Inverting Facial Recognition Models
Can we teach a neural net to convert face embedding vectors back to images?

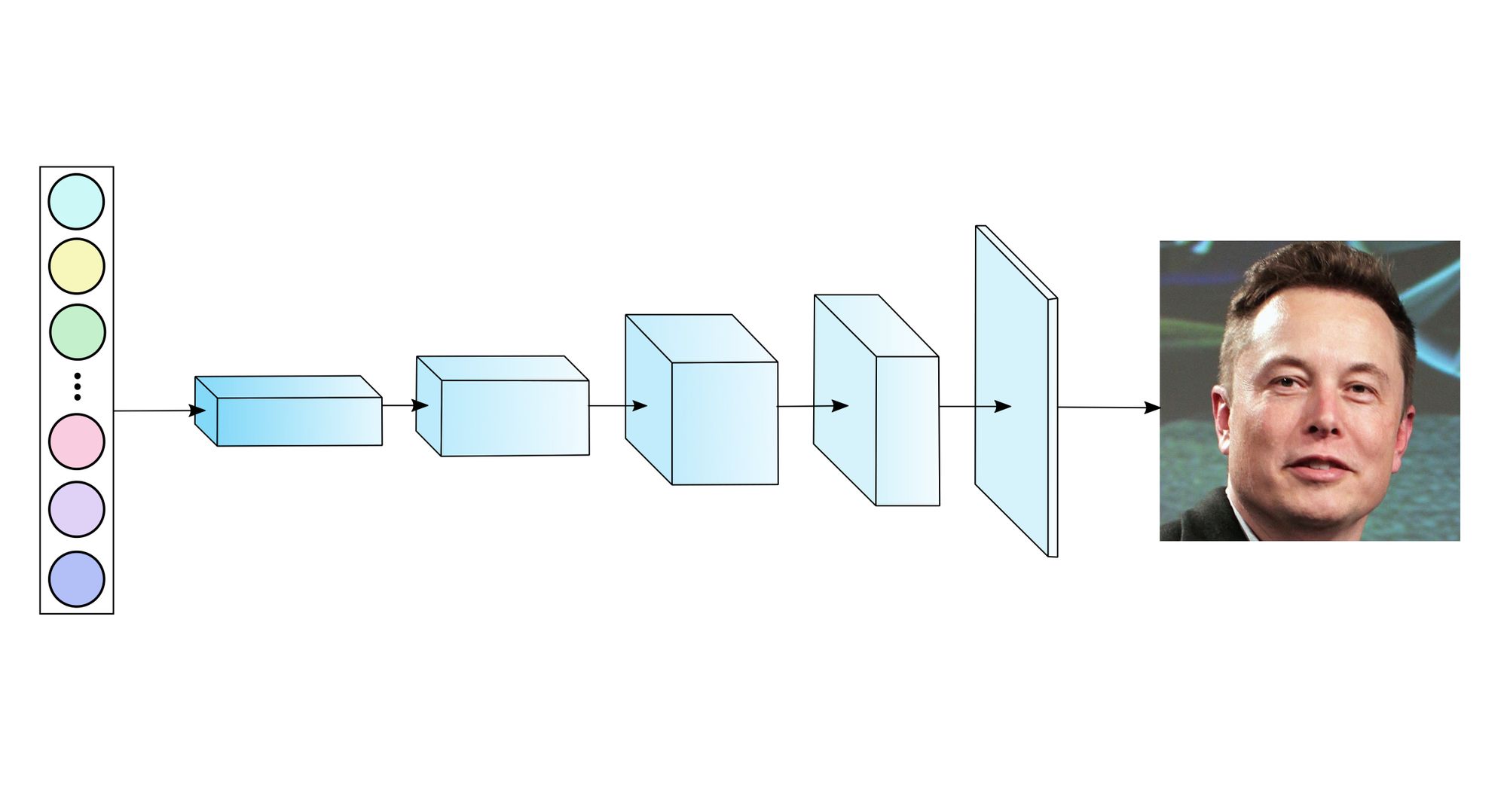
Let’s begin with a question. Suppose I were to give you the following 128 dimensional vector in full, along with the information that this is the output from a face embedding model typically used in face recognition. Could you tell me whose face this represents?
[-0.123, -0.020, 0.123, -0.042, -0.122, -0.036, -0.064...., 0.098]
If you’re anything like me, you’re probably wondering something on the lines on “this is a very esoteric question”, and it is. Yet, instead of asking if a human can read this, and looking at it from from the perspective of a machine learning problem it’s not terribly unreasonable: we have one representation of the data (this vector), and we’d like to transform it to a different representation (an image), with the help of some function whose parameters we can learn.
Moreover, this isn’t an entirely pointless question; unlike most deep learning applications where most of the output can be safely thrown away (you don’t care about the output probabilities over all 1000 ImageNet classes of your cat photo, just that the most likely class is the cat class), face recognition applications require that you store these output embeddings long term; they after all, form the database you compare new face images against.
So the question we’re attempting to answer is this:
Can we teach a neural net to convert face embedding vectors back to images?
Embeddings, encodings and deep learning

Suppose you have some data with 10 features, and you’d like to have it classified into one of 3 classes. The simplest deep model you can build is a three layer, fully connected network, with 10 input neurons, let’s say 6 hidden neurons, and 3 output neurons. The network takes in a 10 dimensional data vector, where each component represents a fairly low level feature, and projects it down to 3 dimensions, where each component represents a much higher level feature.
Despite the incredible diversity in the types of applications deep neural nets can be trained to perform, in many supervised learning applications they’re all built on this same core idea: take in an input of very high dimension (an image with thousands of pixels, a raw audio file consisting of thousands of sample points, etc.), and through many, many non-linear transformations, convert them into a low dimensional, high level representation of the input data.
The representation of the data produced by the output layer isn’t the final result though; it’s often just an intermediary. In classification, the output gets passed through a softmax to produce class probabilities. Similarly, in face recognition, the output of a single image doesn’t mean much, but comparing the output (the face embedding) of one image to another (often either L2 distance or cosine similarity) helps us figure how ‘distant’ the faces are to each other, and therefore whether they’re of the same person or not.
There’s many ways to train such networks, often employing specialized loss functions, such as the triplet loss (in brief, this loss penalizes the network if the embeddings of two images of the same person are too distant, or if the embedding of two images of different people are too close). However, that’s not the focus of this article.
Face embeddings are different from, say the final output of a classification network, because while the classifier output can abstract away all details of the original image, and only contain the information ‘this is most likely a cat’, face embeddings have to project down into a small number of dimensions while keeping all detail that makes a face distinct. Which means while the face embedding network still has the liberty to throw away the background, it also needs to keep information such as nose shape, jawline structure, and so on.
The Problem
So, what we now have is a fairly straightforward supervised learning problem: given a set of face embedding vectors and their associated images, find a function that maps the embeddings to the images.
It's always a good idea to read any research papers that are related to the question you're asking. In this case, Cole et al.'s paper, Synthesizing Normalized Faces from Facial Identity Features, is a good starting point. The paper explores the usage of face embedding networks as a way to generate "clean" images of a person (i.e. removing glasses and accessories, fixing tilt and making sure the person is facing the "camera" , etc.)
Their proposed method doesn't use the actual, final layer outputs, which are the embeddings, but earlier layers in the network, which contain more information to work with. This will result in nicer images, but it also means we aren't actually decoding the final embeddings, which are the vectors typically stored in a database.
To train a deep neural net to solve this image generation task, we first need to find an architecture that fits the problem. The paper above does describe the architecture used, a convolutional network made of transposed convolutions; a common building block in most image generation networks.
We can then take ideas from the 2015 DCGAN paper, since the paper's Generator network closely fits the requirements: It takes in a flattened 100 dimensional vector, and outputs a 64x64x3 color image.
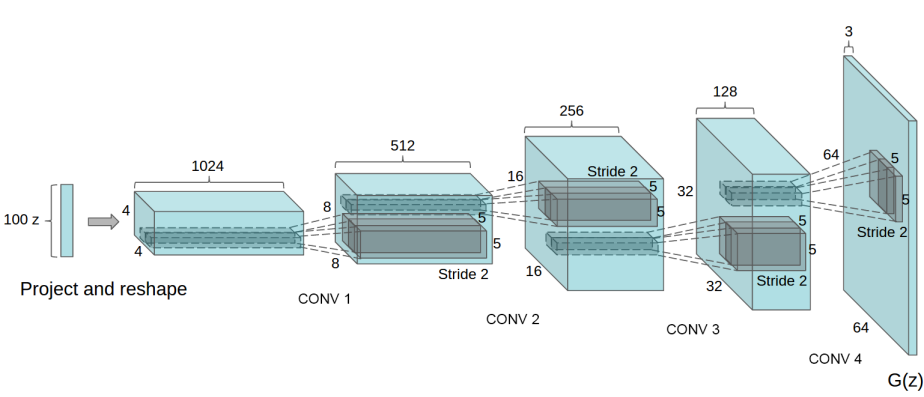
In addition, we have the benefit of having access to our targets (since we know what image we passed in to produce the embedding), which means we're solving a supervised learning problem, which is a lot more stable than the adversarial learning problem training a GAN involves, we can simply reuse the architecture without having to implement the GAN-specific optimizations (like initializing the weights in a specific way). The core idea is simple: it uses a series of repeating blocks with the following structure:
- A transposed convolution
- followed by a Batch Normalization layer
- followed by a ReLU non-linearity
The activations of the final layer of size 64x64x3 are the passed through the sigmoid function to convert them to a range of [0, 1], the same as the floating point representation of an RGB image.
Written in PyTorch, the model looks as such:
Now, all we need to do is feed the flattened vectors into the network (the input size of the first layer is controlled by n_hidden), and we'll get back 64x64x3 shaped images, i.e. a color image of size 64x64.
We want to ultimately minimize the difference between the pixels of the predicted image and the true image. We can't use a loss like cross-entropy here because it expects the target to be either 0 or 1 (as in binary classification), while in our case it can be any number between 0 and 1 (eg. 0.52). So instead, we treat this as a regression problem, using the L2 (aka the mean squared error) loss to encourage the network to predict pixel values close to the true target value.
At first the images will be terrible, but then it's just a matter of computing the distance loss between the predicted image and the true image, and optimizing the network to minimize the difference.
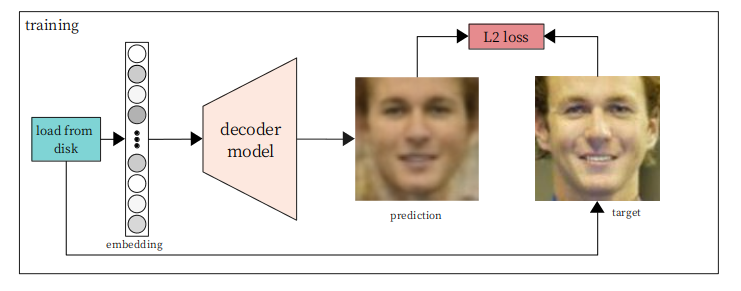
Once trained, the network will be able to take the output embedding of a face embedding network, and convert it back, accurately, to a photo of a person represented by the embedding.
Of course, this is all nice in theory, but does it work?
The Data
For the purposes of this tutorial, we use the popular Labelled Faces in the Wild (LFW) dataset. At 5749 unique identities (and each identity may have one or more images) images, this dataset really isn’t meant for training; it's the dataset all face recognition models trained on other, much larger datasets are tested on. (As we’ll find out later, we don’t really need much data for this task, so this turns out to be fine).
Let’s start with a baseline approach: take all 5749 identities in LFW, pass them through a face embedding network, then use that as data to train the generator network. For the purposes of this tutorial, we'll use dlib (a C++ machine learning toolkit with a Python API), which has an easily accessible face embedding network we'll use to generate the embeddings.
Most face recognition pipelines will also frontalize a person’s face before feeding them into the network (removing any tilt/pan, so that the person appears to be looking straight into the camera), so instead of using the image directly, we’ll use the frontalized image as the target for the the generator.
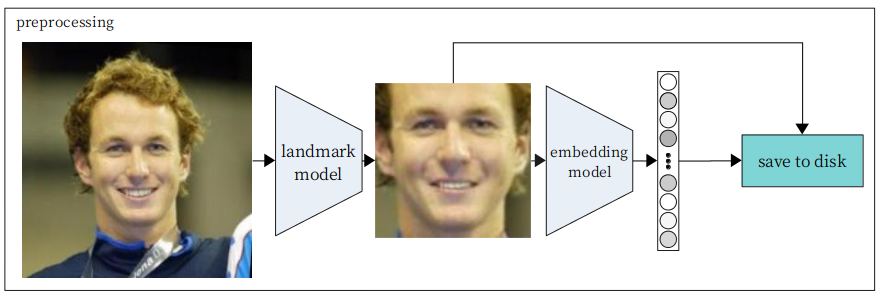
So we first preprocess the images into frontalized images, running them through a basic face detector first, then running a landmark detection model on them. If we can obtain the location of the face landmarks (eg. tip of the nose, points on the jaw), we can warp the image to an “average” pose, frontalizing it. We then further pass them into an embedding network. We save both the frontalized face photo, and its associated embedding to disk. This data generation step needs to be run only once.
We first split the 5749 identities into train, validation and test sets, of size 5521, 114 and 114 respectively. Each identity means all images of a single individual. We split by identity instead of by image, to ensure that the same person does not end up in both the train and validation/test sets.
We then perform the preprocessing step on these images, and in the process involves first running dlib's face detector to pick up the faces prior to passing them to the landmark detection and embedding models. It does fail to pick up faces in a few images, and we are left us with a dataset of 5490 identities in the training set, and 113 identities in the validation set, and 108 identities in the test set. (We could improve the retention rate using a more robust face detector, but the number of dropped images is small enough that we can continue). Each image now also has a companion .npy file, containing a 128 dimensional vector, which is its dlib generated embedding.
Since each identity can have one, or more than one image of the same person, the training set has 5490 identities, and 12697 total images. While it is fine for the training set to have more than one image of the same person, this isn't true for the validation and test sets; having more than one image of the same person can potentially skew the metrics we compute using these sets. So, we only keep one image for each identity (and randomly remove the rest, if there are more than one), from the validation and test sets, which mean they have 113 images and 108 images total respectively.
We also download a small sample of 8 images (from Wikimedia Commons), and process them to get their embeddings, to form a small visualization set.
How do you evaluate the model?
So, we've got our data ready, and a fair high level understanding of how we're going to train this model. But, once we do, how are we going to determine how "good" this model is? Sure, finding the version of the model with the lowest validation loss value is one basic approach, but it's always important to remember that losses serve as a proxy for what we actually care about: evaluation metrics.
What do I mean here? For instance, when you're training a classification network, while you can identify that the lowest loss value achieved was 0.18, it's neither very interpretable (what does a value of 0.18 even mean? Is this good? How good?), nor something you ultimately care about (which would be a metric such as top-5 accuracy).
Now, the most ideal metric here would be to have a human evaluate how close the synthesized faces look like their real targets, but that's clearly not an option. But if we are looking for a way to measure how close two faces are to each other, that's also a task a face embedding network was basically designed for.
So, since we have the embedding of the real image as our input, let's use it to synthesize an image, get an embedding of the synthesized image, and compare that with the original! The lower the distance between the embeddings, the more the face recognition system recognizes the two embeddings as belonging to the same person.
This is indeed an idea Cole et. al. explores in their paper, as seen in Figure 12, and it's easy enough to convert it into a metric: just take the average of all the distances of the real embeddings, and embeddings of the synthesized images in the validation set. Implemented using the dlib face recognition network, the metric looks like this:
This is also an interpretable metric as well: most face recognition pipelines work by using a distance threshold; if the distance between the two embeddings are below the threshold, they're identified as belonging to the same person. If needed, we can compute what percentage of the synthesized images produce embeddings when compared with their real embeddings, have a distance below this threshold?, i.e. what percentage of the synthesized images would pass as being of the same person the embedding was taken from?
Attempt One
As described above, we train the model like a standard supervised learning problem, for 150 epochs. Every 5 epochs, we also compute the "average distance" metric described above using the validation set (ideally, we’d do it after every epoch, but this is a fairly expensive operation), and save a copy of the model’s parameters. At the end of training, we keep the copy of the model with the lowest mean distance as the final model.
The training script is as follows:
We monitor the training loss, as well as out validation metric over the 150 epochs. Our training loss continues to go down smoothly as expected, while the average distance reaches a minimum of 0.494 at epoch 30, and mostly remains stagnant in the 0.50 to 0.52 range for the rest of training.
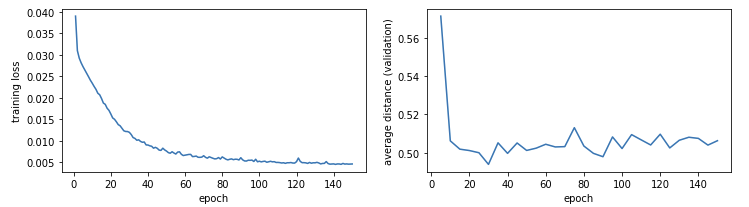
We load in the model's parameters from epoch 30, and use that to compute the distance metric for each image in the test set. Instead of reducing it down to the mean, we can now choose to visualize the full distribution of distances obtained.
But before we can compute what percentage of distances fall below a threshold, we need to decide what the threshold even is. This, in practice depends on your face recognition system; even systems using the same embedding network can use different thresholds (a casual photo album app may use 0.7, while a door lock may use a much lower threshold such as 0.4). What matters more for the experimentation here is that you remain consistent with the threshold across different runs and changes.
For this tutorial, I visualize both the distribution of the distances between the pairs of real and synthesized embeddings (blue), vs randomly pairing the synthesized embeddings with the real embeddings, making sure no synthesized embedding is paired up with its true real counterpart (orange). The main reason for doing this is really a sanity check, if the blue distribution overlaps heavily with the orange one, it basically means our synthesized images are as good as random. It does not appear to, which means our model is actually using the embedding information to generate an appropriate face properly.
I see where the distributions intersect, and round it to the nearest 1/10th of a value, which is 0.6, to get my threshold for the experiments. This is a somewhat arbitrary, yet fairly reasonable approach; even if the blue distribution were the distribution between pairs of two real photo embeddings of the same person, there'd be some overlap with the orange distribution (that, or you'd have a perfect face recognition system), with orange samples to the left of the threshold being false positive (FP) matches, while blue samples to the right being false negatives (FN), so it makes sense to choose a threshold near where the distributions overlap to minimize both FPs and FNs.
(There's a lot more nuance involved in selecting thresholds in production systems, based on several other metrics such as precision, recall, etc. For this experiment, we just need to pick one consistent threshold so that results across different attempts remain comparable.)
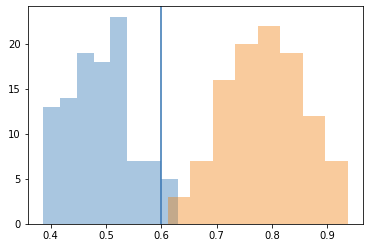
So here, at a threshold of 0.6, 95% percent of the synthesized images would be classified as that of the person the original embedding was taken from. The average of the distances on the test set is 0.489. How do the results look visually, though?

I'm going to go with: yikes. While the synthesized images do resemble the person they're of, the colors are way off. And, let's just take a look at the dataset to see why that may be the case:

Even though the faces have been frontalized, there's still a lot of problems here. The lighting varies heavily from image to image, we clearly haven't filtered out photos with accessories (eg. glasses), and the frontalization process itself has put the face landmarks in the right positions, but not without some distortion.
In brief, there's a lot of noise left in this dataset, and since they form the very targets the model is supposed to learn, the noise actively ends up harming the model as well, and visibly alters nearly every single image it generates:

Attempt Two
So, the problem we need to solve, is that we need a dataset with less random variation, i.e. a more consistent dataset. Taking another idea of Cole et. al.'s paper, let's just average all the images of a person, to generate an "average" image.

Since the images are already aligned, it's simply a matter of taking the average of their raw pixel values. Even from a single example, the benefits are apparent: the lighting variations, accessories and other noisy elements have all been, effectively, averaged away, producing a soft, evenly lit photo of the person. (Even better would have been to completely filter out images with accessories, heavy tilts or strong emotional expressions, but we're attempting to keep things straightforward here).
Unsurprisingly, we run into yet another problem: to make an average photo of a person, you obviously need multiple photos of that person. Only 870 identities of the 5490 in our training set have at least 3 images. Once the images are generated, we only have 870 images, one per identity, compared to the 12697 we had previously.
Still, we run with this, and like previously, train this for 150 epochs, monitoring the training loss and the average distance metric. We get the lowest average distance at the end at epoch 150, with an average distance of 0.465. The average distance decreases at every epoch (instead of flattening out or going up, which would suggest overfitting), suggesting the model could potentially benefit from longer training.
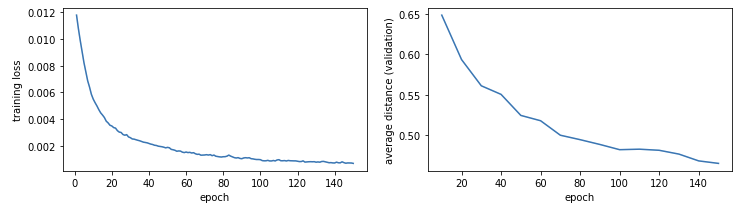
We then load in the parameters from epoch 150, and like previously, use it to compute the distance metric for each image in the test set. We keep the threshold at 0.6.
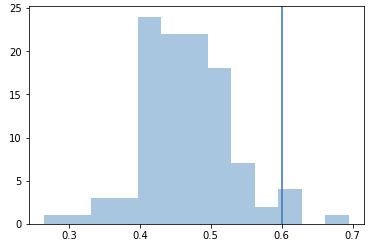
At a threshold of 0.6, about 96% of the images would be classified as belonging to the same person, which is slightly better results compared to using un-averaged images (and quite possibly identical, when you take into account variation in final results across training runs even with the same data). The average distance on the test set is 0.467, which is considerably lower than the previous run as well. At the same time, the false negative samples are even further away from the threshold, some close to 0.7.
This suggests that on average, the model is better at synthesizing images that resemble the person they're supposed to be of, but it fails more harshly on its failure case. This makes sense, as we have much higher quality samples than before due to averaging, but also far fewer of them too, making certain inputs more "unfamiliar" to the model.
Still, at less than 1/10th the previous number of images, this is great. And more importantly, the images are definitely better:
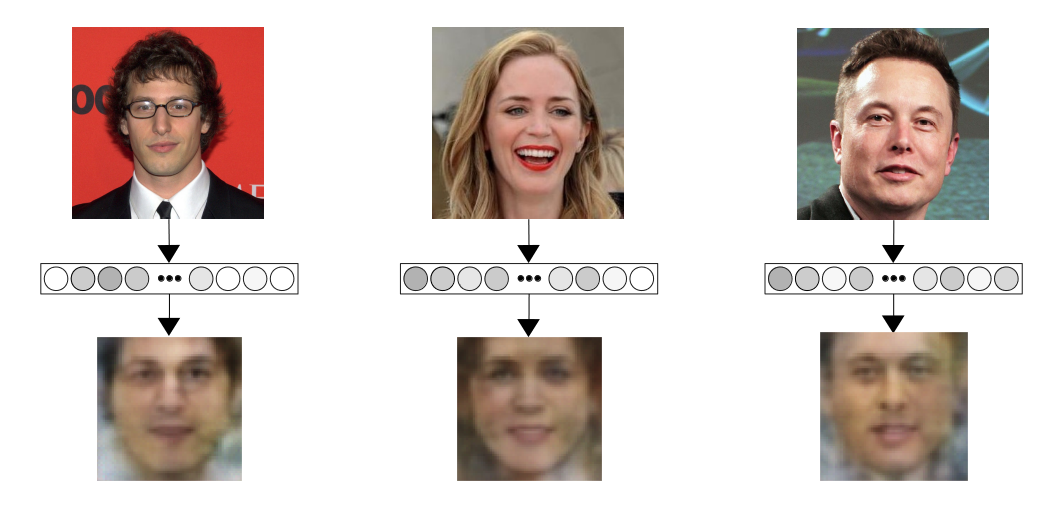
While they're certainly not high quality GAN samples, we did answer the question we originally set out to answer: we can, with a few optimizations, indeed train a model to convert the embeddings produced by a face embedding network back to images.
Black Boxes and Commercial Systems
We could very well end the article at the previous paragraph, but while writing this, I did have an interesting observation: we never actually require access to the parameters of the original face embedding model. For all we care about, it could entirely be an inaccessible black box; we only require access to its outputs, even that only once, when generating the data for training. So what if, instead of using dlib to generate the embeddings like we did for the previous two experiments, I got my embeddings from somewhere else?
Clarifai is a computer vision startup, and one of their beta products is indeed what we’ve been talking about all this time: a face embedding model intended to be used for face recognition applications. You simply pass in the filename to an image, which is sent to the cloud, and it returns you a JSON object containing embeddings for all detected faces in the image, as described here.
How about we pass in all 870 images in the training set to their cloud service, and save the embeddings we get back to disk, and use these new embeddings as the inputs instead? After the embeddings are saved, this is fairly straightforward; the only change we need to make is altering the input size of our Generator from 128 dimensions to 1,024, the length of the embeddings returned by the API.
Then, we just train like we previously did, for 150 epochs. We don't have access to validation metric though, since I'd need to obtain an embedding for all 114 synthesized validation set images every time we compute that metric (and since I'm using the "Community" tier, I'm limited to 5,000 API calls total). Getting the model with the best validation metric is more of a bonus though, to prove that this works, a "good enough" model is fine.
We load in the parameters from the epoch 150, and after fetching the embeddings for our visualization set, pass them into the network and visualize the results:
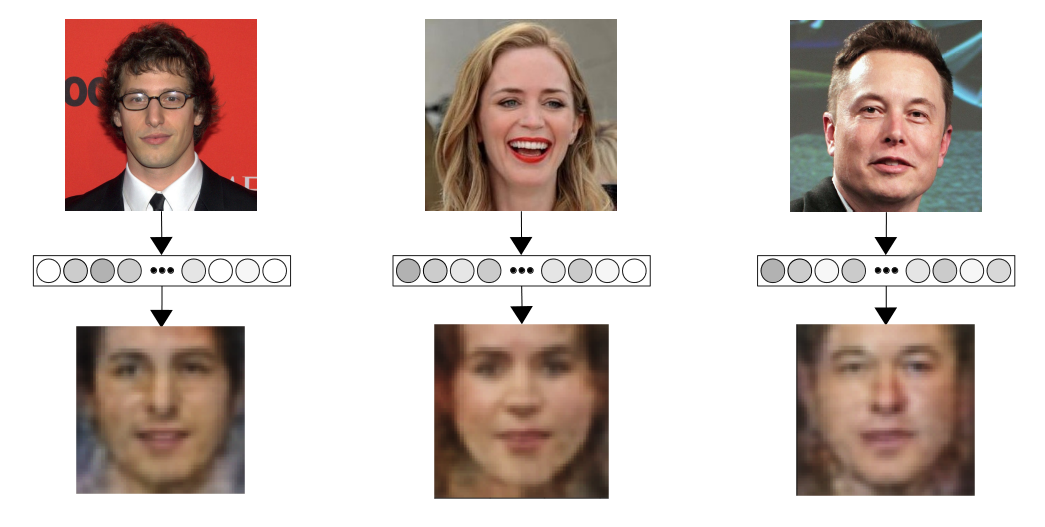
With 1,024 dimensional vectors with much more information, the results are even better than the experiments with the dlib generated embeddings. We'd ideally like to quantify how good the results are, so, I also fetched the embeddings for all the images in the test set, and after using them to synthesize images, the embeddings of the synthesized images as well. We can now visualize the distribution of the distance between the true image embedding and synthesized image embedding, just like we did previously:
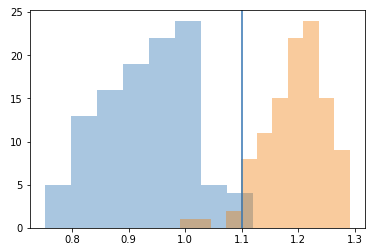
We need to pick a new threshold, since we're using a different model than the previous two entirely. Hence, assuming a threshold of 1.1, 98% of the synthesized images would be identified as an image of the same person the embedding was generated from, with the average distance being 0.932.
So, not only are the results visually great, we also have a fair amount of confidence that the decoding method we've set up is reliable. To summarize, with 870 images, we've successfully set up a method to decode any embedding produced using a cloud-based face embedding API, despite having no knowledge of the parameters or architecture of the model being used.
More Questions
It is perhaps natural to ask, does this raise any new security threats for face recognition systems? I'd argue no. Instead, I believe it doubles down on the importance of keeping your embeddings secure and encrypted if they aren't already. If someone were to attempt to create a security threat for a face recognition system, there are much easier ways to do this:
- If you want to fool a system into believing you're someone else, it's probably easier to just go to that person's social media profile and use a photo from there. (And neither this, nor decoding someone's face will work if the camera has depth sensors, which any camera intended for biometric authentication in 2019 will)
- If you wanted to identify all the people with access rights to the lock in question, it'd probably be easier to copy the list of names stored as strings than to attempt to decode the stored embedding vectors.
But if you really did want to prevent someone from decoding embeddings from your face embedding model, there are ways to do this:
-
If using on-device face recognition
- If you are performing security intensive applications (eg. building a smart doorlock), you ideally should keep your embeddings encrypted, and computations on them performed away from all other programs. Apple does a good job at explaining this in their Face ID whitepaper, where they describe how a portion of their bionic processor is dedicated to this task (the secure enclave), and that the embeddings never leave this region.
-
If you are a cloud service provider
- The primary point of concern isn't everyday applications of face recognition, such as in say, a photo album app using it to cluster faces.
- The best way of preventing a decoder from being built is to never expose the embeddings to begin with. If the decoding is a concern, consider altering your service to just provide the name of the person identified instead of a raw embedding; just the name of the person is very sparse information compared to the rich information an embedding provides, while being more useful to the end user as well.
The method isn't just something to safeguard against either, and could have uses, as a powerful tool to visualize a face embedding network's output space. One potential use I'd like to explore further is:
-
If we train the model on a demographically balanced dataset, could it be used as a probing device, to externally test facial recognition models for bias without access to the model itself?
LFW is not a demographically balanced dataset, and a subset of it only of people with 3 or more images is even more unlikely to be balanced (and this imbalance does show through when the model performs much worse on some embeddings than others). If however, trained on a controlled dataset, the model continues to poorly synthesize images belonging to a certain demographic, this could suggest the embeddings themselves aren't distinguishable enough to be decoded.
Moreover, it could be used to identify whether people of a certain race/ethnicity are mapped to a disproportionately larger/smaller portion of the output vector space, which would mean embeddings of that demographic would have more/less "room" to distinguish themselves in, suggesting the model hasn't been trained in a balanced way.
Conclusion
We opened this article with a rather bizarre question, but by the end, we found an appropriate architecture, thought up a way to train this, and designed our own custom, interpretable metric. We were then able to use all that to derive a way to design a general purpose face embedding decoder, that can decode the outputs from any face embedding network given only its embeddings and associated embeddings; information about the model itself not needed.
(In case you're still wondering: the answer is Emily Blunt)
Jupyter Notebooks for the replication of the results in this article can be found at the following GitHub repository. You can also run the code in a FloydHub Workspace by clicking this button:

About Irhum Shafkat
Irhum is deeply fascinated by machine learning, and its potential to produce breakthrough applications that can meaningfully improve the human condition. He's an engineer at Gaze, where he works on Computer Vision and Road Traffic Safety technologies, while also trying to figure out a way to make the most of his time while he's still in the 11th grade. Irhum is also a FloydHub AI Writer.