified as a percentage or a number between 0 and 1. The probability can either be a discrete or a continuous variable.
The above examples are represented pictorially below.
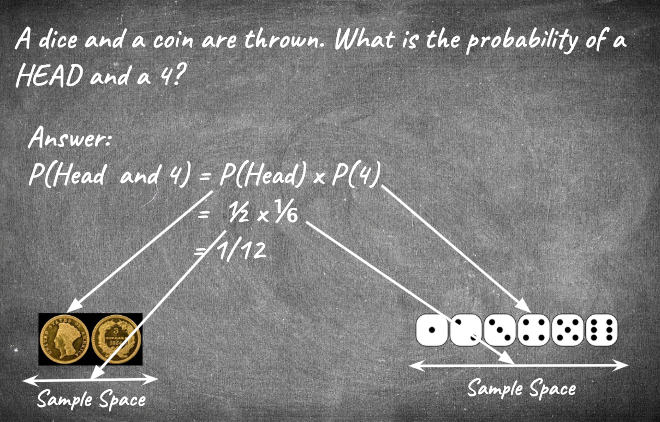
So what’s the math? – The Bayes’ Theorem
Before going to Bayes’ theorem, we need to know about a few (more!) basic concepts of probability. Firstly, in the above example, we are calculating the probability of the coin landing on heads AND the dice landing on 4. This is called a joint probability. There are two other types of probabilities. One is called conditional probability, which calculates the probability of heads GIVEN THAT the dice lands on 4. Lastly, if you want the probability of specific outcomes, i.e. probability of JUST the coin or JUST the dice, we call it the marginal probability.
Now, Bayes’ theorem (named after Rev. Thomas Bayes 1702-1761), is based on this. Let’s see how:
It states, for two events A & B, if we know the conditional probability of B given A and the probability of B, then it’s possible to calculate the probability of B given A.

Below is one simple way to explain the Bayes rule. The task is to identify the color of a newly-observed dot.

Since there are twice as many GREEN objects as RED, it is reasonable to believe that a new case (which hasn't been observed yet) is twice as likely to have membership with GREEN rather than RED. In the Bayesian analysis, this belief is known as the prior probability. Prior probabilities are based on previous experience, in this case the percentage of GREEN and RED objects, and often used to predict outcomes before they actually happen.
Since there is a total of 60 objects, 40 of which are GREEN and 20 RED, our prior probabilities for class membership can be written as below:
$$Prior\space Probability\space of\space GREEN = \dfrac{number\space of\space GREEN\space objects}{total\space number\space of\space objects} = \dfrac{40}{60}$$
$$Prior\space Probability\space of\space RED = \dfrac{number\space of\space RED\space objects}{total\space number\space of\space objects} = \dfrac{20}{60}$$
Having formulated our prior probability, we are now ready to classify a new object (WHITE circle in the diagram below). Since the objects are well clustered, it is reasonable to assume that the more GREEN (or RED) objects in the vicinity of X, the more likely that the new cases belong to that particular color. To measure this likelihood, we draw a circle around X which encompasses a number (to be chosen a priori) of points irrespective of their class labels. Then we calculate the number of points in the circle belonging to each class label. From this we calculate the likelihood:

From the illustration above, it is clear that the likelihood of X given GREEN is smaller than Likelihood of X given RED, since the circle encompasses 1 GREEN object and 3 RED ones.
Although the prior probabilities indicate that X may belong to GREEN (given that there are twice as many GREEN compared to RED) the likelihood indicates otherwise; that the class membership of X is RED (given that there are more RED objects in the vicinity of X than GREEN). In the Bayesian analysis, the final classification is produced by combining both sources of information, i.e., the prior and the likelihood, to form a posterior probability using Bayes' rule.
$$Posterior\space Probability\space of\space GREEN = Prior\space Probability\space of\space GREEN \times Likelihood\space of\space GREEN = \dfrac{40}{60} \times \dfrac{1}{40} $$
$$Posterior\space Probability\space of\space RED = Prior\space Probability\space of\space RED \times Likelihood\space of\space RED = \dfrac{20}{60} \times \dfrac{3}{20} $$
Finally, we classify X as RED since its class membership achieves the largest posterior probability.
Bayesianism - A ray of hope at the end of the tunnel of probability!
The Bayes theorem is a lot more than just a theorem based on conditional probability. Most examples of Bayes’ theorem are based on clinical tests (the below pic gives a flavourful interpretation, so let me try a different example!)

Let’s take an example of a bank fraud/ loan default. Imagine that you are a fund manager in a bank and you are skeptical about a particular client, one who has borrowed a huge amount of money from the bank. Now you want to know if the client would default on this loan or not. So, as a principal check, you view the client’s credit score for a probability of default (PD). You see that client’s PD is 0.99. So you conclude that there is a 99% chance of the client defaulting on the loan and whoa, you are shocked! Relax… that’s not the end of the story, because you need some Bayesian perspective!

Now, if you closely observe, the chance of the loan being defaulted in the current scenario is closely related to the question highlighted in green. Yes, how often has he defaulted before and what is the frequency of default? This is also the most important data to be collected in the space.
Let’s say the customer has a very good track record and for some reason your bank systems show a high PD for him. The background check on the customer says that there is just a 0.1% chance that he will default on a loan, i.e. a 1 in 1000 chance. So, if you crunch back the numbers, you will actually get a 9% chance of default!! Wow, that’s not bad at all!

But, the “Bayes” is biased as long as it’s not backed with enough data. Now, just imagine if the number of green increases as more data on the client is collected. Then the probability of default naturally increases, doesn’t it?
So in principle, the Bayesian “trap” is just this!! All that glitters is not gold. Ask three basic questions to get the right perspective:
- How often has gold glittered before?
- What are the chances of the metal being gold, if there is a glitter?
- What are the chances of a glitter not shown, in spite of the metal being gold?
Hope you have got the hang of it! The prediction will change if you provide it with more historic data!
And the Machine Learning – The Naïve Bayes Classifier
It is a classification technique based on Bayes’ theorem with an assumption of independence between predictors.
In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. Yes, it is really Naïve!
How does the Naive Bayes algorithm work?

The algorithm first creates a frequency table (similar to prior probability) of all classes and then creates a likelihood table. Then, finally, it calculates the posterior probability.
Let us look at the problem statement under consideration:
The Iris data set consists of the physical parameters of three species of flower: Versicolor, Setosa and Virginica. The numeric parameters which the dataset contains are Sepal width, Sepal length, Petal width and Petal length. With this data we will be predicting the classes of the flowers based on these parameters. The data consists of continuous numeric values which describe the dimensions of the respective features. Even if these features depend on each other or upon the existence of the other features, a Naive Bayes classifier would consider all of these properties to independently contribute to the probability that the flower belongs to a particular species.

There was quite a bit of exploratory data analysis performed to key in the important variables and one such output is shown below. This plot shows, out of all the variables, petal length is the key differentiator, with minimum overlap.

The Naïve assumption
The classifier will now assume that PetalLength is an independent and equally contributing feature for the classification and build a classifier as below.
| PetalLength (Range in cm) | Species* |
|---|---|
| 1-2 | Setosa |
| 3-5 | Versicolor |
| 5-7 | Virginica |
Note: The classification is obtained by assigning a probability, as in, the classifier will ask a question to itself – what is the probability of the species being Versicolor, if the PetalLength is 5cm? From the plot shown above, but for one purple line falling in the green zone (as shown below) , there is a high probability (>90%), that the classification is correct. Thus the classifier makes the decision.

Naive Bayesian models are easy to build and particularly useful for small & medium sized data sets (the one used in this article is evidence of that!). Along with simplicity, Naive Bayes is known to outperform even highly sophisticated classification methods. This classifier is used in various critical domains such as diagnosis of diseases, sentiment analysis and building email spam classifiers for this reason.
Let’s build a Naïve Bayes classifier for the famous Iris dataset classification problem.
You can easily run this code on FloydHub with a single click of the below button.

Step 1: Reading libraries for Machine Learning models
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
Step 2: Separating the data into dependent and independent variables
X = iris.iloc[:, :-1].values
y = iris.iloc[:, -1].values
Step 3: Splitting the dataset into the Training set and Test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Step 4: Building the classifier and testing the output.
# Naive Bayes
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Summary of the predictions made by the classifier
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# Accuracy score
from sklearn.metrics import accuracy_score
print('accuracy is',accuracy_score(y_pred,y_test))
Running the above code snippets will give you the output for the classifier. The complete details are given in this link.
Where this works well
- When faster prediction is required. It also works well in multiclass predictions
- When the Naive assumption holds true, the classifier performs better compared to other models like logistic regression, and you need less training data.
Where this does not work well
- During the case of “Zero Frequency”, when the categorical variable is not observed in the training set, then the classifier will be unable to predict with an assumption of “Zero” probability.
- Another limitation of Naive Bayes is the assumption of independent predictors. In real life, it is almost impossible that we get a set of predictors which are completely independent.
Beyond Naïve Bayes
The inside math - Regression vs Classification
The fundamental idea of a classification problem is that it is categorical. It “classifies” variables as per defined criteria and predicts the class. If you are not interested in classification, but estimation, i.e. you do not want whether the class is “good” or “bad” , but want to know a specific number , then the problem is a regression problem. The most common regression technique used is the linear regression (arriving at the line of best fit). Now, to convert this into a classification problem, we need to categorise all possibilities, firstly, into two classes (Binary classification). This is where logistic regression comes into the picture. Since the estimates are now categorised according to binary variables (0 to 1, where zero and one are the probabilities), this is called logistic regression. Now the Naive Bayes comes in here , as it tries to classify based on the vector or the number assigned to the token. (Approach is similar to logistic regression)
The math of this slight extension of the logistic regression, as explained below.

The above shown is the transition from linear to logistic regression. Since probabilities cannot be negative, the plot on the left is invalid. Now, as we see in the plot on the right, the sigmoid function works as our classifier and classifies according to probabilities (similar to the NB classifier). The problem is the area circled in green. The class probabilities of “zero” would yield incorrect results in the normal NB classifier, due to two issues mentioned earlier in this article (the Naive assumption and the zero frequency).
Variants of Naive Bayes (NB) are often used to improve baseline performance depending on the model variant, features used and task or dataset. A good example would be text classification problems, which are primarily used in spam classifiers as well as many other areas. These kinds of problems fall under the domain of NLP (Natural Language Processing). The basic steps followed by any algorithm for text classification is as follows:

- Preparation of a term document matrix / table based on vocabulary. This is called the “bag of words” or “vectorisation” of words. For example, if your inbox is bombarded with emails related to “Home Loans / Car loans / Personal Loans” , then the classifier will mark the word ”Loan” as a key indicator for classification. In most cases, a number is assigned against each word.
- Converts the sentences / words into tokens. Every token can be a word or punctuation. This process is called tokenization.
So, now you have a matrix of tokens and vectors with which you have to run your classifier.

Generally, Naive Bayes works best only for small to medium sized data sets. On the flip side, text classification problems usually have large datasets. So, it’s worth looking at the variants of NB classifiers to see how we can deal with this problem.
E.g. if a movie has to be classified as “good” or “bad” from IMDB reviews , based on certain key sentiment words, and the NB classifier works in a way where if it finds certain words like ''absurd”, ''nonsense”, ''boring”, etc., it will vectorise these words in the negative direction and classify that the movie is “bad”. In binary logic, assume that all “negative sounding” words will be assigned the number 0 and the movie will be classified as “bad”. So, if there is a greater frequency and likelihood of 0s in a sample review then the probability of the movie being bad is high.
Now imagine the flip side- if these words are not in the review, does that make it a good movie? Not necessarily, right? This is where the variant comes in. This is when you “trim” the vectorization process by introducing a constant. Instead of the classifier assigning the vector range as (0 ,1) it will tone down, become more sensible and assign vectors as (0.2 , 0.8), where the constant introduced is 0.2. Let me introduce a new combination known as the NB-SVM algorithm. This is actually an SVM (Support Vector Machine) with Naive Bayes’ features. It creates a simple model variant where an SVM is built over NB log-count ratio “r” as feature values. The log form is an attempt to linearise the NB. Thus, in NB-SVM , the original features in the SVM, which are in vector form, are converted into a scalar by a scalar/dot product multiplication of each element with the log-count ratio ‘r’. (To know more about this variant in detail, please visit the amazing MOOCs from fast.ai). With this, we are slightly tweaking the prior probabilities to accommodate this more realistic situation. In the sense that, even if none of the “tokenized” negative words are found, the classifier will take another step of the dot product before classification, so that the classification is more accurate. The constant accounts for the “probability of the movie being bad , even if no negative word is found”.
Popular Variants of Naive Bayes Classifier
The conventional version of the Naive Bayes is the Gaussian NB, which works best for continuous types of data. The underlying assumption of Gaussian NB is that the features follow a normal distribution. The other variants which are discussed in this section are best used for text classification problems, wherein the data features are discrete. BernoulliNB is the Naive Bayes version similar to the one described in the “bag of words” type, wherein the features are vectorised in a binary fashion. Whereas, MultinomialNB is the non-binary version of BernoulliNB. As the word implies, Multinomial means “many counts”. Furthermore, ComplementNB implements the Complement Naive Bayes (CNB) algorithm. CNB is an adaptation of the standard Multinomial Naive Bayes (MNB) algorithm that is particularly suited for imbalanced data sets wherein the algorithm uses statistics from the complement of each class to compute the model’s weight. The inventors of CNB show empirically that the parameter estimates for CNB are more stable than those for MNB. Further, CNB regularly outperforms MNB (often by a considerable margin) on text classification tasks. Below is the comparison of test simulation results on each of these classifiers with the corresponding codes.

Inferences from the above are as follows:
- The features for the Iris dataset are largely continuous, i.e. the classification is done based on petal dimensions, hence GaussianNB is giving the best accuracy. Moreover, since the dataset is small, it is giving 100% accuracy!
- Binary vectorization is non-relational for this type of classification. Hence an abysmally low accuracy score for BernoulliNB !
- MultinomialNB is trying to classify by an assumption of discretizing the features. However, their dataset itself has only 150 feature combinations. Hence, in spite of it considering each of the dimensions to be a unique discrete feature, it is able to give a decent accuracy score. And lastly, ComplementNB is also not very relevant in this case but just used here for comparison purposes.
You can easily run this code on FloydHub with a single click of the below button.
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Summary of the predictions made by the classifier
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# Accuracy score
from sklearn.metrics import accuracy_score
print('accuracy is',accuracy_score(y_pred,y_test))
# Bernoulli Naive Bayes
from sklearn.naive_bayes import BernoulliNB
classifier = BernoulliNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Summary of the predictions made by the classifier
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# Accuracy score
from sklearn.metrics import accuracy_score
print('accuracy is',accuracy_score(y_pred,y_test))
# Complement Naive Bayes
from sklearn.naive_bayes import ComplementNB
classifier = ComplementNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Summary of the predictions made by the classifier
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# Accuracy score
from sklearn.metrics import accuracy_score
print('accuracy is',accuracy_score(y_pred,y_test))
from sklearn.metrics import accuracy_score, log_loss
classifiers = [
GaussianNB(),
MultinomialNB(),
BernoulliNB(),
ComplementNB(),
]
# Logging for Visual Comparison
log_cols=["Classifier", "Accuracy", "Log Loss"]
log = pd.DataFrame(columns=log_cols)
for clf in classifiers:
clf.fit(X_train, y_train)
name = clf.__class__.__name__
print("="*30)
print(name)
print('****Results****')
train_predictions = clf.predict(X_test)
acc = accuracy_score(y_test, train_predictions)
print("Accuracy: {:.4%}".format(acc))
log_entry = pd.DataFrame([[name, acc*100, ll]], columns=log_cols)
log = log.append(log_entry)
print("="*30)
sns.set_color_codes("muted")
sns.barplot(x='Accuracy', y='Classifier', data=log, color="b")
plt.xlabel('Accuracy %')
plt.title('Classifier Accuracy')
plt.show()
Conclusion
So, I hope you got a good overview of the Naive Bayes classifier and I would strongly urge you to build your own classifier using the resources given in this article. This article (I believe) will have given you a good conceptual understanding of the classifier, so that you could build the classifier by applying your new knowledge. So congratulations, if you have reached this far, you have truly become a hero of Naive Bayes. You are no longer “Naive”!!
References
- James.G., Witten.D, Hastie.T.,Tibshirani.R.,(2017) An Introduction to Statistical Learning , with Applications in R . 2nd Edition. Springer
- Veritasium – YouTube channel
- fast.ai (Intro to Machine Learning - MOOC)
About Anand Venkataraman
Anand is in eternal love with the art of storytelling with data. He is a passionate data science trainer, researcher and student for life. He lives by the motto "I am not a professional who is learning, I am a student who is holding a full-time job to earn a living.'' He is actually happy with his personal and professional life. He always likes to explore innovative teaching methods and tries to employ the "Feynman's technique", wherein, he tries to explain complex concepts in simple, effective and innovative methods. His dream is to teach Data Science and Mathematics to school kids and help them find expression for their passion. His profile can be seen here.