Metrics on FloydHub


At FloydHub we offer cutting edge infrastructure for training your machine learning projects. These are highly tuned instances in the cloud that come pre-installed with the frameworks of your choice. With the machines running in the cloud it is critical to monitor them at training time to ensure you are making the best use of the hardware. And now you can do that with FloydHub metrics!
We are excited to launch two new features that gives you insights into your training process and monitor the actual hardware where the training is happening - all in real time.
Training Metrics
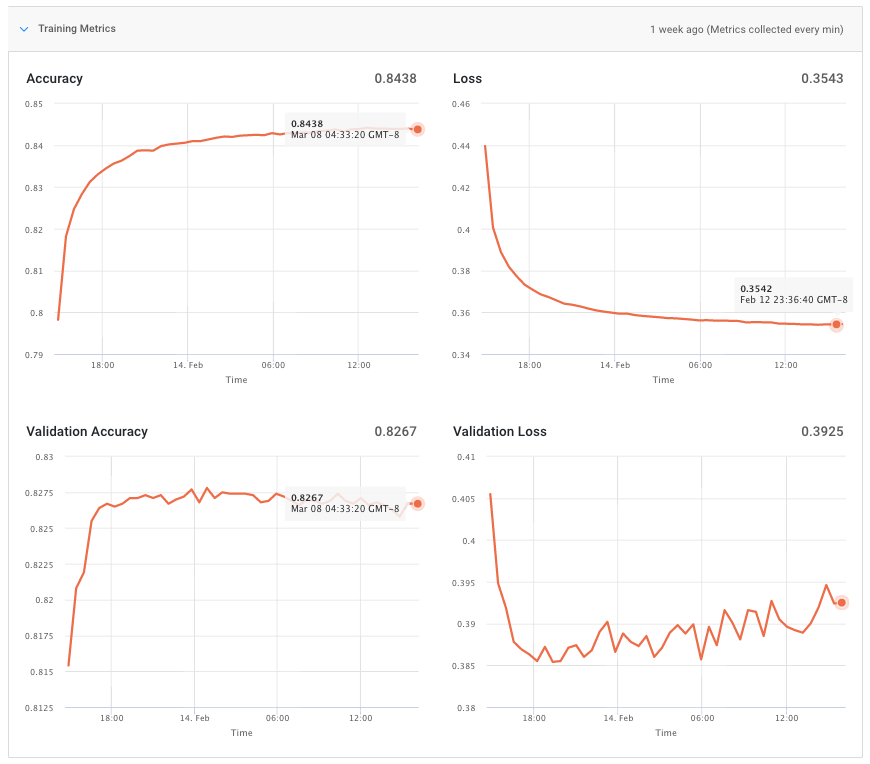
Training time metrics are values emitted by the training code that you can use to understand the performance of the model you are training. Metrics like training accuracy, loss and validation accuracy are often used for this purpose. The metrics could vary depending on your model and the framework you are using. But they give you a peek in to the model itself so it is important to track them in real time.
If you are running Keras jobs, you do not have to do anything to use this feature! FloydHub will automagically parse Keras logs and convert them into beautiful graphs that appear in the job page.
In case you are using a different framework, you can also send any numeric training metric by simply logging them in json format from your script. For example, in your training loop, you can print the accuracy and loss values in this format:
print('{"metric": "accuracy", "value": 0.985}')
print('{"metric": "loss", "value": 0.151}')
FloydHub will parse the output of your script and convert them into metrics. These metrics are updated in real time - once per minute. You can use this to determine if training is progressing as you expected. If not, you can stop the training job and try a different set of parameters.
Training metrics are kept as part of the job even after the job is finished and you can use them to compare models across multiple training jobs. This feature is very flexible and powerful and it should be useful for most of your training jobs. So try it in your next project!
System Metrics
Deep learning training consumes a lot of system resources like GPU, CPU and disk space. It is important to track the usage of all these critical resources to make sure that the training process is neither under-utilizing expensive instance resources nor running into bottlenecks and crashing the process. We are now launching a new feature that will provide this system information to you in real time.
The job page now contains a new section - System Metrics. It shows the resource utilization of the instance where your job is running in real time and updated every minute.
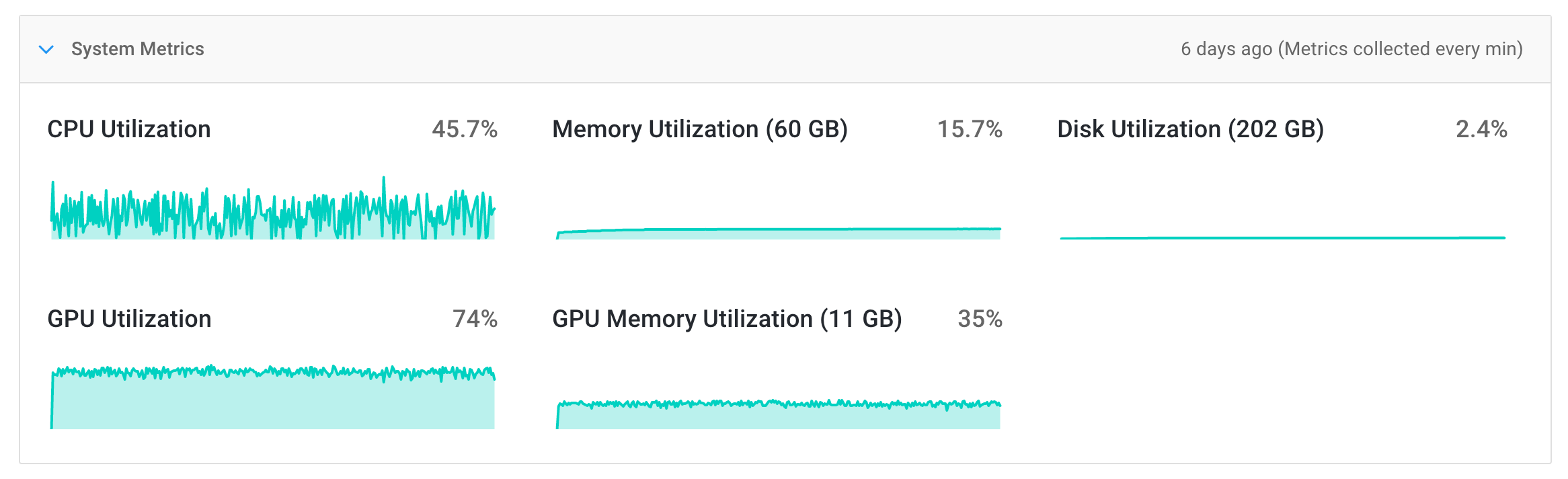
These graphs are timestamped and along with the training metrics, can be used to pinpoint issues in code that is causing resource exhaustion. On the other hand, if you notice expensive resources like GPU Utilization is not consistenly used, it is time to tune your training code and feed a larger batch size to your training code. You no longer have to wonder "Is my code using the GPU?"!
Metrics for Collaboration
If you are working with your Team on FloydHub, these metrics are a great way to share results and collaborate on the model. Graphs are much easier to absorb than log files and we have gotten great feedback from the teams who are using this feature.
Training and System metrics gives you confidence that your training code is best optimized for the instance and the training itself is progressing in the right direction. With these tools we believe that you can quickly iterate on your ideas and get to the best performing models as soon as possible!