Introduction to Adversarial Machine Learning
Machine learning advancements lead to new ways to train models, as well as deceive them. This article discusses ways to train and defend against attacks.


Here we are in 2019, where we keep seeing State-Of-The-Art (from now on SOTA) classifiers getting published every day; some are proposing entire new architectures, some are proposing tweaks that are needed to train a classifier more accurately.
To keep things simple, let’s talk about simple image classifiers, which have come a long way from GoogleLeNet to AmoebaNet-A, giving 83% (top-1) accuracy on ImageNet. But recently, there’s a major concern with these networks. If we were to take an image and change a few pixels on it (not randomly), what looks the same to the human eye can cause the SOTA classifiers to fail miserably! I have a few benchmarks here. You can see how miserably these classifiers fail even with the simplest perturbations.
This is an alarming situation in the Machine Learning community, especially as we move closer and closer to adopt the use of these SOTA models in real world applications.
Why is this important?
Let’s discuss a few real-life examples to help understand the seriousness of the situation.
Tesla has come a long way, and many self-driving car companies are trying to keep pace with them. Recently, however, it was seen that SOTA models used by Tesla can be fooled by putting simple stickers (adversarial patches) on the road, which the car interprets as the lane diverging, causing it to drive into oncoming traffic. The severity of this situation is very much underestimated even by Elon (CEO of Tesla) himself, while I believe Andrej Karpathy (Head of AI, Tesla) is quite aware of how dangerous the situation is. This thread from Jeremy (Co-Founder of Fast.ai) says it all.
In this clip, @elonmusk tells @lexfridman that adversarial examples are trivially easily fixed.@karpathy is that your experience at @tesla? @catherineols is that what the neurips adversarial challenge found? https://t.co/4OMIKcP67w
— Jeremy Howard (@jeremyphoward) April 22, 2019
A recently released paper showed that a stop sign manipulated with adversarial patches caused the SOTA model to begin “thinking” that it was a speed limit sign. This sounds scary, doesn’t it?
Not to mention that these attacks can be used to make the networks predict whatever the attackers want! Not worried enough? Imagine an attacker who manipulates road signs in a way such that self-driving cars will break traffic rules.

Here’s a nice example from MIT, where they have 3D-printed a turtle and the SOTA classifiers predict it to be a rifle. While this is funny, the reverse, where a rifle is predicted as a turtle, can be dangerous and alarming in some situations.
To further this point, here’s another example: imagine a warfare scenario where these models were deployed at scale on drones and were tricked by similar patches to hijack the attack on different targets. This is really terrifying!
Let’s take one more recent example, where the authors of the paper developed an adversarial patch that, if worn by a human, the SOTA model wouldn’t be able to detect that human anymore. This is really alarming as it can be used by intruders to get past any security cameras, among other things. Below I am sharing an image from the paper.

I could go on and on with these fascinating and, at the same time, extremely alarming examples. Adversarial Machine Learning is an active research field where people are always coming up with new attacks & defences; it is a game of Tom and Jerry (cat & mouse) where as soon as someone comes up with a new defence mechanism, someone else comes up with an attack that fools it.
Table Of Contents
In this article we are going to learn about a handful of attacks, namely how they work and how we can defend networks against these attacks. The attacks will be completely hands-on, as in the attacks will be explained along with code samples.
Attacks
Defences
Let’s Dive in!
Let’s keep our focus on image classification, in which the network predicts one class given an image. For image classification, convolutional neural networks have come a long way. With proper training, given an image, these networks can classify the image in the right category with quite high accuracy.
To keep things short and simple, lets just take a pretrained ResNet18 on ImageNet, and use this network to validate all the attacks that we will code & discuss. Before getting started, let’s just make sure we’ve installed the library we will use throughout this article.
This library is called scratchai. I developed and am currently maintaining this library. I’ve used it for my personal research purposes and it’s built on top of PyTorch.
pip install scratchai-nightly
If you are thinking "woah! An entire new library! It might take some time to get familiar with it…", then stay with me- I built it to be extremely easy to use. You will see in a moment.
As said above, we need a pretrained ResNet18 model: what are we waiting for? Let’s get that! Fire up your python consoles, or Jupyter notebooks or whatever you are comfortable with and follow me!
Or just click on the below button and you will find everything already set!

from scratchai import *
net = nets.resnet18().eval()
That’s it! You now have loaded a resnet18 that was trained on Imagenet :)
Told you, it cannot get easier than this! Well, we are just getting started ;)
Before fooling the network, let’s make a sanity check: we will test the network with a few images and see that it's actually working as expected! Since the network was trained on ImageNet, head over here -> imagenet_labels and pick a class of your choice, search for that image on the internet and copy its URL. Please, make sure it's a link that directs to an image and not a base64 encoded image. Once you have the URL, here's what you do:
one_call.classify('https://i.ytimg.com/vi/wxA2Avc-oj4/maxresdefault.jpg', nstr=net)
('gorilla, Gorilla gorilla', 20.22427749633789)
I searched 'Gorillas' on Google, pasted a link as a parameter, and I just classified the image. Using just a link! No downloads, no nothing! Pure awesome :)
Feel free to grab images off the internet and classify them and test how the network works.
When you are done playing with the one_call.classify API, take a deep breath cause things are going to break now, and this is gonna be a pretty interesting turn of events.
Time to attack the network! Let’s introduce some security concept here.
Anatomy of an attack
Threat Modeling, in Machine Learning terms, is the procedure to optimize an ML model by identifying what it's supposed to do and how it can be attacked while performing its task and then coming up with ways in which those attacks can be mitigated.
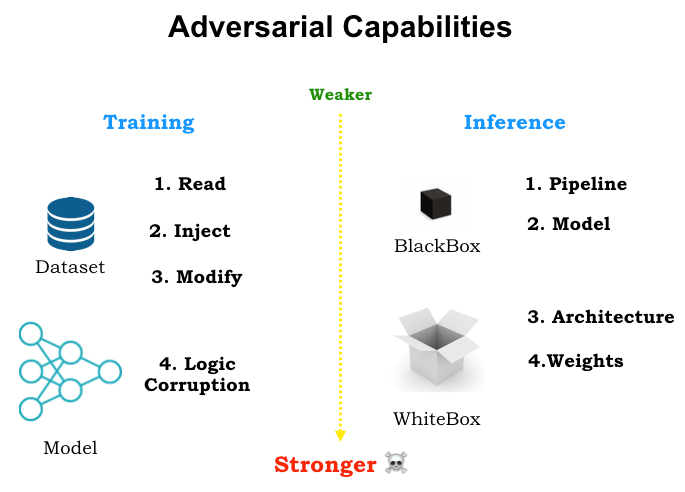
Speaking about attacks, there are 2 ways in which attacks can be classified:
- Black Box Attack
- White Box Attack
What is a Black Box Attack?
The type of attack where the attacker has no information about the model, or has no access to the gradients/parameters of the model.
What is a White Box Attack?
The opposite case, where the attacker has complete access to the parameters and the gradients of the model.
And then each one of these attacks can be classified into 2 types:
- Targeted Attack
- Un-Targeted Attack
What is a Targeted Attack?
A targeted attack is one where the attacker perturbs the input image in a way such that the model predicts a specific target class.
What is an Untargeted Attack?
An untargeted attack is one where the attacker perturbs the input image such as to make the model predict any class other than the true class.
Let’s think of a road sign being attacked with the use of Adversarial Patches (stickers). And in this context, let’s take two scenarios to understand targeted attack and untargeted attack.
Say we have a stop sign, and with an untargeted attack we will come up with an adversarial patch that makes the model think of the stop sign as anything else but not a stop sign.
With targeted attack, we will come up with an adversarial patch that makes the model think that the road sign is some other sign specifically. In this case, the adversarial patch will be explicitly designed in such a way that the road sign is misclassified as the target class. So, we can come up with an adversarial patch that makes the model think that the “Stop” sign is a “Speed Limit” sign, meaning the adversarial patch will be developed in a way that it’s perceived as a “Speed Limit” sign.
That’s all you need to know. Don’t worry if you didn’t fully get this, it will become clearer in the next sections.
Before introducing the first attack, please take a minute and think of how you could perturb an image in the simplest way possible such that it is misclassified by a model?
Considering you have given it a thought, let me give you the answer! NOISE.
Noise Attack
So, what do I mean by noise?

Noise is meaningless numbers put together, such that there is really no object present inside it. It is a random arrangement of pixels containing no information. In torch, we create this “noise” by using the .randn() function, which returns a tensor filled with random numbers from a normal distribution (with mean 0 and standard deviation 1).

This is a famous image from the FGSM paper which shows how adding some small amount of noise to an image can make a SOTA model think that it’s something else. Above, we can see that a small amount of noise is added to an image of a panda which is classified by the network correctly, but after adding this specially-crafted noise, this panda image is identified by the SOTA model as a gibbon.
This noise attack is an untargeted black box attack. It’s considered untargeted because, after adding noise to an image, the model can start thinking of the image as anything other than the true class. And it’s a black box attack, as we don’t really need information about the model weights and gradients or logits to perform to create an adversarial example using this attack.
That’s the simplest, naive technique, right? It turns out that it works sometimes! If someone gives you an image with random noise on it, it won’t be easy for you to say what that image is of. Well obviously, the less noise there is, the more we can say with high confidence what the image is, and the more noise, the more difficult it will be to tell what this image is of.
Grab an image of your choice from the internet. I’ll stay put with my gorilla, and then let’s load it up!
I1 = imgutils.load_img('https://i.ytimg.com/vi/wxA2Avc-oj4/maxresdefault.jpg')
Normalize the image and resize it so we can pass it through the resnet18 model.
i1 = imgutils.get_trf('rz256_cc224_tt_normimgnet')(i1)
If you are familiar with torchvision.transforms, then all the above function does is it applies the following transforms on the image.
trf = transforms.Compose([transforms..Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
With that, let’s add some noise to the image.
adv_x = attacks.noise(i1)
imgutils.imshow([i1, adv_x], normd=True)
Simply speaking, attacks.noise just adds noise. But we will still walk through what it does later. For now, let’s just use it and see the results!

As you can see, there is so little difference between the two that a human can easily tell that both the images are of a gorilla. Cool! Now let’s see what our model thinks of this image that is perturbed with small random noise.
import torch
def show_class_and_confidence(adv_x):
confidences = net(adv_x.unsqueeze(0))
class_idx = torch.argmax(confidences, dim=1).item()
print (datasets.labels.imagenet_labels[class_idx], ' | ', confidences[0, class_idx].detach().item())
show_class_and_confidence(adv_x)
'gorilla, Gorilla gorilla' | 16.433744430541992
So, you can see that it still predicts it as a gorilla! That’s cool!
Let’s increase the amount of noise and see if it still works!
adv_x = attacks.noise(i1, eps=1.)
Let’s look at it.
imgutils.imshow([i1, adv_x], normd=True)

Well, that’s a lot of noise added, and we humans can still classify it correctly. Let’s see what the model thinks!
show_class_and_confidence(adv_x)
gorilla, Gorilla gorilla | 11.536731719970703
Still a gorilla!!! That’s awesome! If you look carefully, you can actually see the confidence decreasing as we add more noise. Okay, let’s try that now by adding more noise!
adv_x = attacks.Noise(i1, eps=2.)
show_class_and_confidence(adv_x)
fountain | 11.958776473999023
Woah! And that’s it! The model fails! So, let’s just quickly look at the newly perturbed image.
imgutils.imshow([i1, adv_x], normd=True)

If you zoom into the adversarially perturbed image,you can see that a LOT of characteristics that make a gorilla a gorilla are lost completely with all this noise and thus the net mis-classifies it!
We did it!
In this instance, the changes are random and add a lot of unnecessary noise, so let’s think of something better! And before moving on to the next attack, let’s peek into attacks.noise
def noise(x, eps=0.3, order=np.inf, clip_min=None, clip_max=None):
if order != np.inf: raise NotImplementedError(order)
eta = torch.FloatTensor(*x.shape).uniform_(-eps, eps).to(x.device)
adv_x = x + eta
if clip_min is not None and clip_max is not None:
adv_x = torch.clamp(adv_x, min=clip_min, max=clip_max)
return adv_x
Let’s start from line 3 (before that, things are pretty intuitive). Explanation:
3. We create a tensor of the same shape as the input image x and then make it a uniform distribution between -eps and +eps. One can think of eps like the measure of noise that needs to be added. So, the bigger the value of eps more the noise, and vice-versa.
4. We add this eta to the input tensor.
5-6. Clip it between clip_min and clip_max, if clip_max and clip_min are defined. Clipping is the technique by which we trim all the values of the tensor between a maximum value and a minimum value. So, in our case, if clip_max is defined we clip all the values in the tensor which are greater than clip_max to clip_max and all values which are smaller than clip_min to clip_min. An example will be, if clip_max is set to 10 and we have a value in the tensor which is 11, we make that value in the tensor set to 10.
7. Return the perturbed image.
And that’s it! As simple as that! One can find the noise attack file here
Now, let’s move on to the next attack, and let’s think about what the next simplest way to perturb an image is so as to misclassify it. Think in terms of humans, to make things simpler; these models are just mini human brains (yeah, we need many more breakthroughs to reach a human-level brain, but for now, let’s just say so).
Remember how when you were young (and your brains were less trained), seeing negative images of your family photographs were fun and weird at the same time?! It was hard to make sense of them.
Well, turns out, machine learning models have the same effect on negative images. This is called the...
Semantic Attack
Before any explanation, let's see it in action!
Feel free to grab and load an image of your choice. If you are loading a new image, make sure you preprocess the image as shown above.
adv_x = attacks.semantic(i1)
imgutils.imshow([i1, adv_x], normd=True)

Alrighty! We have our new adversarial image prepared. Now let’s try and attack the network with this.
show_class_and_confidence(adv_x)
Weimaraner | 9.375173568725586
Aaaannnd it failed! It thinks it’s a Weimaraner. Let’s think about this a bit deeper. And before that, let me grab an image of 'Weimaraner' for you.

Look at the dogs! Do you see anything? What I think is that the Weimaraner class is among the class of animals present in the ImageNet dataset that have white bodies, even if not perfectly white. Since negating the image of the gorilla gives it a white body with an animal-ly shape, the network "feels" that it is a Weimaraner.
Let’s try with another image.
i1 = trf(imgutils.load_img('https://images-na.ssl-images-amazon.com/images/I/61dZAVY7vFL._SX425_.jpg'))
adv_x = attacks.semantic(i1)
imgutils.imshow([i1, adv_x], normd=True)
show_class_and_confidence(i1)
maraca | 21.58343505859375
show_class_and_confidence(adv_x)
maraca | 13.263277053833008

You will see that the image is not misclassified. So, what happened?
I am not aware of any paper that talks on this, but negating an image doesn’t always work when the features for the particular class are unique. As in the 'maraca' class, even if negated, cannot be compared with any other class, as it is unique and the features are preserved.
I guess what I am trying to say is, if the negated image has almost the same definitive features as the original image, it will be classified correctly, but if in the process of negation the image loses characteristic features and also the negated image starts looking like another class, then it’s misclassified.
As the paper suggests, if we train the model along with these negated images then we can see a much better performance of the network on the negated images along with the regular images. Let’s come back to this when we talk about defences.
So, those were the two most naive attacks there is. Now, let’s think deeper about how these models work and try to come up with a better attack! And before that let’s dive inside attacks.semantic
def semantic(x, center:bool=True, max_val:float=1.):
if center: return x*-1
return max_val - x
The semantic attack doesn’t work if the pixel values are not centered, so it must be centered. The center parameter, if true, assumes that the data in the image has 0 mean, so the negation of the image is just simple negation. Else if, the center is false, the function assumes that the pixel values in the function range in between [0, max_val], and thus to negate the image, one can just do max_val - x.
You can read more about the attack here: Semantic Attack Paper. Moving on to the next attack!
Fast Gradient Sign Method
We are going to dive deep. Get ready. The first attack we are going to look at is called the fast gradient sign method. This attack was invented by Goodfellow et al.
The neural networks that we are using learn by updates using a backpropagation algorithm, which calculates something called gradients. Each learning parameter in a neural network updates itself based on these gradients. So, let's start by looking into what exactly gradients are.
You can skip this section and jump to the FGSM section if you don't need a refresh about gradients.
What are gradients?
Gradients are basically direction and magnitude- the direction in which to move to maximize a value that we care about (that the gradient is calculated on), and the magnitude by which to move. Below is a nice image taken from Sung Kim’s YouTube tutorial that explains how exactly we calculate gradients and, in general, the Gradient Descent Algorithm.

In the image, we start from an initial point (the black dot) and the goal is to reach a global minimum, so intuitively speaking, we calculate the gradient (the direction and the magnitude) of this initial point we have, as well as the current loss, and we move in the opposite direction with that magnitude (because we want to minimize the loss and not maximize). Generally we take small steps, which is where the parameter alpha comes in. This is called the learning rate.
Let’s say that we have a gradient, 0.3, and then the direction is given by the sign of the gradient, so sign(0.3) = 1, so positive and else for a gradient of -0.3 it will be sign(-0.3) = -1. Basically, to know the direction of a gradient we take its sign.
What does the sign mean?
It gives the direction of the steepest ascent. That is the "way" in which if we move, the value of our function will increase the fastest.
What is this function and value?
Put simply, when we are calculating gradients, we have a point x and we map it through a function f to get a value y. The gradient tells us how the value y will get affected if we slightly nudge the point x. If the gradient is +g then if we nudge the value of x slightly in the positive direction, the value of y will increase by a factor g, and if the gradient is -g then if we nudge the value of x slightly in the negative direction then the value of y will increase by a factor g.
Mapping these to deep learning with images setup
xbecomes the model parametersfthe entire range of operations that is happening on a parameter, till the final output.ythe output logits (or the loss)
Note that if my input image x is of shape C x H x W, a.k.a. Channel First format (where C is the number of channels in the image, usually 3, and H is the height of the image, and W is the width of the image), then gradient g is also of shape CHW where each value of the g indicates how the corresponding pixel value in the image will affect the y when nudged.
Just remember: Gradient gives the direction in which if x is nudged, the value of y is increased by a factor of g. y is usually the output of the loss and we want to decrease it and not increase it.
This is the main reason that when training a model, we take the negative of the gradient and update the parameters in our model, so that we are moving the parameters in our model in the direction that will decrease y, thus optimizing the model.
But what does FGSM (Fast Gradient Sign Method) do?
First thing to remember is that FGSM is a white box untargeted attack.
Since we have talked so much about gradients, you have a clear idea that we are going to use gradients. But keep in mind that we are not going to update the model parameters, as our goal is not to update the model, but the input image itself!
First things first, since we don’t need to calculate the gradients of the parameters of the model, let’s freeze them.
utils.freeze(net)
All this does is go over each parameter in the model and set its requires_grad to False.
And since we need to calculate the gradients of the image, we need to set its requires_grad to True. But you don’t need to think about that. The FGSM attack function does it internally.
So, now,
xbecomes the input imagefthe model, in our case the ResNet18ythe output logits
Okay. Now, let’s describe the FGSM algorithm:
First let’s take a look at the high-level code and understand the main steps.
1. def fgsm(x, net):
2. Y = torch.argmax(net(x), dim=1)
3. Loss = criterion(net(x), y)
4. loss.backward()
5. Pert = eps * torch.sign(x.grad)
6. Adv_x = x + pert
7. Return adv_x
Yeah! That’s all. Let’s describe the algorithm:
- The algorithm takes in as input the input image and net.
- We store the true class in Y
- We calculate the loss of the logits with respect to the true class
- We calculate the gradients of the image with respect to the loss.
- We calculate the perturbation that needs to be added by taking the sign of the gradients of the input image and multiply it with a small value
eps(say0.3) - The perturbation calculated in the above step is added to the image. This forms the adversarial image.
- Output the image.
That’s it! Let’s revise steps 3, 4, and 5.
We are calculating the loss with respect to the true class and then we are calculating the gradients of the image with respect to the loss of the true class. Okay?!
What are gradients again?
They are the direction in which if x is nudged the value of y is increased by a factor of g. x is the input image, this means that the g calculated gives us the direction in which if we move the value of x it will INCREASE the value of y which is the loss, with respect to the TRUE class.
What happens if we add this gradient on the image?
We maximize the loss! This means increasing the loss with respect to the true class. Result: misclassifying the image!
This gradient is usually small, such that if we nudge the input by the g itself, chances are the image won’t be perturbed enough to misclassify it, thus we take the sign.
So, by taking the sign of the gradient we are making sure that we are taking the maximal magnitude that can misclassify the image.
And then, think of multiplying it with eps as a weighting factor, such that after taking the sign all we have is a matrix with values [-1, 0, 1], and if we weigh it with eps = 0.3 then we will have a matrix with values in [-0.3, 0, 0.3].
Thus, weighing the perturbation by a factor of eps.
Okay, now that’s it. I hope the explanation was clear enough. If you are still wondering how this works, I recommend you go through the above section again for clarification before proceeding. Let’s attack!!
adv_x = attacks.fgm(i1, adv_x)
imgutils.imshow([i1, adv_x], normd=True)
That’s how it looks; let’s think about what our model thinks of this image?
show_class_and_confidence(adv_x)
'Vulture' | 13.4566335
Alright! That’s a vulture then :) Let’s play a bit more with this attack and see how it affects the model. Grab images off the internet and start playing :)
one_call.attack('https://upload.wikimedia.org/wikipedia/commons/a/a4/White-tiger-2407799_1280.jpg',
atk=attacks.FGM)

Okay, not that bad.
Let’s look at an image of a tiger cat and see if we can reason about why the network thinks this is the case!

I explicitly found a white tiger cat, because we had a white tiger in consideration. And honestly speaking, if you don’t look at the facial structure of this cat then you cannot say very confidently whether this is a cat or a tiger. And these adversarial perturbations on the image hide the key areas on the image which allows these networks to identify what the object in consideration is.
Let’s try a few more classes.
one_call.attack('http://blog.worldofangus.com/wp-content/uploads/2016/09/african-wild-dog-1332236_1920-770x510.jpg',
atk=attacks.FGM)

'Norwegian Elkhound' is a class of dogs. I googled it, and honestly speaking if you show me closely the face of this African hunting dog, I might also think it’s a Norwegian elkhound.
Here’s a Norwegian elkhound for you.

Now, the thing is, animals have these animal-ly features which still makes the net classify the image as some animal which looks close to it. Let’s try some weird classes.
one_call.attack('http://blog.autointhebox.com/wp-content/uploads/2015/04/How-to-choose-the-right-mirror-for-your-car.jpg',
atk=attacks.FGM)

What about:
one_call.attack('https://static.independent.co.uk/s3fs-public/thumbnails/image/2017/03/21/14/childrenmaypolecreditalamy-0.jpg',
atk=attacks.FGM)

I want to particularly focus on this example, to show that it doesn’t always work. Kind of hints at the fact that the way we think it works internally is not completely correct. Each paper which describes an attack actually comes up with a hypothesis of how these models work internally and tries to exploit it.
Let’s just see two more examples and move to the next attack.
one_call.attack('https://i.ytimg.com/vi/C0Rugzrpgv8/maxresdefault.jpg',
atk=attacks.FGM)

And just because I can’t think of any more classes, let’s just take the sock class.
one_call.attack('https://volleyball.theteamfactory.com/wp-content/uploads/sites/5/2016/02/socks-royal.png',
atk=attacks.FGM)

Fine, all these are okay. We are perturbing an image with some mental model of how the model works internally and it predicts a class which is not the true class.
Let’s do something a bit more advanced than this. Nothing too new, just the Fast Gradient Sign Method Attack itself. But iteratively.
Projected Gradient Descent
Okay, that brings us to our next attack, which is called the Projected Gradient Descent Attack. This attack also goes by I-FGSM which expands for Iterative - Fast Gradient Sign Method. There is nothing new to say about how this attack works as this is just FGSM applied to an image iteratively.
This attack is a targeted white box attack. This is the first targeted attack in this article and unfortunately, is the only one we will see in this article.
Alright, we’ll peek into the code later, but for now start playing with the attack!
Do note that I will use one_call.attack whenever possible as this is just a function which wraps everything we’re doing bare-handed and fastens the experimentation process. Just remember that one_call.attack uses ResNet18 model by default, i.e. the one we are using. In case you want to change it, feel free to do so with the nstr argument, where you can just say nstr='alexnet' and pass it as the argument to the one_call.attack and it will use alexnet pretrained on ImageNet as the model of choice.
Okay, let’s start!
one_call.attack('https://3c1703fe8d.site.internapcdn.net/newman/csz/news/800/2018/baboon.jpg',
atk=attacks.PGD)

Remember: this attack does the same thing as FGSM, the previous attack we saw, but iteratively, meaning that until the image is classified it keeps applying the same algorithm over and over again, or until a certain number of iterations is reached (if the model is too robust against the attack ;) )
In this case, the net thinks it’s an Egyptian cat. Let’s look at an Egyptian cat and see if we can see any similarity between the two.

Well, one thing you can say that the body color matches a bit, but other than that it’s hard to say why the model thinks of this baboon as an egyptian cat.
Let’s do something interesting! Let’s see what the model thinks of a baboon in a different posture.
one_call.attack('https://kids.sandiegozoo.org/sites/default/files/2018-07/animal-hero-hamadryas_0.jpg',
atk=attacks.PGD)

And let’s see what a squirrel monkey looks like.

Okay! Here are the things that one should notice: a baboon was misclassified as an Egyptian cat in the first image. In the second image, a baboon is misclassified as a squirrel monkey. The first example moves completely to another species (monkey -> cat), but the second example stays more or less in the same species of animals (monkey -> monkey).
The reason for this is that in the second example the baboon image is clearer and has all identifying characteristics of a baboon and thus of a monkey also.
Remember, in our attack we simply care about perturbing the image a little so as the image is misclassified into another class and we don’t care what that other class is, as long as the attack is untargeted.
We add this minimal perturbation and the model mis-classifies it. And when we have more and more of these representative features in an image we will see that the misclassification happens within a consideration limit and if the images are occluded then we can start seeing some pretty bizarre predictions even with this simple technique. Well, there are always exceptions but this is mostly the case.
Good, now with targeted attack, we care about what class the perturbed image gets classified to. Additionally, the loop doesn’t break until the image is perturbed enough such that the image is classified into the target class, or until the maximum number of iterations is reached.
Let’s try and do a targeted attack! Exciting right?
Now, go ahead and pick an image of your choice as you did previously, but this time also pick a class of your choice! You can do so, here.
Or like this.
datasets.labels.imagenet_labels[678]
'neck brace'
Iterate over a few classes until you find one of your choice. What you need is the class number, not the string, and with that just do this:
one_call.attack('https://kids.sandiegozoo.org/sites/default/files/2018-07/animal-hero-hamadryas_0.jpg',
atk=attacks.PGD,
y=678)

BOOM! Just like that the image is now predicted as a 'Neck Brace!' Exciting and scary at the same time!
Do note that there is also a variation of the FGSM attack, which is the T-FGSM or Targeted FGSM. This attack, i.e. PGD, when ran in an untargeted manner runs the normal FGSM algorithm iteratively, and if ran in a targeted manner it runs the T-FGSM attack iteratively.
We went over the normal FGSM attack, so let’s now see how it differs from the T-FGSM.
def t_fgsm(x, net, y):
# Blank
loss = -criterion(net(x), y)
loss.backward()
pert = eps * torch.sign(x.grad)
adv_x = x + pert
return adv_x
Try to see the difference for yourself first! Then, read the next section :)
You see? Well, we take the y, the target class for sure, but then what’s the other one?In Line 3, we negate the loss. That’s all, and we have T-FGSM :) So, what does this mean?
Remember in FGSM we calculated the loss with respect to the true class and add this added the gradients calculated with respect to the true class onto the image, which increased the loss for the true class, and thus misclassifying it.
In T-FGSM, we calculate the loss with respect to the target class :) And then negate this, cause we want to minimize the loss for the target class, and calculate the gradients based on this negated loss. So what does the gradients give me? The magnitude and direction in which if I move, the loss for the target class is minimized the fastest :) And thus we add this perturbation on the image.
And so, that’s all you need to know and then PGD can be something like this:
def PGD(x, net, y, max_iter):
yt = torch.argmax(net(x), dim=1)
i = 0
while yt == y or i < max_iter:
if y is None: x = fgsm(x, net)
else: x = t_fgsm(x, net, y)
yt = torch.argmax(net(x), dim=1)
Easy to read, so I am not going to explain. You can find the implementation here. Now, let’s see this attack work on a few examples :)
one_call.attack('http://static.terro.com/media/articles/images/440/29-cicada-season.jpg',
atk=attacks.PGD)

So, we perform an untargeted attack in this example, and remember that all we do in an untargeted attack (FGSM) is increase the loss of the current class so that it gets misclassified. We add the minimal perturbation needed, and the characteristic features that the model learns about a cicada are not representative anymore, while features that the model learns make it a fly are still there. As you can see, it gets predicted as a dragonfly!
But the same thing if we do a targeted attack
# The class 341 is for hogs.
one_call.attack('http://static.terro.com/media/articles/images/440/29-cicada-season.jpg',
atk=attacks.PGD,
y=341)

And as you can see the targeted attack works and the image is now predicted as a hog!! Let’s look at a hog.

Wow! I am trying hard but it’s difficult to get how that cicada can be a hog!!
And that’s what a targeted attack can do- it adds perturbations on the image that make the image look more like the target class to the model, i.e. minimizes the loss of the target class.
Let’s see a few more.
# The class 641 is for maraca.
one_call.attack('https://gvzoo.com/cms-data/gallery/blog/animals/hippopotamus/hippo-library-2.jpg',
atk=attacks.PGD,
y=641)

And do you remember what a maraca is?

Quite bad! Okay let’s see another one.
# The class 341 is for hogs.
one_call.attack('https://i.pinimg.com/236x/f8/9b/7f/f89b7f0cf2f0a052506926cff26578bf--house-stairs-bannister-ideas.jpg',
atk=attacks.PGD,
y=341)

Nice work model!
# The class 741 is for rug.
one_call.attack('https://images.homedepot-static.com/productImages/89b0cb1d-6ce3-4fe1-8495-878efbc3ef14/svn/copper-patina-mpg-plant-pots-pf5870cp-64_1000.jpg',
atk=attacks.PGD,
y=741)

So, let’s move to the next attack.
As I said, each new attack comes up with a hypothesis as to how these models work and tries to exploit it, so this attack also does something unique.
DeepFool
DeepFool mis-classifies the image with the minimal amount of perturbation possible! I have seen and tested this; it works amazingly, without any visible changes to the naked eye.
Note that DeepFool is an untargeted white box attack.
Before diving in to see how it works, let’s just take one example. I am going to use the one_call.attack function.
one_call.attack('https://www.india.com/wp-content/uploads/2018/08/Cannon-main-3815.jpg',
atk=attacks.DeepFool)
Let’s see what it does.

Look at the middle image; can you see anything different? If you can then I’m impressed, because there is no change visible to the human eye! If you run the command and then move the cursor on the middle image then matplotlib will show you that they are not all black, i.e. [0, 0, 0], but there are actually variations!!
And that’s what I meant when I said that it perturbes the image minimally! So, how does this attack work? It’s very intuitive, actually! I will explain this in the simplest way possible.
Think about what happens in a binary classification problem (logistic regression), i.e. classification with two classes.

We have two classes and our model is a line that separates these two classes. This line is called the hyperplane. What this attack does is, given an input x, it projects this input onto the hyperplane and pushes it a bit beyond, thus misclassifying it!
Yes! That simple!
When you are thinking of a multiclass problem you can think that the input x has multiple hyperplanes around it that separate it from other classes. What this attack does is it finds that closest hyperplane (most similar class after the true class) and projects this input x onto the hyperplane and pushes it a little beyond, misclassifying it!
If you compare this to the above example you can see how the cannon was misclassified as a projector! If you think of a projector, you might notice some similarities between how a cannon and a projector looks; it’s hard to think of, but there are some.
Before starting to play with the attack on images, let’s see how the algorithm of DeepFool works. I will take this portion from another article of mine, which you can find here, and it is basically a paper summary of the DeepFool paper.

Let’s quickly walk through each step of the algorithm:
- 1. Input is an image $x$ and the classifier $f$, which is the model.
- 2. The output which is the perturbation
- 3. [Blank]
- 4. We initialize the perturbed image with the original image and the loop variable.
- 5. We start the iteration and continue until the original label and the perturbed label are not equal.
- 6–9. We consider n classes that had the most probability after the original class and we store the minimum difference between the original gradients along with the gradients of each of these classes ($w_{k}$) and the difference in the labels ($f_{k}$).
- 10. The inner loop stores the minimum $w_{k}$ and $f_{k}$, and using this we calculate the closest hyperplane for the input $x$ (See Fig 6. for the formula of calculating the closest hyperplane)
- 11. We calculate the minimal vector that projects x onto the closest hyperplane that we calculated in 10.
- 12. We add the minimal perturbation to the image and check if it’s misclassified.
- 13–14. Loop variable increased; End Loop
- 15. Return the total perturbation, which is a sum over all the calculated perturbations.
Alright, let’s now look at two equations:

This is the algorithm that helps you calculate the closest hyperplane given an input $x_0$, where,
- variables starting with $f$ are the class labels
- variables starting with $w$ are the gradients
Among them, the variables with $k$ as subscript are for the classes with the most probability after the true class, and the variables with subscript $\hat{k}_{x_{0}}$ is for the true class.
Given an input, it goes among the top classes with the most probability after the true class and calculates and stores the closest hyperplane; this is done in lines 6-10 of the algorithm. And this one:

This is the algorithm that calculates the minimal perturbation needed, i.e. this calculates the projection of the input on the closest hyperplane! This is done in line 11 of the algorithm.
And that’s all! You now know how the DeepFool algorithm works :) Let’s start playing with it!
one_call.attack('http://cdn.ecommercedns.uk/files/9/210639/3/2173433/celtic-tree-cuirass-steel.jpg',
atk=attacks.DeepFool)

Notice how the breastplate is misclassified as a cuirass which is its closest class! In case you are not familiar with what these mean: a breastplate is the armour that covers the chest area, the backplate is the one that covers the back area. When both are there together it’s called cuirass.
This is what Deepfool does, it projects the input onto the closest hyperplane and pushes it a bit beyond to misclassify it! Let’s take one more.

As you can see, the way the diaper is present in the image it closely resembles a plastic bag! And thus this algorithm adds the minimal perturbation possible and mis-classifies this as a plastic bag. Let’s try one more!
one_call.attack('https://www.theglobeandmail.com/resizer/LunAcgG8o583sIYsGQU3mEwUHIQ=/1200x0/filters:quality(80)/arc-anglerfish-tgam-prod-tgam.s3.amazonaws.com/public/KVZ6E4TVK5CMZB6RQJ4WMRTNJQ.JPG',
atk=attacks.DeepFool)

Even in this case, the algorithm perturbes the image in the smallest way possible. And the network predicts it as a trailer truck which intuitively seems to be a close class of a freight car (from how it looks).
Alright! We completed DeepFool attack. You can read more about it in the paper here: DeepFool Paper.
We saw it tested on many images, we saw the model fail many times, we even saw the model not misclassify a perturbed image once, which as I said happens because we don’t have a clear idea of how these models work internally. What we did was build a hypothesis as to how it’s supposed to work and then try to exploit it!
One more thing to remember is that these models don’t look at the shape of an object so much as look at the texture of an object. This is one of the major reasons these models fail due to small perturbations in the image. One can read more about this here: ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.
It’s worth mentioning that when these models are fed with an image, they don’t explicitly look at the shape of the object present in the image but instead at its texture, thus learning about the texture of the object of the consideration. This is one of the major reasons these models fail to small perturbations in the image.
Yes! So, that’s all I had in store for you in this article! Before concluding let’s quickly overview a few defences, as in how to defend our model against these attacks. We will not walk through code which does that, maybe in another article. I believe these are easy-to-implement steps.
Defending your models
Below I will go over some mechanisms through which you can defend your Machine Learning Model.
Adversarial Training
I think, at this point, everybody can guess what adversarial training is. Simply speaking, while the training is going on we also generate adversarial images with the attack which we want to defend and we train the model on the adversarial images along with regular images. Put simply, you can think of it as an additional data augmentation technique.
Do note that if we just train on adversarial images then the network will fail to classify regular images! This might not be the case with all attacks, but this particular thing was experimented with in the Semantic Attack paper, where the authors trained their model on just adversarial images, i.e. images produced using the semantic attack, and they saw that the model failed miserably on regular images. They trained their model on regular images and then fine-tuned the model on adversarial images. The same is the case for DeepFool and other attacks, they train the model well on regular images and then fine-tune the model on adversarial images!
Here’s a graph from the paper that introduces the semantic attack:

In the upper-left graph, which is a CNN trained on regular images and fine-tuned on negative images, the graph shows how many images was the model fine-tuned on and its accuracy on regular images. The accuracy of the model drops on regular images as we train it more on negative images, as it fits more to that distribution.
The upper-right image shows how the accuracy of the model varies for different datasets on negative images. As we train it more on negative images, it becomes quite obvious that the accuracy on negative images will increase the more we train it on negative images.
For the lower-left graph, it shows how the model performs if the model is trained on negative images from scratch. And as you can see, that it doesn’t perform well at all. It’s just the opposite case; it’s trained only on negative images, so it has a hard time classifying normal images correctly!
The lower-right image shows how the model accuracy on negative images is affected if we train the model from scratch on negative images, and as expected the accuracy increases as we use more images, reaching close to 100% accuracy with 10^4 images.
Alright, I think you have a fair idea of how to approach adversarial training, and now let’s just quickly see the defence method that won 2nd place in the NeurIPS 2017 Adversarial Challenge.
Random Resizing and Padding
Once again, the name gives it away! Given an image, what you do is you randomly resize the image of all 4 sides and then pad the image randomly! That’s it! And it works!! But, I haven’t tested it. It won the 2nd place on NeurIPS competition, hosted by Google Brain :)
Here’s what the authors did:
- Set the resizing range to be in [299, 331)
- Set the padding size to be 331x331x3
- Average the prediction results over 30 such randomized images
- Where for each such randomization you also flip the image with a 0.5 probability
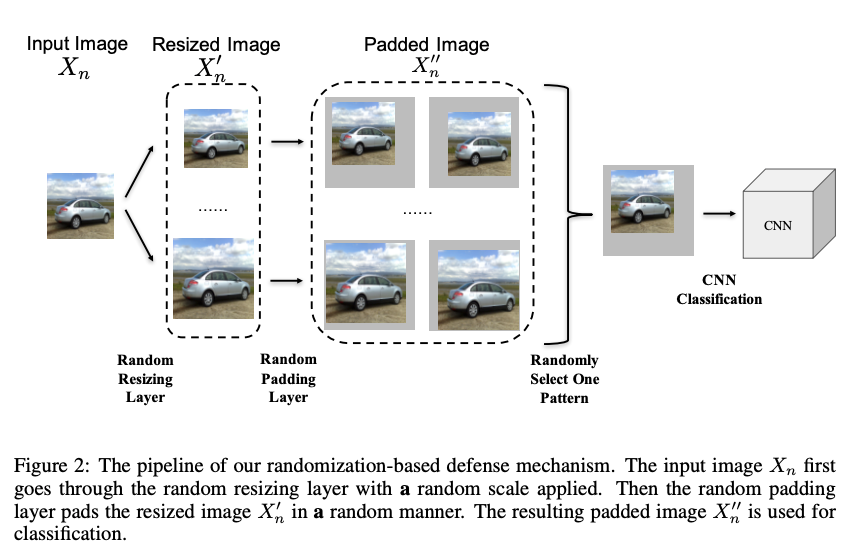
Yup! And that’s the 2nd place on NeurIPS: Mitigating Adversarial Effects Through Randomization :) The defence that won first place is called the High-Level Representation Guided Denoiser(HGD). I will skip how it works in this article and keep it for another time.
Generally speaking, this is an active research area, and I would highly suggest learning more about these algorithms in this area by reading papers and going through GitHub repositories on the same. The method that is most commonly used is that of adversarial training. This method generally gives a nice defence against already known attacks.
Among all the defences that are currently researched now, there are usages of some explicit defence algorithm for some scenarios, but in general, I think the most used defense mechanism is Adversarial Training. Please note that it is kind of a hack, as you can defend against only known attacks with certain accuracy; but it does work.
Other than that, here is a nice list that names many of the researched defences, Robust-ml Defences.
Resources
A few resources that can help you are:
- Cleverhans - This is a really nice repository from Google where they implement and research the latest in Adversarial Attacks, as of writing this article all the implementations are in TensorFlow, but for the next release all the library is being updated to support TensorFlow2, PyTorch and Jax
- Adversarial Robustness Toolbox - This is from IBM- they have implemented some state-of-the-art attacks as well as defences, the beauty of this library is that the algorithms are implemented framework-independent, which means it supports TensorFlow, Keras, PyTorch, MXNet, Scikit-learn, XGBoost, LightGBM, CatBoost, black box classifiers and more.
- Adversarial Examples Are Not Bugs, They Are Features - A really interesting point of view and discussion.
“Adversarial Examples Are Not Bugs, They Are Features” by Ilyas et al is pretty interesting.
— Chris Olah (@ch402) May 9, 2019
📝Paper: https://t.co/8B8eqoywzl
💻Blog: https://t.co/eJlJ4L8nhA
Some quick notes below.
The papers that are linked to above are a very good starting point. Apart from these, one can find links to more papers in the repositories I mentioned above! Enjoy!
Conclusion
Well, I think that will be all for this article. I really hope that this article provided a basic introduction to the world of Adversarial Machine Learning, and gave you a sense of how important this field is for AI Safety. From here, I hope that you continue to read more about Adversarial Machine Learning from papers that get published on the conferences. Also, I do hope you had fun implementing the attacks and seeing it how it works, through so many examples with just one line of code :). If you want to know more about scratchai, you can visit here.
I will be happy if someone benefits from this library and contributes to this :)
About Arunava Chakraborty
Arunava is currently working as a Research Intern at Microsoft Research where his focus is on Generative Adversarial Networks (GANs). He is learning and implementing all the latest advancements in Artificial Intelligence. He is excited to see where AI takes us all in the coming future. You can follow him on Github or Twitter to keep up with all the things he has been up to.