Meta-Reinforcement Learning
The general trend in machine learning research is to stop fine-tuning models, and instead use a meta-learning algorithm that automatically finds the best architecture and hyperparameters. What about meta-reinforcement learning (meta-RL)? Meta-RL is just meta-learning applied to RL.


“we should stop trying to find simple ways to think about the contents of minds, such as simple ways to think about space, objects, multiple agents, or symmetries. All these are part of the arbitrary, intrinsically-complex, outside world. They are not what should be built in, as their complexity is endless; instead we should build in only the meta-methods that can find and capture this arbitrary complexity.” - Richard Sutton, The Bitter Lesson (March 13, 2019)
The general trend in machine learning research is to stop fine-tuning models, and instead use a meta-learning algorithm that automatically finds the best architecture and hyperparameters.
What about meta-reinforcement learning (meta-RL)?
meta-reinforcement learning is just meta-learning applied to reinforcement learning
However, in this blogpost I’ll call “meta-RL” the special category of meta-learning that uses recurrent models, applied to RL, as described in (Wang et al., 2016 arXiv) and (Wang et al, 2018 Nature Neuroscience).
Let’s get started.
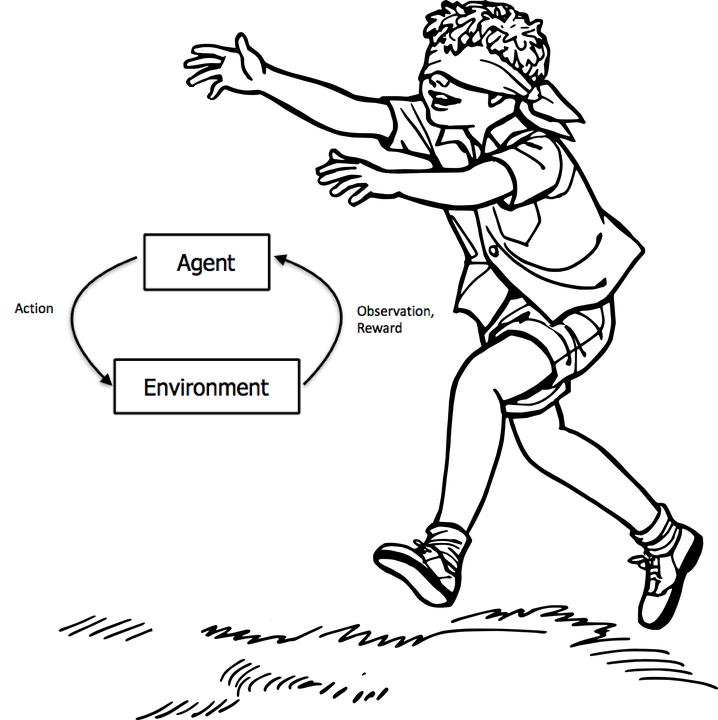
In reinforcement learning, an agent output actions at each step, such as “move left”, “move front”, etc. At each step, it receives observations (such as the frames of a videogame) and rewards (e.g. r=+1 if it does a correct action, r=0 otherwise).
The best way to understand meta-RL is to see how it works in practice. If you want to skip the examples, here is a short version:
- Train: Throw a bunch of problems with the same core structure to your model.
- Test: Your meta-RL agent is able to rapidly identify the key parameters of any new problem you throw at him, eventually achieving optimal performance on this new problem.
tl;dr: teach your meta-RL agent addition and negative numbers, then it will learn subtraction in a breeze, because he grasped the abstraction for manipulating numbers.
A simple example
Imagine being in an empty room with only two levers (facing what is called a multi-armed bandit problem).
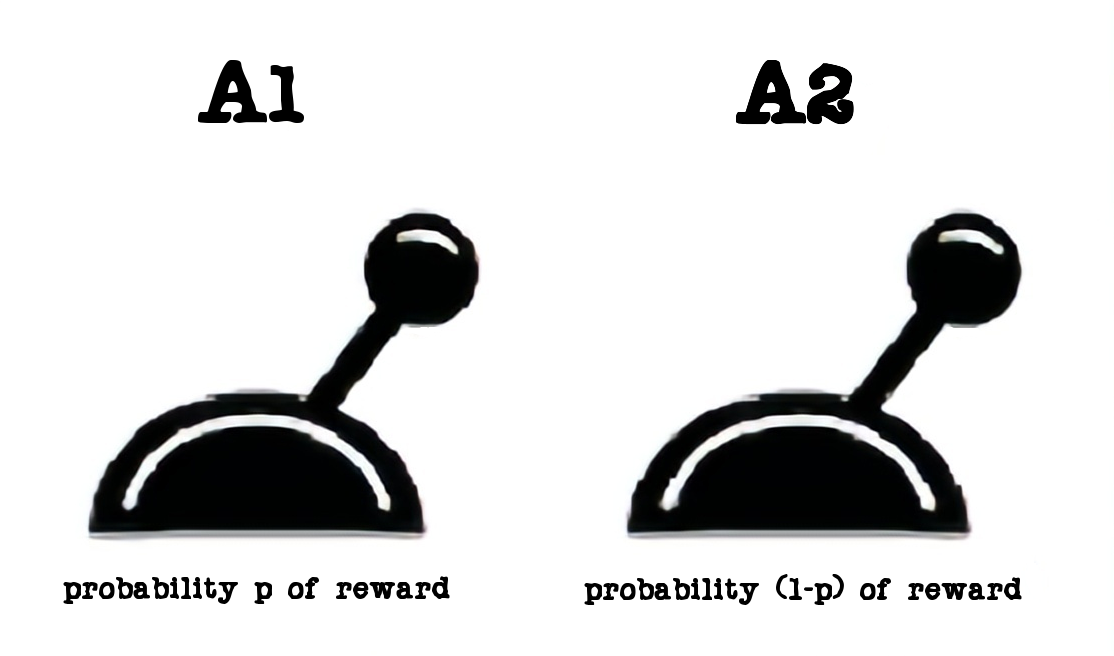
What do you do?
- Pull the left lever (action
A1), receiving a rewardr=1with probabilitypand no reward (r=0) otherwise? - Pull the right lever (action
A2), receiving a rewardr=1with probability1-pand no reward (r=0) otherwise?
Don’t think too hard on this one: to correctly answer you would need to know the value of p. For instance, p could be equal to“92%” (of chance of reward after doing A1), or p=0.92 for short.
And that’s exactly why meta-RL is interesting. If you throw enough two-levers problem (with different values of p) at your meta-RL model, it will get increasingly better at correctly estimating p using the couples (action, reward) it received from interacting with the environment.
For instance, if after repeatingA1for 100 trials you get 20 rewards, but you get 80 rewards by doing the same withA2, then it’s likely that the probability of reward from doingA1(p) is inferior to the probability of reward from doingA2(1-p), becauseA1led to rewards 20 out of 100 times, whereasA2led to rewards 80 out of 100 times.
In practice, the meta-RL agent trained on a bunch of two-lever problems is able to identify which one of the two levers leads to the highest reward using only the datapoints from a very small number of interactions. See below a comparison of a meta-RL agent before training (left) on an instance where p=0.92 and a trained meta-RL agent (right) tested on an instance where p=0.76.
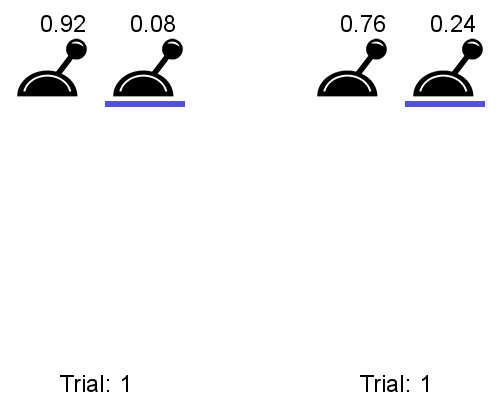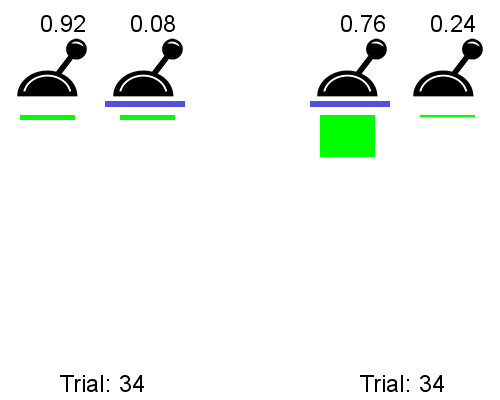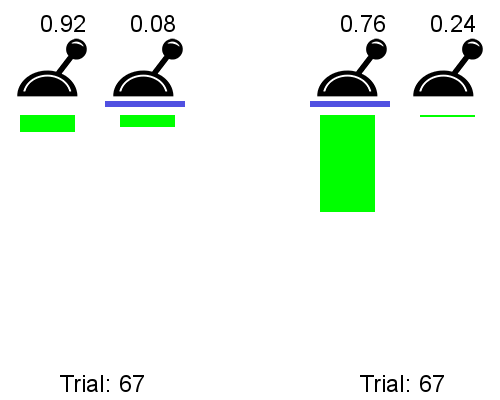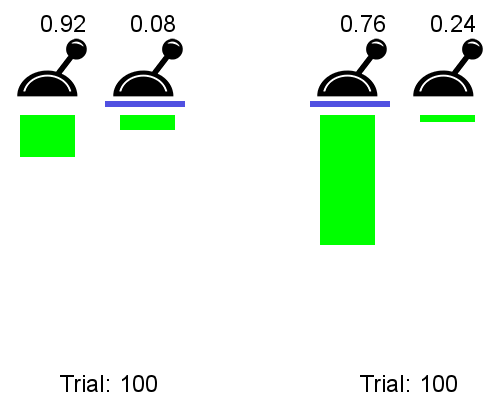
p=0.92 (left) vs. after training, p=0.76 (right); sourceThe trained meta-RL agent (right) is able to rapidly identify the high-probability-of-reward lever, accumulating lots of reward, whereas the untrained meta-RL agent acts randomly, receiving little reward.
Key takeaway: if we throw a bunch of two-levers-problem instances with different values ofpat our meta-RL model, it will become able to rapidly estimate thepof an instance, thus acting optimally on new instances.
Now that we have an intuitive understanding of meta-RL, we’ll go through two simulations described in Wang et al, 2018 Nature Neuroscience that I reimplemented:
- The two-step task (jupyter notebooks).
- The Harlow task (environment, tensorflow code).
The Two-Step Task
Reminder: In RL, an Agent interacts with its environment according to the diagram below.

For each timestep t, an agent must output an action a_t using as input:
- the state of the environment
s_t. - the reward
r_t(generated by the environment after the actiona_{t-1}).
We’ll call this loop (happening at each timestep t) a trial. To get a first grap of how the two-step task environment works, here is a gif of a meta-RL agent interacting with the environment for 100 trials (what we’ll call later an episode).

More precisely: the agent observes the different (perceptually distinguishable) states: S1, S2 and S3 (upper nodes of the gif above). For each trial, the meta-RL agent chooses between actions a1 and a2 in an initial state S1 (the green arrow below S1 represents the chosen action). If that helps, you can think of a1 and a2 as the two levers from the simple example above.
When the agent does a certain action, say a1, it will likely (80% of the time) end up in a certain state (e.g. S2 if action a1 was chosen). At the end of a trial, it either gets a positive reward(r=1) or it doesn’t get reward (r=0). Depending on the state, the probability of getting a positive reward can be high(p=0.9) or low(p=0.1).
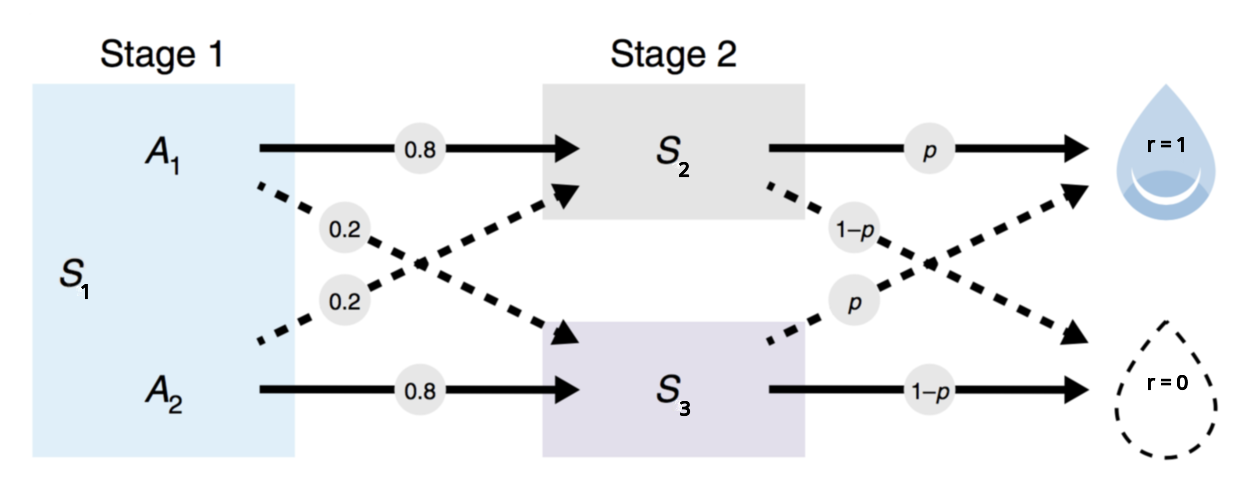
However, the probabilities of getting a reward are not fundamentally attached to a state. Indeed, every trial, there is a one in a forty chance (p_switch=0.025) that the often-rewarded state and rarely-rewarded state will switch (e.g. if the often-reward state was S2 before the switch, the often-rewarded state will be S3 after the switch).
This switch actually matters in this setup because it slightly changes the odds of receiving a reward for a given action. Indeed, for every switch we only swap the probabilities of receiving a reward for S2 and S3. Therefore, the agent alternates between two tasks which have the same core structure (the one where S2 is the often-rewarded state, and the one where S3 is the often-rewarded state).
For example, in the gif below, S3 if the often-rewarded state for trials 7-9. Then, at trial 10, the probabilities of reward switch, so S3 becomes the rarely-rewarded until a last switch at trial 26.
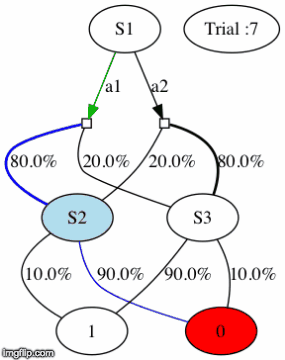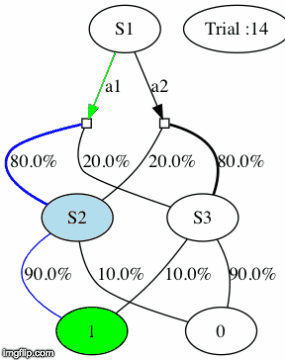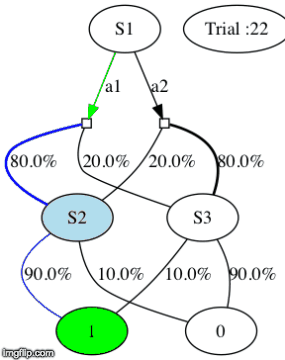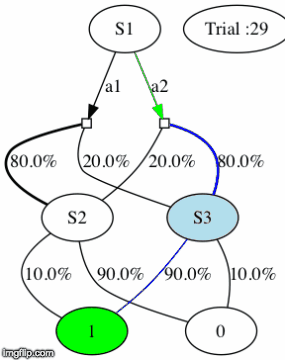
IMPORTANT NOTE: the agent choosing at each trial between action a1 and a2 does NOT know what is the often-rewarded state. Its only way of accessing this information is the result of its actions at each trial. For example, if after consistently choosing a1 (which leads to ending up in S2 with probability 80%) for 10 trials in row, the agent received 10 positive rewards in a row (r=1 at the end of each trial), then S2 is very likely to be the often-rewarded state.
For this task, the main variable (i.e. the analog for p from the simple example) comes from the uncertainty associated with answering the following question:
what is the often-rewarded state?
In short, if an agent is capable of correctly determining which state is the often-rewarded state (for instance it correctly estimates that the often-rewarded state is S2), then the best policy is trivial: just choose the action that often goes to this often-rewarded state (if the often-rewarded state is S2, then do a1).
Model-based vs. model-free
Intuitively, an agent for to the two-step task should be able to:
- understand that there is a probability that the often-rewarded state can be either
S2orS3, and that this can switch at any moment. - update its beliefs at each trial concerning which state has the highest probability (between
S2andS3), showing adaptative skills.
To put it in a nutshell, to solve the two-step task it would need a model of the environment.
In RL, algorithms that don’t build a model of the environment are called model-free, and are often compared to other algorithms that do require a model of the environment, or model-based [in practice, the distinction between model-free and model-based is quite subtle, especially when the system has memory].
For instance, your brain uses model-free RL when responding conditioned on (predictive) value of stimulus (e.g.Pavlov’s dogs) and model-based RL when playing videogames (because it must interact with a model of the videogame in your head before taking any motor decisions).
This distinction between model-free and model-based is central to meta-RL:
meta-RL uses a model-free algorithm and exhibits model-based behaviours (!)
The stay probability
We have previously talked about the crucial distinction between model-free and model-based. To understand the results of the two-step task, it’s essential to be able to measure or at least be able to qualitatively interpret the differences between these two. But first, let’s refresh our memories about what the two-step task setting looks like, by looking at the diagram below:
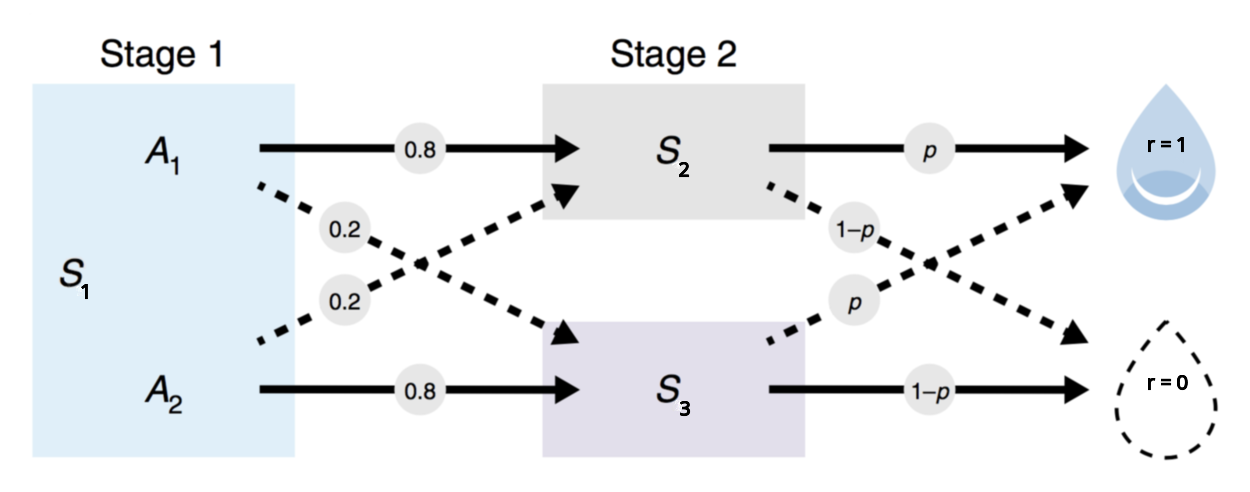
The key metric for the two-step task is the stay probability, i.e. the probability of repeating the same action after having received some reward. A useful way to look at this stay probability is by observing the difference between the probability when the last transition was common (e.g. arriving in S2 after a1, normal) or uncommon (e.g. we choosed a1 and, surprise, we ended up in S3).
To better understand this stay probability, let’s try to interpret the diagrams below:
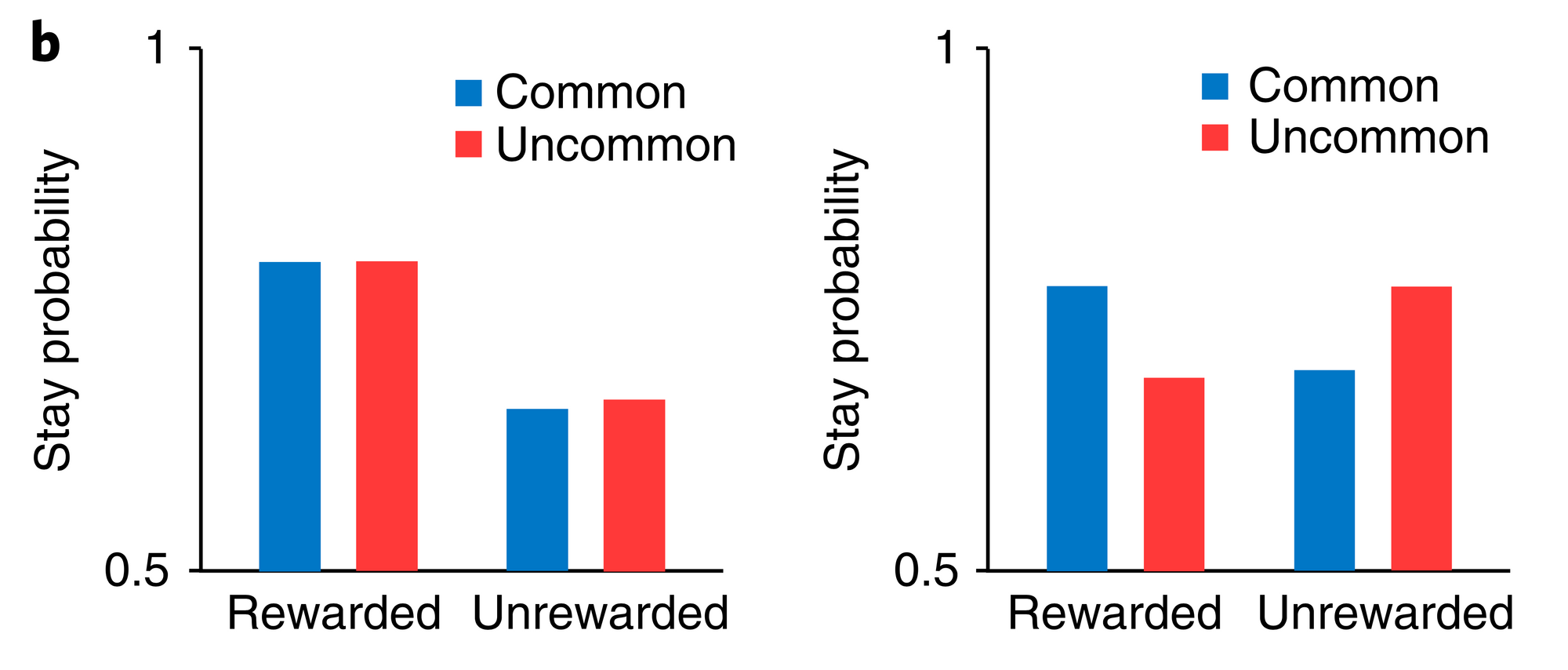
An intuitive way to look at those diagrams it to think about what we do as humans:
- The default behaviour (when we’re tired, in automatic mode) is to repeat the same action if it leads to some positive reward (e.g. if I ate sugar and my brain was like ‘that’s pretty good’, I’ll continue eating sugar). This corresponds to the diagram on the left (see above), and is related to what we called previously model-free (i.e. just repeat the action without building any model of how the world works).
- If your brain is able to differentiate between common and uncommon transitions (for example by only repeating rewarded actions if the reward arised from a common transition), then it implements some model-based algorithm. For instance, if a good night of rest often (80% of the time) brings you joy, you would often repeat it (stay probability > 50%). If watching Youtube videos brings you happiness only 20% of the time, the happiness comes from an uncommon transition, so you would avoid it.
Now, let’s see how we can apply this knowledge to reproduce the two-step task results from Wang et al, 2018 Nature Neuroscience.
Lessons From Reimplementing the Two-step Task
Goal
Teach a meta-RL agent to solve the two-step task.
Code
We’ll be using this code. Check out the README.md for specific instructions. The most important notebook is the biorxiv-final.ipynb jupyter notebook. Please choose Tensorflow 1.12 and CPU.

Architecture
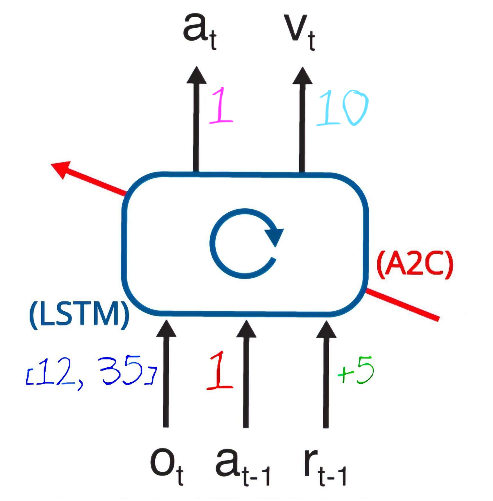
Before I unveil the full meta-RL API, a quick reminder about how the agent-environment interface looks like in RL:

At the beginning of the section “two-step task”, I already introduced a very similar agent-environment interface. The only difference is in wording: from here onwards, we’ll talk about the “observation” (o_t) of the state, instead of the “state” (s_t) itself.
And now, the showstopper:
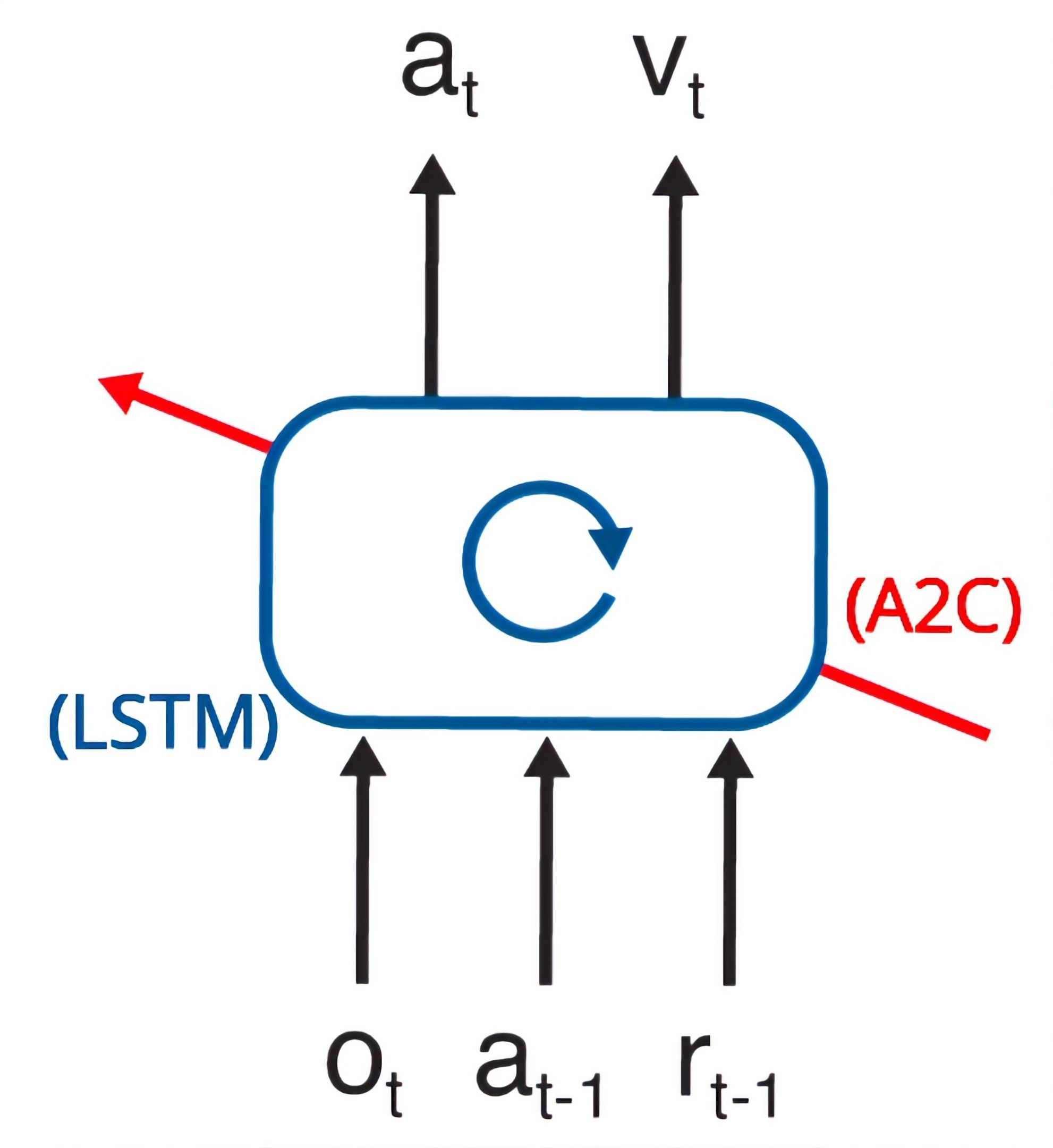
If you look at it for the first time, it seems difficult to understand. Let’s unwrap this with the key below:
Inputs
o_t: observation for the current timestep.a_{t-1}: action from the previous timestep.r_{t-1}: reward from the previous timestep.
Outputs
a_t: action for the current timestep.v_t: estimate of the accumulative reward given that the agent is in this state at timestep t.
LSTM
It’s the type of our neural network. In TensorFlow, it’s already implemented (and super optimized), so we’ll use it as a black box without thinking too hard about it.
However, if you want to learn how it is working underneath I strongly recommend you to read this article.
A2C
Short name for Advantage Actor Critic, what we’ll use to train the meta-RL model using the previous observations, actions and rewards. A useful way to think about A2C is as part of a broader class of algorithms in RL, called Actor Critic algorithms, where a neural network outputs both an actor and a critic:
- The actor outputs the action for the current timestep (
a_t). - The critic criticizes what the actor is doing, by estimating the value of the states he ends up in after his actions, outputting an estimated value of the current state (
v_t).
Example
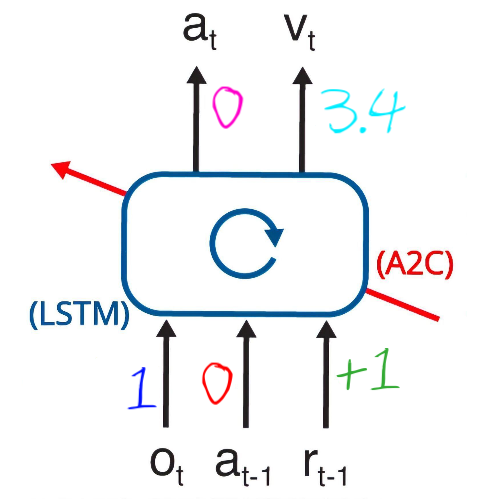
Let’s suppose that, last trial, the agent chose the action a_{t-1}=a1, ended up in S2, and received a reward of r_{t-1}=+1 (S2 was the often rewarded state). Therefore, we’ll feed to the network a_{t-1}, r_{t-1} and o_t=S2, because the network must understand that he received this particular reward (r_{t-1}) because of its action (a_{t-1}) and the state it ended up in after a_{t-1} (S2).
Using those inputs and the hidden states/weights of the LSTM, the actor (in A2C) estimates that the best action (for the current trial) is to keep doing a_t=a1 and the critic estimates the situation with a value (for instance 3.4).
Mapping states and actions to integers (in our code, o_t=S2=1 and a_{t-1}=a1=0), we get the following diagram:
Results
Stay Probability See below the evolution of the stay probability during 20k episodes of training (code):
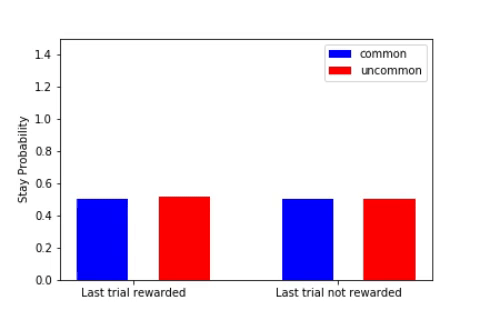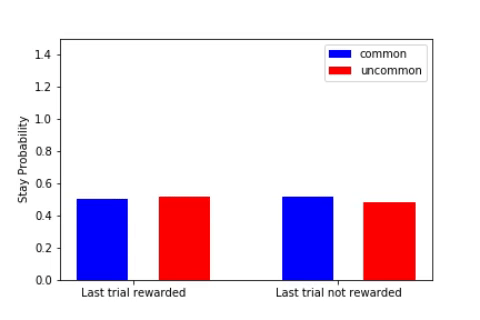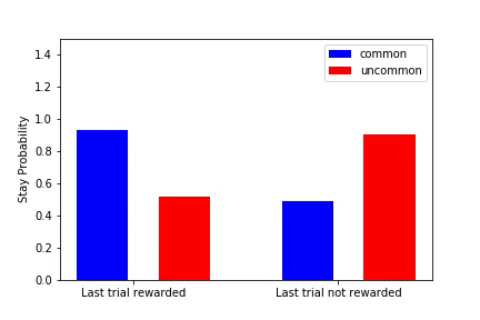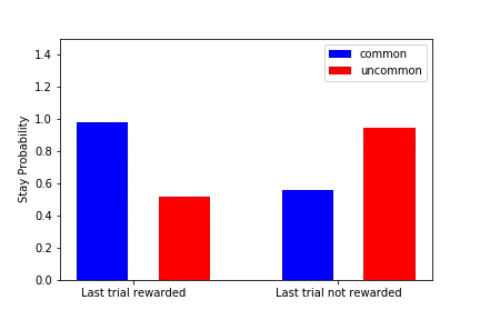
The stay probability starts at 0.5 for all transitions (see the gif when the plots are all flat). At the end of his training, the agent exhibits a model-based behaviour (cf. the canonical model-based plot on the right).
In short, our meta-RL agent learned the strategy leading to the highest expected reward.
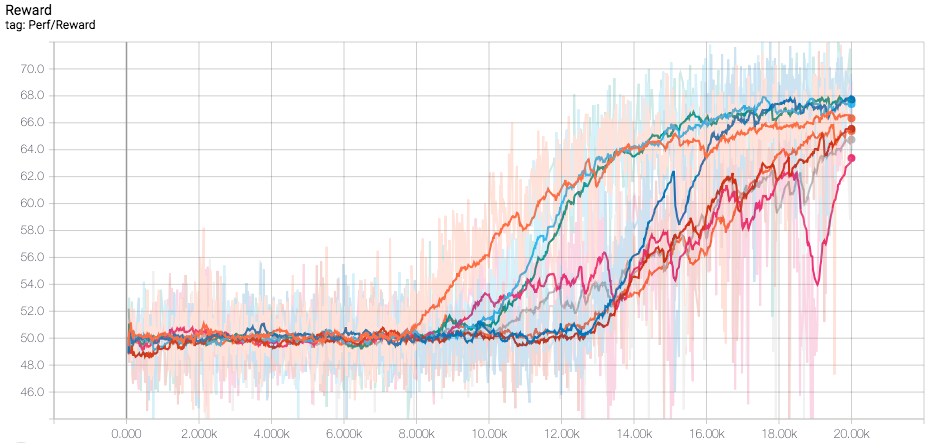
Reward Curve The most important thing to check when launching RL trainings is your reward curve. With TensorFlow, you can plot it using Tensorboard. FloydHub automatically detects your Tensorboard data, so to plot your reward curve you just have to click on the TensorBoard link (inside the blue dashboard bar at the bottom of the screen)!

We ran 8 trainings (one for each seed (=random number generator)) to test for robustness.
Lessons
- Unlike traditional Machine Learning algorithms, with meta-Reinforcement Learning the algorithm is stuck at 0% performance for the first 8-12k episodes. Therefore, you might spend countless hours (> 4 hours for the two-step task on CPU) stuck at 0% performance, without knowing if the model is learning or not. My advice: a) ask yourself “if my experiment went wrong, what was my mistake?” b) try to log as precisely as possible the details of your experiments (the date, the time, the goal, the reason why it might not work, the estimated training time, etc.)
- Meta-RL appears to be similar to how children learn things: we either don’t know at all how to do something, or we know exactly how to do it. In the above graph, we observe the same dynamic through a S-shaped/sigmoid-like curve: the meta-RL model “understands” the task at some point between 8-12k episodes, and from that point onwards it keeps making progress on the task.
The Harlow task
Let’s try to apply meta-RL to a classic psychology experiment, the Harlow task:
- At each step (or trial), an agent gets to choose between two objects randomly placed in left-right positions, but only one is rewarded.
- Every six trials (what we’ll call an episode), we replace the two objects with two new objects.
- We measure how many rewards the agent receives per episode.
This experiment was originally tried on monkeys:
- In the beginning, monkeys act indifferently towards rewarded and unrewarded objects.
- After experimenting with a few hundred couple of objects (i.e. after a few hundred episodes), monkeys eventually understand the underlying structure of the task.
- Henceforth, they perform optimally on the task, always choosing the rewarded-object after the second trial (for the first trial they’re bound to “guess” what the rewarded object is, because they still haven’t received any reward).

{kind=link}
“A key component of this task is that the objects are completely new at the beginning of the episode, and would randomly switch left-right positions from trial to trial. So the ‘rule’ to learn is that position is meaningless, it’s only the identity of the object that’s related to reward.” - Jane Wang, co-author of Prefrontal Cortex as a Meta-Reinforcement Learning System, private communication.
For this task, we’ll be using DeepMind’s customisable 3D platform for agent-based AI research: DeepMind Lab. In particular, we’ll be using the Harlow Task environment, which is part of a larger open-source set of environments to replicate psychology experiments: Psychlab.
Below, what the agent sees in DeepMind’s environment for the Harlow Task (source). The agent is “shaking” because for each trial it must:
- target the red fixation cross
- target the center of an image.

Lessons From Reimplementing the Harlow Task
Goal
Reproduce the results from the Harlow task simulations using DeepMind Lab.
Code
We’ll be using this code. Check out the README.md for specific instructions. The code specific to meta-RL can be found here (it’s a submodule from the main repository). Please choose Tensorflow 1.12 and CPU.
Input
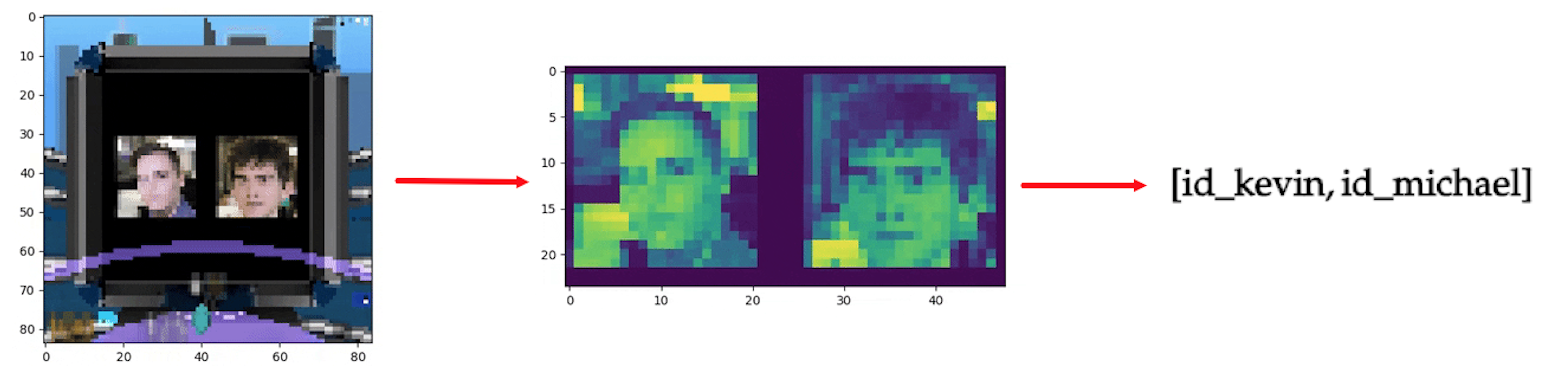
At the beginning of each episode, we sample two images (with replacement) from a set of 42 images of students from 42 (to tweak the dataset to your own needs, see here).

We resize the images to 256x256, and feed them to the Harlow task environment, using a 84x84 window size for the agent’s input.
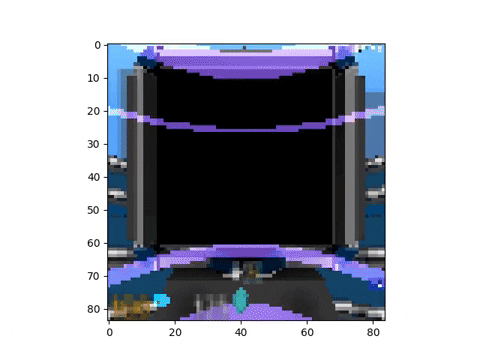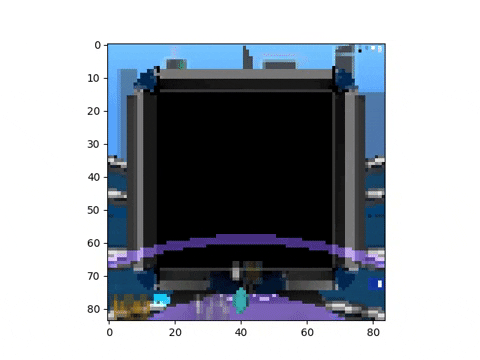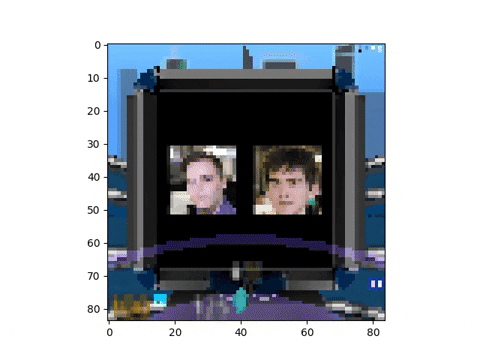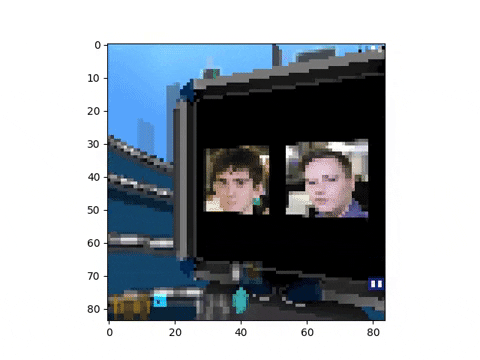
Additionally, we pre-process the observations to make the input as small as possible, using padding and grayscale. See below the pre-processed input:
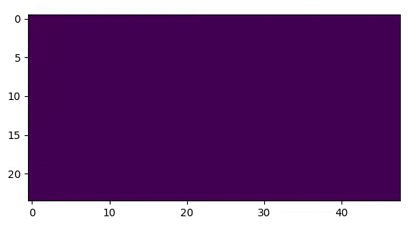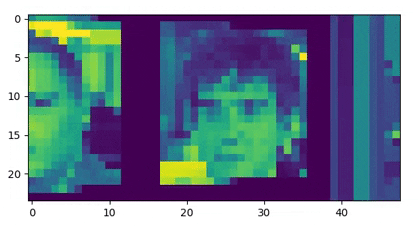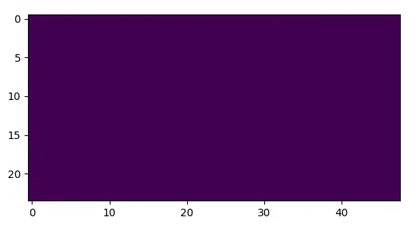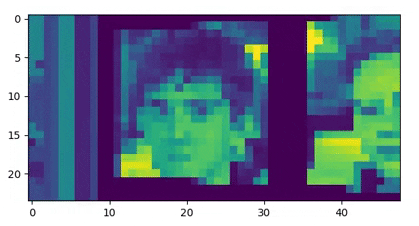
Then, we compute the average value of the pixels of the left image (idem with the right image). If it’s the first time that this average was encountered, we choose a new unattributed id (0 <= id < DATASET_SIZE = 42) for this average. Because one average corresponds to one image, we get a unique id for each image (we handle the fact that as the agent swivels the pixels change by only considering the first frame of a trial for our id).
Architecture
We used the same architecture as in the two-step task, the only difference beeing in the observation o_t. Let’s make that more clear with an example. Let’s suppose that:
- The current observation is
o_t=[id_kevin, id_michael], for instanceo_t=[12, 35](in practice, we fed one-hot representations of those ids, but let’s keep[12, 35]for simplicity). - Last trial, the meta-RL model outputted the action
a_{t-1}=RIGHT(encoded by the integer1). In other words, the meta-RL chose the right image. [Note: the agent only does one action per trial, the reverse action to come back to the center of the screen is automatic in our wrapped environment.] - Last trial, the image on the right was the rewarded one. Hence, last trial, the agent received the reward
r_{t-1}=+5after his actionRIGHT. - With those inputs, and the current states and weights of the LSTM, our model estimates that the best action (for this observation) is
a_t=1(i.e. choosing actionRIGHT) and that the expected value of the current state isv_t=10.
Results
Here is the reward curve for 5 different seeds (one color per seed) after ~10k episodes(which took approximately 3 days to train) on FloydHub's CPUs(one CPU per seed):
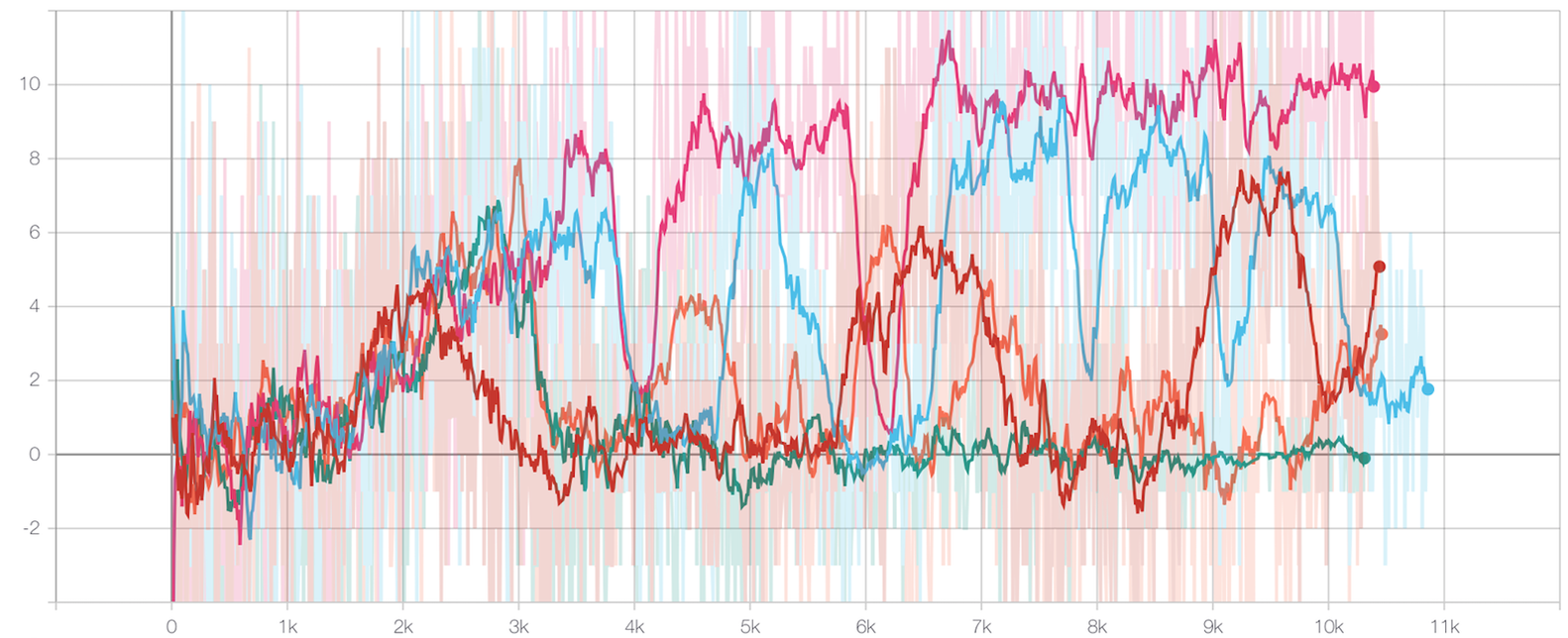
- As with the two-step task, all seeds spent the first ~1k episodes at 0% performance.
- The green seed stayed at 0% performance. The orange, red and blue seeds achieved peak performance of respectively 6, 8 and 10 rewards per episode, but the training was really unstable. However, the pink seed generated more and more reward, until eventually reaching a threshold (around 40% performance for the pink seed) after ~7k episodes.
- It looks like the performance might still possibly increase for some of the seeds. We haven’t tried to run it for longer because the asymptote at
r=10seemed daunting.
Lessons
- Multi-threading. Before we launched our trainings we thought that, becauseTensorflow was built for multi-threading (and our code supported multi-threading), everything would run smoothly. It turns out that DeepMind Lab’s Python API uses CPython, so we could not multi-thread using (normal) tensorflow, because of the global interpreter lock. You can learn more about multi-threading, here.
- Multi-processing. After learning about this global interpreter thread, I implemented multiprocessing using Python’s library multiprocessing. However, it appeared that Tensorflow doesn’t allow to use multiprocessing after having imported tensorflow, so that multiprocessing branch came to a dead end. We also tried multiprocessing with ray another multiprocessing library. However, it didn’t work out because DeepMind was not pickable, i.e. it couldn’t be serialized using pickle. You can learn more about multi-processing, here.
- Tweaking hyperparameters. After giving up on multi-threading/-processing, we decided to see if our model would learn something if we drastically reduced the action space and fed only very simple inputs (cf. the section “Input” above). Thus, we ended up running experiments with only one thread, a 48 units LSTM and a very simple input. Eventually, we got something that reached an average reward of ~10 (about half of the maximum performance, cf. “Results”). Our best guess is that 48 units was not enough to learn the task, but maybe it was the mono-thread or something else in our code. In short, always change one hyperparameter at a time, otherwise you end up not knowing at all why you’re model is not learning.
For a detailed account of the on-going projects, the tensorflow code or just more reward curves make sure to check out the meta_rl repository!
To wrap it up, our meta-RL model achieved optimal performance on the two-step task and 40% performance on a simplified version of the Harlow task.
In the following section, we’ll see how our brain could implement meta-reinforcement learning.
Prefrontal Cortex as a Meta-RL System
Machine Learning in the Brain
Multiple models of how the brain implements reinforcement learning exist. For instance:
- see this paper for a precise account of the integration of deep learning and neuroscience.
- see this paper for why ideas in RL “provide a normative framework within which decision-making can be analyzed”.
To get a feel of the brain architecture, let’s look at the diagram below.
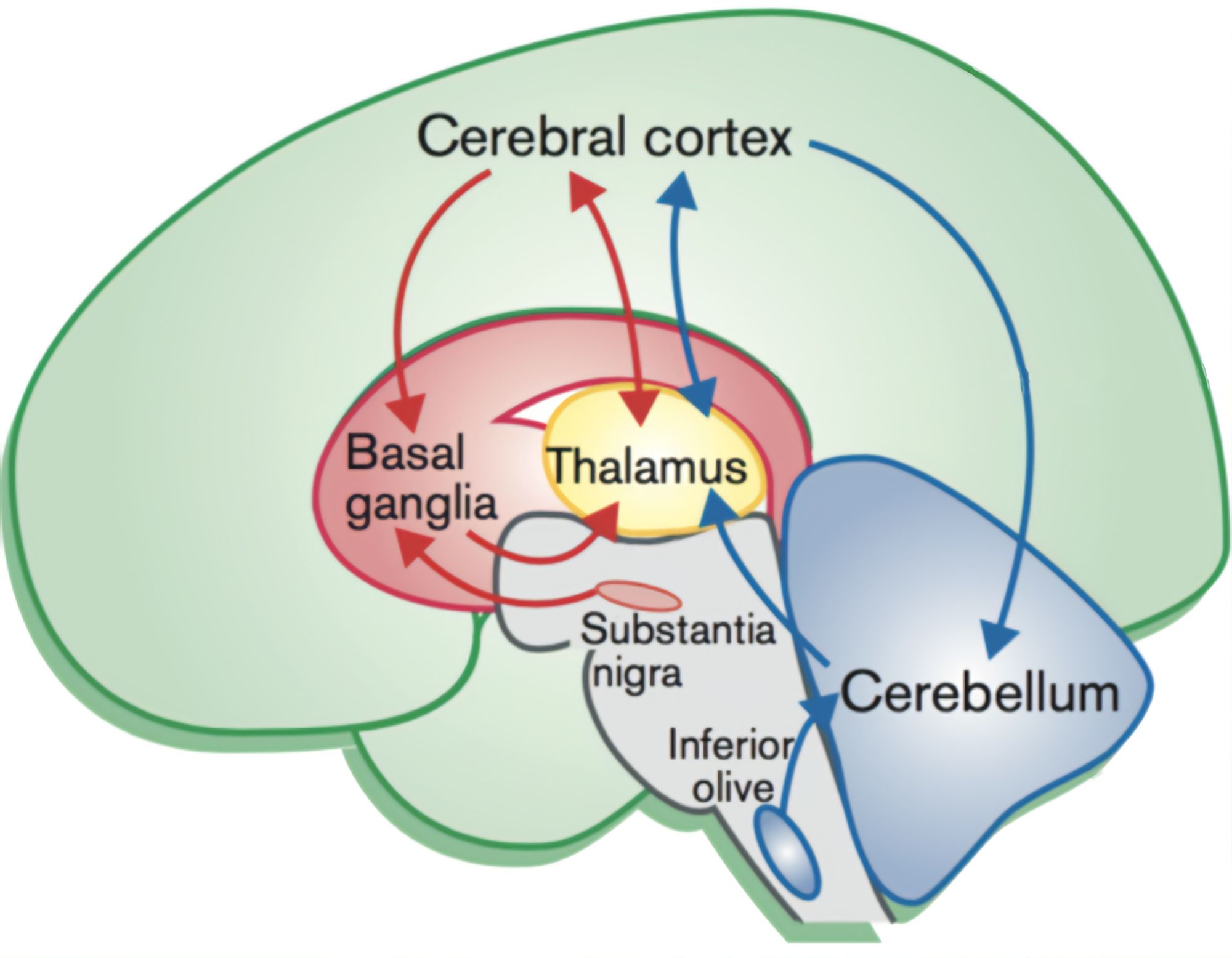
The relevant parts for meta-RL are:
- The basal ganglia (or lizard brain), which contains, among other things, the VTA and the substantia nigra, where dopamine is produced.
- The prefrontal cortex (part of the cerebral cortex), or your “rational decision-maker trying to get you to do your work”.
The Pivotal Role of Dopamine
The brain maximizes some reward function, thus implementing something close to reinforcement learning. Yet, let’s not forget that these rewards must be implemented on biological hardware. In practice, dopamine neurons carry reward prediction errors through special highways called dopaminergic pathways.
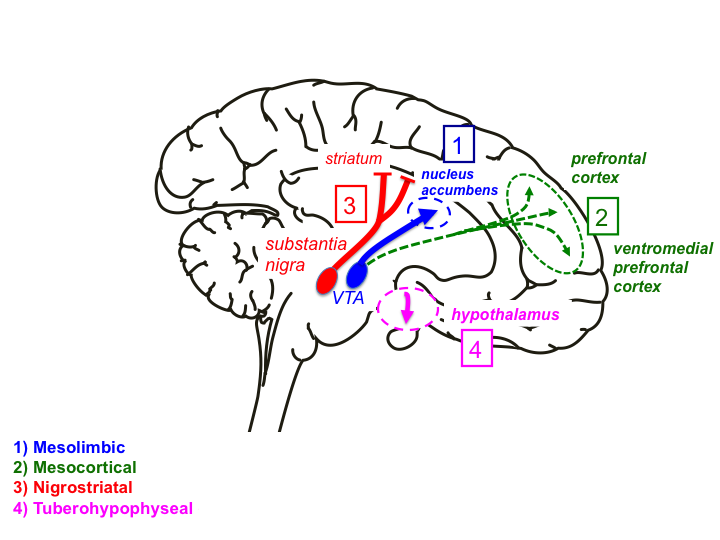
“Reward prediction errors consist of the differences between received and predicted rewards. They are crucial for basic forms of learning about rewards and make us strive for more rewards—an evolutionary beneficial trait. Most dopamine neurons in the midbrain of humans, monkeys, and rodents signal a reward prediction error; they are activated by more reward than predicted (positive prediction error), remain at baseline activity for fully predicted rewards, and show depressed activity with less reward than predicted (negative prediction error).” - Wolfram Schultz, Dopamine reward prediction error coding
Reward prediction errors inspired a whole class of model-free reinforcement learning algorithms called Temporal Difference methods, one of them being A2C!
Model-free vs. Model-based
Dopaminergic processes have traditionally only explained slow, model-free learning, whereas the prefrontal cortex is often associated with model-based learning.
However, the prefrontal cortex uses a history of all previous rewards (stored as long term memory) to output decisions, much like a LSTM. Thus, if we replace meta-RL’s LSTM with the prefontal network (PFN) - which corresponds to prefrontal cortex + basal ganglia + thalamus - and A2C with dopamine (DA on the diagram below), we can model the interactions PFN-DA with the same diagram we used for the meta-RL API:
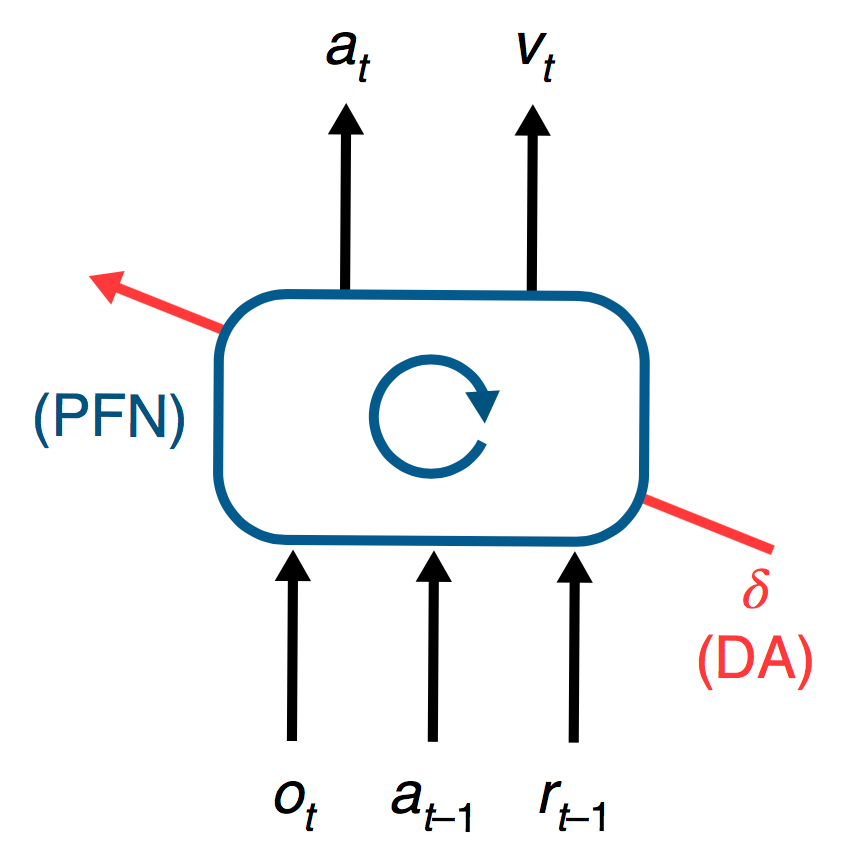
Therefore, the model-based RL in the PFN might just be the observed behaviour of some model-free temporal difference method that uses reward prediction errors (e.g. A2C), executed by dopamine.
In fact, this is exactly the model-based behaviour we observed when we trained our meta-RL model on the two-step task using A2C.In other words, high-level decision-making might just be an emergent phenomenon happening because of some model-free dopaminergic sub-processes.
Thanks to Yasmine Hamdani (resp. Kevin Costa) for helping me debug the code for the two-step task (resp. Harlow task), Jane Wang for all the additional details about the Harlow task and the valuable neuroscience feedback, Arthur Juliani for his code and blogpost on meta-RL, Emil Wallner for the countless coffee breaks discussing meta-RL, Charlie Harrington for his down-to-earth feedback, Jean-Stanislas Denain for making sure everything was scientifically sound, Maxime Choulika, Tristan Deborde and Igor Garbuz for making sure I was being extra clear and all the FloydHub team (Sai, Naren and Alessio) for their support and for letting me run my trainings on their servers.
If you want to cite an example from the post, please cite the resource which that example came from. If you want to cite the post as a whole, you can use the following BibTeX:
@misc{metarlblogpost,
title={Meta-Reinforcement Learning},
author={Trazzi, Michaël},
howpublished={\url{https://blog.floydhub.com/meta-rl/}},
year={2019}
}
FloydHub Call for AI writers
Want to write amazing articles like Michaël and play your role in the long road to Artificial General Intelligence? We are looking for passionate writers, to build the world's best blog for practical applications of groundbreaking A.I. techniques. FloydHub has a large reach within the AI community and with your help, we can inspire the next wave of AI. Apply now and join the crew!
About Michaël Trazzi
This is the second post in a series of articles by Michaël Trazzi documenting his journey into Deep Reinforcement Learning. You can read his first article here. Michaël codes at 42 and is finishing a Master's Degree in AI. He's currently exploring the limits of productivity and the future of AI. Michaël is also a FloydHub AI Writer. You can connect with Michaël on Twitter, LinkedIn, Github and Medium to stay up to date with his latest blogposts.