Distilling knowledge from Neural Networks to build smaller and faster models
This article discusses GPT-2 and BERT models, as well using knowledge distillation to create highly accurate models with fewer parameters than their teachers


Not every smartphone owner carries around a high-end GPU and a power generator in their pockets. For most practical situations, we need compact models with small memory footprints and fast inference times.That said, you might have noticed that many recent advancements in Deep Learning are all about scaling up our models to gargantuan proportions. How can we take advantage of these new models while remaining under reasonable computing constraints?
There are many ways to tackle this issue, but in this article we’ll focus on one in particular: knowledge distillation. Many ideas in this article are taken from the paper Distilling Task-Specific Knowledge from BERT into Simple Neural Networks, especially the choice of student model I will train, the choice of dataset and the data augmentation scheme.
How are the new models better than the old ones?
Disclaimer: I’m going to work with Natural Language Processing (NLP) for this article. This doesn’t mean that the same technique and concepts don’t apply to other fields, but NLP is the most glaring example of the trends I will describe.
It’s not directly obvious why scaling up a model would improve its performance for a given target task.
Let’s take language modeling and comprehension tasks as an example. The most prominent models right now are GPT-2, BERT, XLNet, and T5, depending on the task. For the sake of simplicity, we’ll focus on the first two, as XLNet is an improved version of GPT-2. I’ll make a quick recap, but if you want to delve into the details you can check GPT-2 and BERT.
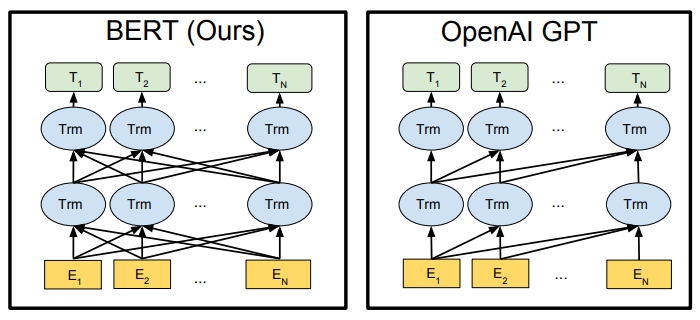
BERT: State-of-the-art in language comprehension tasks like GLUE, after T5. It’s a model based on the Transformer. Network instances running on each word can access information from other words, a concept called Attention. Information can be accessed both ways: words before, and words after.
GPT-2: Contends state-of-the-art with XLNet on language generation tasks, depending on the length of the previous context. It also uses Attention, but each instance can only access information from the words before. This makes it possible for it to work in a generative context, where the following words are unknown at inference time, but hinders its performance at language comprehension compared to bidirectional models.
T5: State-of-the-art model for many benchmarks, including GLUE. Result of an extensive study that analyzed the contribution of techniques from all over the field. Uses the original encoder-decoder formulation of the Transformer from the original paper Attention Is All You Need, coupled with a generalized training objective that can be adapted to many different downstream tasks. Every different task is formulated as a text generation task, so that the network can be trained on different tasks at the same time, with the same loss function. For example, sentence classification can be formulated as:
- Input: “sst-2 classify: This movie tries way too hard”
- Label: “target: negative”
Now that I’ve introduced the topic, let’s get back to the matter of scaling things up.
If you’re training a certain network architecture on GLUE’s tasks and you want to get the best possible performance, you can scale up the network, but eventually you’ll hit a ceiling. There will be a point where you just need more labeled examples or else your network will overfit on the training set.
You can gather up more labels, but no matter how much you invest in gathering data you’ll get ever-diminishing returns.

This dilemma was solved by training on language modeling, that is, predicting the next word in the sentence (GPT-2) or reconstructing masked tokens (BERT). This is done using unsupervised learning: you can construct labels for these training objectives from raw text.
We can, therefore, scrape the internet for huge amounts of text and train the largest neural networks to date.
The result is a neural network that can achieve SOTA results on a wide range of downstream tasks, like the GLUE benchmarks, with very little additional training. We refer to this second training stage as fine-tuning. The drawback is that these models are so large that it’s not feasible to run them on user devices. Just the parameters of the largest released version of GPT-2 will occupy 1.5 GB of your storage! They also require too much time to run without a high-end GPU and will consume your phone’s battery in no time.
How can we make them smaller?
Sparse predictions are more informative than hard labels

When language models are trained on raw data, hard labels are used. These labels are vectors with a 1 in the position corresponding to the true class, and 0s everywhere else. They represent a probability distribution where the corresponding word has a 100% probability of being the true class.
This type of label can be made directly from raw text. After seeing a lot of examples, the network can act as a maximum likelihood estimator, but it needs to be exposed to many examples before it can assign good probabilities, as the labels it sees are samples from a distribution with extremely high variance. Or, to say it in a more straightforward way, natural language is very unpredictable.
For example, in the sentence above, the network needs to see examples of different grammatical configurations that exist in English for using the verb “to jump”, in order to learn all the ways the verb can be used:
- Jump over
- Jump to
- Jump the fence
- Jump 42 times
If only we had a pretrained model that is extremely good at estimating probabilities for the next word and could encode all this information in the label… ;)
If you’ve done transfer learning before, you can see where this is going.
The big idea is:
We can take a large pre-trained model like BERT, called the teacher, fine-tune it on the target task if it differs from the pre-training task, use it to predict the probabilities for our data, then use the probabilities as “soft labels” for the target model, the student. This way we can communicate the target distribution to the network with fewer examples!
This also corresponds to training a student to reproduce the behavior of the teacher as accurately as possible, but with fewer parameters.

The researchers at huggingface took advantage of these last two ideas to train two networks, DistilBERT and DistilGPT-2, that maintain a performance very close to that of their teachers while being half the size.
The networks were trained to output the same probabilities as their larger versions, but in order to reach these amazing results, they had to take advantage of some peculiarities of the network architectures:
- The smaller models are composed of the same basic blocks as the teachers, but with fewer layers
- Transformer models make use of residual connections: while for most models there is no guarantee that representations from different layers share any similarities, Transformer layers work by adding to their input vectors. This means that outputs from different layers are very similar to the initial word embedding, each layer changing them as little as it’s needed to encode useful information in them.

This allowed the researchers to initialize the layers of the distilled models to the same weights as some of the layers of the teacher model, or equivalently, pruning away the layers that weren’t carried over.
Potential for data augmentation
Most task-specific datasets are tiny compared to what it takes to train even a small NLP model to reach its optimal performance.
This is also related to how unpredictable language is if we consider it as a random distribution from which we can take samples. You can define the idea of a “sample” in multiple ways:
- Uncovering the next word in a sentence, knowing the words that come before it, or
- Uncovering the whole sentence at once
Either way, there are so many possible, valid or commonly occurring combinations of words that it makes it really hard to find a representative subset; that is, a subset on which we can train a model and expect it to have seen enough examples to perform well on data coming from outside of that subset.
Take these two phrases that could be found in a movie review:
- One of the most praised disappointments
- One of the most praised movies
If you had to guess whether the review was positive or negative based on the fact that it contains this sentence, it’s most likely they would be negative and positive, respectively.
This can’t be figured out by looking at singled out words: by itself, praised has a positive meaning, but the fact that it’s followed by disappointments reverses that effect.
To learn this and uncountably many other language patterns, a model would need to be exposed to them during the training process.
One thing we can do is apply data augmentation. The paper Distilling Task-Specific Knowledge from BERT into Simple Neural Networks applies augmentation in three ways:
- Randomly replacing a word with a masked token: <mask> on BERT or <unk> for other models;
- Randomly replacing a word with another word with the same Part-of-Speech tag, for example, a noun with another noun;
- Randomly masking a group of n adjacent words or, as linguists like to call it, an
n-gram;
This is only feasible with the help of a teacher model, as very often these kinds of perturbations can change the meaning of the sentence completely, like in the example above, rendering the original label unreliable.
A model like BERT has seen billions of sentences during its pre-training, so it’s much more likely to have seen examples of many different patterns and it can supply labels for the new examples.
Setting up the training process for knowledge distillation
I will use a variety of libraries: Pytorch, Torchtext, huggingface’s transformers, spacy and of course, good old Numpy.
I will train a tiny model on SST-2, Stanford Sentiment Penn Treebank task.
Each sentence in the dataset is a movie review, and the number “2” indicates that there are only 2 possible classes for each review: positive or negative.
The model is a straightforward BiLSTM:
A 1-layer LSTM reads the sentence forwards, another one reads it backward. The final outputs from both LSTMs are concatenated and fed through a classifier with 1 hidden layer.
I will use Facebook AI’s pretrained fasttext word embeddings with dimension 300.
I will apply the data augmentation scheme from the paper to the training set and use
bert-large-uncased, fine-tuned on SST-2, to produce soft labels on the augmented dataset.
I will compare this approach to training the BiLSTM on the original dataset with hard labels.

Generally, knowledge distillation is done by blending two loss functions, choosing a value of \(\alpha\) between 0 and 1:
\[L = (1 - \alpha)L_H + \alpha L_{KL}\]
Where \(L_H\) is the cross-entropy loss from the hard labels and \(L_{KL}\) is the Kullback–Leibler divergence loss from the teacher labels.
In our case, we can’t trust the original hard labels due to the aggressive perturbations to the data. The exact rules for data augmentation are described below, but take this example:
- Original:
Sentence: the worst thing I’ve ever laid my eyes on
Label: negative - Generated:
Sentence: the best thing I’ve ever laid my eyes on
Since we can’t expect the ground-truth labels to be correct after the algorithm is applied, we’ll set \(\alpha := 1\).
Just to remind you, cross-entropy is defined as:
\[H(p, q) = \sum_{x \in C} p(x)log(q_{\theta}(x))\]
Where \(p(x)\) is the target distribution, that is, 1 for the ground-truth class and 0 for all others. \(q_{\theta}(x)\) is the distribution output by the model, parametrized by its parameters \(\theta\), and \(C\) is the set of all classes.
Kullback–Leibler divergence is a metric of the difference between two probability distributions, defined similarly to the cross-entropy as:
\[D_{KL}(p_{\phi}, q_{\theta}) = \sum_{x \in C} p_{\phi}(x)log(\frac{q_{\theta}(x)}{p_{\phi}(x)}) = H(p_{\phi}, q_{\theta}) - H(p_{\phi})\]
In this case, \(p_{\phi}(x)\) and \(q_{\theta}(x)\) are the probability distributions given by the teacher and the student. It’s also called relative entropy, as it’s equal to the cross-entropy of
\(p_{\phi}\) and \(q_{\theta}\) minus \(p_{\phi}\)'s own entropy.
The most common way for neural networks to output probabilities over classes is to apply a softmax function to the output of the last layer. That is:
\[q_{\theta}(x_j) = \frac{exp(z_j / T)}{\sum\limits_{k}^C exp(z_k / T)}\]
Where \(z_j\) is the raw score given by the network to class \(j\) and \(T\) is a hyperparameter called temperature, set to 1 in the majority of networks, as its value is not important most of the time.
However, as explained by the paper Distilling the Knowledge in a Neural Network, as \(T\) becomes larger the Kullback–Leibler divergence becomes more and more similar to applying MSE Loss to the raw scores. MSE Loss tends to be more common for training small networks since, among a variety of reasons, it doesn’t have hyper-parameters. That is, we don’t need to pick a value for \(T\).
These metrics are taken for each token in the sentence. To get the values of the loss functions we average them over the sequence of tokens.
The code
I will leave out the boring parts like logging code for the article, but you can find the full code at github.com/tacchinotacchi/distil-bilstm. With a single click of the below button you can get the same results.

We will go through 5 main steps:
- Loading the data from tsv files
- Data augmentation
- Defining the BiLSTM model
- Defining the training loop
- Launching the training loop
Loading the data from tsv files
There are two formats we need to be able to load. The first one is the format used by the SST-2 dataset:
sentence label
contains no wit , only labored gags 0
With the sentence, a tab separator and the id of the class to which the sentence belongs: 0 for negative, 1 for positive. Loading this format is relatively straightforward in torchtext. First, we create two torchtext.data.Field objects:
text_field = data.Field(sequential=True, tokenize=tokenizer, lower=True, include_lengths=True, batch_first=batch_first)
label_field_class = data.Field(sequential=False, use_vocab=False, dtype=torch.long)Let’s take the parameters apart.
sequentialis to be setTruefor fields that consist of variable length sequences, like text.tokenizeis the function that torchtext should use to tokenize this field of each example. That is,BertTokenizer.tokenizeorspacy_en.tokenizedepending on which model is being used.lowerindicates that the text should be made lowercase.include_lengthsindicates that later, when grouping the examples in batches, we want torchtext to provide a tensor with the length of each sequence in the batch. This is used to provide sequence lengths and attention masks to the BiLSTM and BERT models, respectively.batch_firstindicates which dimension in the returned tensor should correspond to elements in the batch, and which should correspond to steps in the sequence. Values ofTrueandFalsecorrespond to dimensions (batch_size, seq_length) or (seq_length, batch_size), respectively. To be setTruefor BERT andFalsefor BiLSTMClassifier.
The second format of data we need to load is the one used by the augmented dataset:
sentence label
contains no wit , only labored gags 3.017604 -2.543920
Where fields are separated by tab characters, and words or scores are separated by whitespace characters.
Here, there are two values for each label: the score given by BERT to the negative class, and the score for the positive class. Loading this is more complicated, as torchtext does not directly support sequences of floats. However, we can load this format by specifying sequential=False and specifying a function to be executed before the data is turned into a tensor with the argument preprocessing. I specify a lambda function that splits the string into a list of two floats. After that, torchtext passes the list to torch.tensor, which turns it into a tensor of dimension (2,).
label_field_scores = data.Field(sequential=False, batch_first=True, use_vocab=False,
preprocessing=lambda x: [float(n) for n in x.split(" ")], dtype=torch.float32)We can then make a list of field objects next to the name we want them to have, and pass it to the initializer of torchtext.data.TabularDataset to load each set in one call:
fields_train = [("text", text_field), ("label", label_field_train)]
train_dataset = data.TabularDataset(
path=os.path.join(data_dir, "train.tsv"),
format="tsv", skip_header=True,
fields=fields_train
)
fields_valid = [("text", text_field), ("label", label_field_valid)]
valid_dataset = data.TabularDataset(
path=os.path.join(data_dir, "dev.tsv"),
format="tsv", skip_header=True,
fields=fields_valid
)It would be possible to load both with only one call to torchtext.data.TabularDataset.splits, but only when both the training and validation set use the same fields. I avoid using splits since this condition is not met when the augmented dataset is used for training.
We also need to specify a torchtext.data.Vocab for text fields, so that each word can be converted to a corresponding numerical id. In the case of the BiLSTM model, we build one based on fasttext embeddings and the training set:
vectors = pretrained_aliases["fasttext.en.300d"](cache=".cache/")
text_field.build_vocab(train_dataset, vectors=vectors)In the case of BERT, I encountered two problems:
- The transformers library saves BERT’s vocabulary as a Python dictionary in
bert_tokenizer.vocab. However, there’s no way to initializetorchtext.data.Vocabwith a Python dictionary; - A few tokens need to be swapped out in order to make BERT work with torchtext. For example, [UNK] needs to be saved as <unk>. I implemented the class
BertVocabto handle all of this. It implements the same interface astorchtext.data.Vocab, so we can just assign it totext_field.vocaband torchtext will know how to use it.
text_field.vocab = BertVocab(tokenizer.vocab)To handle the different cases, I wrote function load_data in utils.py that knows which files to load and how based on the arguments passed to it. It’s called like this:
# For BiLSTMClassifier
datasets = load_data(data_dir, utils.spacy_tokenizer, augmented=args.augmented)
# For BERT
datasets = load_data(data_dir, bert_tokenizer, bert_vocab=bert_tokenizer.vocab, batch_first=True)
train_dataset, valid_dataset, text_field = datasetsTo generate tensors of batches, we create a torchtext.data.BucketIterator.
train_it = data.BucketIterator(train_dataset, self.batch_size, train=True, shuffle=True, device=self.device)
val_it = data.BucketIterator(val_dataset, self.batch_size, train=False, sort_key=lambda x: len(x.text), device=self.device)This is the class that handles creating the batches, shuffling the dataset, padding, etc.
We can iterate over this object to generate batches:
example_original_it = data.BucketIterator(original_dataset, 2)
example_augmented_it = data.BucketIterator(augmented_dataset, 2)
for original_batch, augmented_batch in zip(example_original_it, example_augmented_it:
print(original_batch)
print(augmented_batch)
breakOutput:
[torchtext.data.batch.Batch of size 2]
[.text]:('[torch.LongTensor of size 21x2]', '[torch.LongTensor of size 2]')
[.label]:[torch.LongTensor of size 2]
[torchtext.data.batch.Batch of size 2]
[.text]:('[torch.LongTensor of size 17x2]', '[torch.LongTensor of size 2]')
[.label]:[torch.FloatTensor of size 2x2]text, label for the original dataset:
(tensor([[ 46, 5],
[ 344, 239],
...
[ 17, 1],
[ 10, 1]]), tensor([21, 15])) tensor([0, 1])text is a tuple with the word ids and sentence lengths, label contains the class for each sentence.
label for the augmented dataset:
tensor([[ 1.5854, -0.8519], [-1.6052, 1.4790]])Here, label contains the scores for each class.
Data augmentation
In this section, I’ll draw an outline of the procedure I used for data augmentation. As mentioned before, this is taken directly from the paper.
# Load original tsv file
input_tsv = load_tsv(args.input)
sentences = [spacy_en(text) for text, _ in tqdm(input_tsv, desc="Loading dataset")]
First, the input file, train.tsv in the main folder of the SST-2 dataset, is loaded into a simple list of lists. Then the sentences are run through spacy’s “en” pipeline, which returns the processed text.
# Build lists of words’ indexes by POS tag
pos_dict = build_pos_dict(sentences)The second step is to build a dictionary of Part-of-Speech tags. The dictionary will contain, for each tag that was encountered, a list of words that have been assigned that tag in the corpus.
For example:
# First 10 words classified as verbs
print(pos_dict["VERB"][:10])
['hide',
'contains',
'labored',
'loves',
'communicates',
'remains',
'remain',
'clichés',
'could',
'dredge']Next comes the generation step:
# Generate augmented samples
sentences = augmentation(sentences, pos_dict)augmentation is a simple function that runs make_sample in a loop and checks for duplicates. The latter function is more interesting:
def make_sample(input_sentence, pos_dict, p_mask=0.1, p_pos=0.1, p_ng=0.25, max_ng=5):
sentence = []
for word in input_sentence:
# Apply single token masking or POS-guided replacement
u = np.random.uniform()
if u < p_mask:
sentence.append(mask_token)
elif u < (p_mask + p_pos):
same_pos = pos_dict[word.pos]
# Pick from list of words with same POS tag
sentence.append(np.random.choice(same_pos))
else:
sentence.append(word.text.lower())
# Apply n-gram sampling
if len(sentence) > 2 and np.random.uniform() < p_ng:
n = min(np.random.choice(range(1, 5+1)), len(sentence) - 1)
start = np.random.choice(len(sentence) - n)
for idx in range(start, start + n):
sentence[idx] = mask_token
return sentenceAs you can see, either single token masking or POS-guided replacement is applied, with probabilities p_mask and p_pos. Then, with probability p_ng, a value n is sampled from the distribution [1, 2, 3, 4, 5], and a group of n adjacent words is sampled for masking.

Here’s an example of a sentence from the original dataset and a corresponding sample:
- Original: contains no wit , only labored gags
- Generated: contains no wit , only <mask> appetite
# Load teacher model
model = BertForSequenceClassification.from_pretrained(args.model).to(device)
tokenizer = BertTokenizer.from_pretrained(args.model, do_lower_case=True)
# Assign labels with teacher
teacher_field = data.Field(sequential=True, tokenize=tokenizer.tokenize, lower=True, include_lengths=True, batch_first=True)
fields = [("text", teacher_field)]
examples = [
data.Example.fromlist([" ".join(words)], fields) for words in sentences
]
augmented_dataset = data.Dataset(examples, fields)Now that the new sentences have been generated, it’s time to assign them labels.
As far as I know, there’s no one-liner for loading a dataset from a list of sentences in torchtext. Instances of torch.data.Example have to be constructed first, each corresponding to a sentence.
Each torchtext.data.Example is initialized with a sentence and teacher_field, which contains the necessary information about what type of data the example contains.The list of examples can then be used to initialize a torchtext.data.Dataset.
Next, we need some code for calling the model. I use this class for training, evaluation and inference:
def __init__(self, model, device,
loss="cross_entropy",
train_dataset=None,
temperature=1.0,
val_dataset=None, val_interval=1,
checkpt_callback=None, checkpt_interval=1,
max_grad_norm=1.0, batch_size=64, gradient_accumulation_steps=1,
lr=5e-5, weight_decay=0.0):For now we only need to do inference, so we can ignore all the keyword arguments.
For reasons that will be explained later, I defined two sub-classes of Trainer: LSTMTrainer and BertTrainer.
To generate the new labels with BERT, BertTrainer’s infer method is called:
new_labels = BertTrainer(model, device).infer(augmented_dataset)This returns the raw class scores output by BERT in a numpy array. The only thing left to do is to write them into an output .tsv file:
# Write to file
with open(args.output, "w") as f:
f.write("sentence\tscores\n")
for sentence, rating in zip(sentences, new_labels):
text = " ".join(sentence)
f.write("%s\t%.6f %.6f\n" % (text, *rating))The output file will look like this:
sentence scores
hide new secretions from the parental units 0.514509 0.009824
hide new secretions from either <mask> units 1.619976 -0.642274
provide <mask> secretions from the heartache units 1.875626 -0.908450
<mask> <mask> secretions <mask> <mask> <mask> units 0.879091 -0.349838
hide new <mask> from half parental units 1.410404 -0.473437
hide <mask> secretions from some <mask> units 2.397400 -1.622049
hide new secretions from half parental units 1.644318 -0.587317
hide new <mask> featherweight the parental units 0.108670 0.199454
...Defining the BiLSTM model
The code for the BiLSTM network is encapsulated within the class BiLSTMClassifier:
class BiLSTMClassifier(nn.Module):
def __init__(self, num_classes, vocab_size, embed_size, lstm_hidden_size, classif_hidden_size, lstm_layers=1, dropout_rate=0.0, use_multichannel_embedding=False):
super().__init__()
self.vocab_size = vocab_size
self.lstm_hidden_size = lstm_hidden_size
self.use_multichannel_embedding = use_multichannel_embedding
if self.use_multichannel_embedding:
self.embedding = MultiChannelEmbedding(self.vocab_size, embed_size, dropout_rate=dropout_rate)
self.embed_size = len(self.embedding.filters) * self.embedding.filters_size
else:
self.embedding = nn.Embedding(self.vocab_size, embed_size)
self.embed_size = embed_size
self.lstm = nn.LSTM(self.embed_size, self.lstm_hidden_size, lstm_layers, bidirectional=True, dropout=dropout_rate)
self.classifier = nn.Sequential(
nn.Linear(lstm_hidden_size*2, classif_hidden_size),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout_rate),
nn.Linear(classif_hidden_size, num_classes)
)The network is composed of three main parts:
- Word embeddings. To mimic the paper more accurately I implemented an option to use multichannel embeddings, implemented in the class
MultiChannelEmbedding. However, in my tests, I haven’t found them to measurably improve the performance, so I default to the “plain”torch.nn.Embeddinglayer. - One or more LSTM layers.
- A simple, non-linear classifier with one hidden layer
For this article, I define the network to have 1 LSTM layer with hidden size 300 and the classifier’s hidden layer to have size 400. I set the dropout rate to 0.15.
When using the LSTM layer from torch.nn with variable length sequences, some adjustments have to be applied to the input first. Let me walk you through the forward function:
# Sort batch
seq_size, batch_size = seq.size(0), seq.size(1)
length_perm = (-length).argsort()
length_perm_inv = length_perm.argsort()
seq = torch.gather(seq, 1, length_perm[None, :].expand(seq_size, batch_size))
length = torch.gather(length, 0, length_perm)First, the sequences in the batch have to be sorted by length. I know it looks complicated, so let’s break it down:
length_perm = (-length).argsort()
length_perm_inv = length_perm.argsort()
The first line returns a permutation of length, as a list of indexes to the tensor, that sorts the sequences in increasing order. The second line creates a permutation that reverses the first one.
seq = torch.gather(seq, 1, length_perm[None, :].expand(seq_size, batch_size))
length = torch.gather(length, 0, length_perm)Applies the permutation to the two input tensors.The expression length_perm[None, :].expand(seq_size, batch_size) is meant to make sure that the size of tensor length_perm matches that of seq at dimension 0. Refer to torch.gather for the details, but the important thing is that now seq and length are sorted by the length of each sequence.
# Pack sequence
seq = self.embedding(seq)
seq = pack_padded_sequence(seq, length)Here, pack_padded_sequence is imported from torch.nn.utils.rnn, and it returns an instance of PackedSequence, that is, an array where the sequences are packed in a way that makes it possible for the LSTM to run more efficiently, without the padding tokens.

# Send through LSTM
features, hidden_states = self.lstm(seq)
# Unpack sequence
features = pad_packed_sequence(features)[0]Next, the LSTM processes the sentences, and the resulting features are turned back into a padded sequence with torch.nn.utils.rnn.pad_packed_sequence.
Since we’re using a bidirectional LSTM, it returns an output of shape \((N_{seq}, N_{batch}, 2*hidden\_size)\), where the last dimension contains the features from the forward-reading LSTM layer concatenated with those from the backward-reading LSTM layer.
Next steps are to:
- Separate two outputs by reshaping the tensor to \((N_{seq}, N_{batch}, 2, hidden\_size)\)
- Gather the features corresponding to the last word in each sequence and take only the forward features
- Take the backward features for the first word of each sequence
- Concatenate
# Index to get forward and backward features and concatenate
# Gather the last word for each sequence
last_indexes = (length - 1)[None, :, None, None].expand((1, batch_size, 2, features.size(-1)))
forward_features = torch.gather(features, 0, last_indexes)
# Squeeze seq dimension, take forward features
forward_features = forward_features[0, :, 0]
# Take the first word, backward features
backward_features = features[0, :, 1]
features = torch.cat((forward_features, backward_features), -1)Finally, the features are sent through the classifier to get the raw probability scores:
# Send through the classifier
logits = self.classifier(features)The last thing to do before returning the result is to apply length_perm_inv. If you remember, the sequences in the batch are not in the same order as they were when BiLSTMClassifier was called. The original order needs to be restored for the scores to make sense outside of this function:
# Invert batch permutation
logits = torch.gather(logits, 0, length_perm_inv[:, None].expand((batch_size, logits.size(-1))))
return logits, hidden_statesDefining the training loop
I will now give an overview of the training loop. I will try to focus on the fun parts and leave out the unnecessary ones, like logging to Tensorboard and conditioning on options.
The training loop is managed by the class Trainer, which is initialized like so:
trainer = LSTMTrainer(model, "mse" if args.augmented else "cross_entropy", device, train_dataset=train_dataset, val_dataset=valid_dataset, val_interval=250, checkpt_callback=lambda m, step: save_bilstm(m, os.path.join(args.output_dir, "checkpt_%d" % step)), checkpt_interval=250, batch_size=args.batch_size, lr=args.lr)The parameters are, in order:
- The model to be trained;
- The loss function to be used (more on that later);
- The device on which to execute the computations;
train_dataset, the training dataset, as an instance oftorchtext.data.Dataset;val_dataset, the validation dataset;val_interval, how many gradient steps to execute between evaluations on the validation dataset;checkpt_callback, the function to call in order to save a checkpoint of the modelcheckpt_interval, how many steps to execute between checkpoints
The method for training the model is Trainer.train:
def train(self, epochs=1, schedule=None, **kwargs):Where schedule is the learning rate schedule, that can be set to None for fixed learning rate, "warmup" for a linear warmup schedule and “cyclic” for cyclic learning rate. kwargs captures settings specific to each schedule.
All the models for this article are trained with a warmup schedule, with the warmup lasting between 50 and 200 gradient steps depending on which value gives the best performance.
warmup_steps = kwargs["warmup_steps"]
self.scheduler = torch.optim.lr_scheduler.CyclicLR(self.optimizer, base_lr=self.lr/100, max_lr=self.lr, step_size_up=max(1, warmup_steps), step_size_down=(total_steps - warmup_steps), cycle_momentum=False)When the warmup schedule is selected we create a torch.optim.lr_scheduler.CyclicLR and set it to increase the learning rate linearly for warmup_steps, then decrease it over the rest of the training.
for epoch in trange(epochs, desc="Training"):
for batch in tqdm(self.train_it, desc="Epoch %d" % epoch, total=len(self.train_it)):
self.train_step(batch)For every epoch, we iterate over self.train_it. self.train_it is created in Trainer.__init__ with
data.BucketIterator(self.train_dataset, self.batch_size, train=True, sort_key=lambda x: len(x), device=self.device)train_step contains all the usual stuff:
def train_step(self, batch):
self.model.train()
batch, label, curr_batch_size = self.process_batch(batch)First, Trainer.process_batch is called. This is the only function that works differently in LSTMTrainer and BertTrainer: For BERT, we need to compute the attention masks based on the length of each sequence in the batch. process_batch returns a tuple of three values:
- A dictionary with the keyword arguments required to call the model in question. For example, in
BertTrainer, its content is{“input_ids”: ..., “attention_mask”: ...} - The labels
- The size of this batch, which is calculated differently based on the model. This is because BERT, unlike the BiLSTM model, uses
batch_first=True.
s_logits = self.model(**batch)[0] # **kwargs syntax expands a dictionary into keyword arguments
loss = self.get_loss(s_logits, label, curr_batch_size)
# Compute the gradients
loss.backward()
# Apply gradient clipping
nn.utils.clip_grad_norm_(self.model.parameters(), self.max_grad_norm)
self.optimizer.step()
if self.scheduler is not None:
# Advance learning rate schedule
self.scheduler.step()
# Clear the gradients for the next step
self.model.zero_grad()
# Save stats to tensorboard
# ...
# Every val_interval steps, evaluate and log stats to tensorboard
if self.val_dataset is not None and (self.global_step + 1) % self.val_interval == 0:
results = self.evaluate()
# Log to tensorboard...
# Save checkpoint every checkpt_interval steps...loss is calculated in Trainer.get_loss based on the loss function selected when creating the Trainer. The options are mse, cross_entropy and kl_div.
def get_loss(self, model_output, label, curr_batch_size):
if self.loss_option in ["cross_entropy", "mse"]:
loss = self.loss_function(
model_output,
label
) / curr_batch_size # Mean over batch
elif self.loss_option == "kl_div":
# KL Divergence loss needs special care
# It expects log probabilities for the model's output, and probabilities for the label
loss = self.loss_function(
F.log_softmax(model_output / self.temperature, dim=-1),
F.softmax(label / self.temperature, dim=-1)
) / (self.temperature * self.temperature) / curr_batch_size
return lossWhen using cross_entropy or mse, the loss function is called in the same way, then averaged over the examples in the batch. On the other hand, when using kl_div, torch.nn.KLDivLoss expects log probabilities as the first argument and probabilities as the second. We also scale the scores by temperature, then divide the loss by (self.temperature * self.temperature) in order to maintain approximately the same scale of loss values as the cross-entropy[1].
In order to evaluate the model on the validation dataset, Trainer.evaluate is called.
def evaluate(self):
self.model.eval()
val_loss = val_accuracy = 0.0
loss_func = nn.CrossEntropyLoss(reduction="sum")
for batch in tqdm(self.val_it, desc="Evaluation", total=len(self.val_it)):
with torch.no_grad():
batch, label, _ = self.process_batch(batch)
output = self.model(**batch)[0]
loss = loss_func(output, label)
val_loss += loss.item()
val_accuracy += (output.argmax(dim=-1) == label).sum().item()
val_loss /= len(self.val_dataset)
val_accuracy /= len(self.val_dataset)
return {
"loss": val_loss,
"perplexity": np.exp(val_loss),
"accuracy": val_accuracy
}Launching the training loop
Putting all the pieces together, we can start the training.
train_bilstm.py:
train_dataset, valid_dataset, text_field = load_data(args.data_dir, spacy_tokenizer, augmented=args.augmented)
vocab = text_field.vocab
model = BiLSTMClassifier(2, len(vocab.itos), vocab.vectors.shape[-1],
lstm_hidden_size=300, classif_hidden_size=400, dropout_rate=0.15).to(device)
# Initialize word embeddings to fasttext
model.init_embedding(vocab.vectors.to(device))
trainer = LSTMTrainer(model, device,
loss="mse" if args.augmented or args.use_teacher else "cross_entropy",
train_dataset=train_dataset,
val_dataset=valid_dataset, val_interval=250,
checkpt_interval=args.checkpoint_interval, checkpt_callback=lambda m, step: save_bilstm(m, os.path.join(args.output_dir, "checkpt_%d" % step)),
batch_size=args.batch_size, gradient_accumulation_steps=args.gradient_accumulation_steps,
lr=args.lr)
if args.do_train:
trainer.train(args.epochs, schedule=args.lr_schedule,
warmup_steps=args.warmup_steps, epochs_per_cycle=args.epochs_per_cycle)
print("Evaluating model:")
print(trainer.evaluate())train_bert.py:
# Load model from transformers library
bert_config = BertConfig.from_pretrained("bert-large-uncased", cache_dir=args.cache_dir)
bert_model = BertForSequenceClassification.from_pretrained("bert-large-uncased", config=bert_config, cache_dir=args.cache_dir).to(device)
bert_tokenizer = BertTokenizer.from_pretrained("bert-large-uncased", do_lower_case=True, cache_dir=args.cache_dir)
train_dataset, valid_dataset, _ = load_data(args.data_dir, bert_tokenizer.tokenize,
vocab=BertVocab(bert_tokenizer.vocab), batch_first=True)
train_dataset, valid_dataset, vocab = load_data(args.data_dir, bert_tokenizer.tokenize, bert_vocab=bert_tokenizer.vocab, batch_first=True)
trainer = BertTrainer(bert_model, device,
loss="cross_entropy",
train_dataset=train_dataset,
val_dataset=valid_dataset, val_interval=250,
checkpt_callback=lambda m, step: save_bert(m, bert_tokenizer, bert_config, os.path.join(args.output_dir, "checkpt_%d" % step)),
checkpt_interval=args.checkpoint_interval,
batch_size=args.batch_size, gradient_accumulation_steps=args.gradient_accumulation_steps,
lr=args.lr)
print("Evaluating model:")
print(trainer.evaluate())The results

As you can see from the table, the BiLSTM model trained on the augmented dataset attains a relatively competitive performance with bert-large-uncased, while taking about 65 times less computation to run inference on a single sentence, and being about 57 times lighter when it comes to the number of trainable parameters.
As an ablation study, I also tried to train the BiLSTM model on the BERT’s labels without applying data augmentation. I found that the improvement given only by training on the teacher's scores is not substantial, compared to when we include the data augmentation procedure.
My hypothesis is that, for a tiny and structurally different student model like BiLSTMClassifier, knowledge distillation does not bring the same advantages as it does for huggingface’s DistilBERT. While it does seem to offer a slightly better training objective, most of the improvement in the student’s performance can be attributed to how the teacher made it possible to assign reasonably accurate labels to a very perturbed dataset, and the sheer size of the datasets that can be generated this way. For example, in the paper this article is inspired by, as well as my tests, we produced 20 augmented examples for every example in SST-2.
Lessons learned
Trying to reproduce the results from Distilling the Knowledge in a Neural Network taught me many valuable lessons about conducting research on NLP. Here are the most important ones that would have saved me many hours if only I knew them when I started:
Use well-established libraries
Always try to use well-established techniques, libraries, and resources over writing your own code and trying to come up with your custom solutions, unless you need to do something really unusual.
On my first try, I used an outdated tokenizer library and downloaded word2vec embeddings pre-trained on Google News from some Drive folder, in an effort to use the same exact embeddings as the paper.
However, when using uncommon or outdated libraries and resources, it’s difficult to reproduce someone else’s results. In fact, your results will vary wildly based on unpredictable factors, like the exact version of a library. This can hinder you from reproducing their results, especially in the case when the code for the paper wasn’t published and you base your code only on the details that were explicitly mentioned.
In practice, it turned out to be a better decision to use fasttext embeddings, which are not the same as in the paper, just because they’re well integrated with Torchtext. The simple fact that Torchtext includes a link to pretrained fasttext embeddings makes it more likely they were tested by the maintainers of the library.
Well-maintained resources give much more reliable results, and the fewer lines of code you have to write, the less you risk writing bugs.
Since I have a bad habit of writing my own algorithms for everything, I’m also glad I looked into using the spacy NLP library for Part-of-Speech guided word replacement instead of writing custom code, as it only took a few lines. If I had tried to write it on my own, my guess is that it would’ve taken days and I would’ve come up with a very suboptimal solution.
Double-check the paper, then check it again
On my first try, I have to admit I read the paper in question very sloppily. I spent many days testing and debugging my code, trying to figure out why I wasn’t getting any performance gains with the distillation training objective. It turned out I had skimmed over the authors’ data augmentation scheme. After I contacted the authors of the paper, they kindly mentioned that as a possible problem in my implementation. I spent only one afternoon in a caffeine-and-heavy-metal-induced coding trance replicating the scheme and it made all the difference.
Don’t spend too much time tuning hyper-parameters
Unless that’s the object of your study.
If you’re using a network architecture someone else invented, which most of the time you should, chances are you’ll be able to change the hyper-parameters quite a bit while only getting slight variations in performance. Most often, your time is better spent engineering the data and trying to come up with the best way to formulate the problem that fits your needs.
This is not to say you shouldn’t tune them, but try to leave it for the end when everything else is decided. Your problem has high enough dimensionality as it is.
About Alex Amadori
Alex is a student at 42, Paris. He’s interested in exploring new Deep Learning techniques; in particular, he is fascinated by the problems of reasoning and Meta-Learning, and always striving to gain a better understanding of the challenges involved so he may contribute to the research. You can connect with Alex on LinkedIn, Twitter and Github.
References
Main source: