Getting Started with Deep Learning on FloydHub


This post is aimed at helping new users (especially the ones who are starting out & cannot afford Andrej Karpathy’s rig) setup an on-the-go deep learning solution for their small to medium sized projects. I’ll be covering the following -
- Getting started with your first DL project on FloydHub
- Handling & usage of datasets
- Installation of external dependencies (if any) while running job instances on FloydHub.
Motivation
It all started a couple of days ago when I was scouting for a cheap CUDA supported GPU solution for my college project based on VQA (because GPUs aren’t cheap here, and I'm a college student - let’s just say we’re resourceful in our own subtle ways). I was well aware of the intricacies and cost implications of AWS (among others like Google Cloud, Azure, and Bluemix) and was a bit hesitant to squander all my student credit in testing of rudimentary MLPs.
Recently, I heard about FloydHub, a startup that is attempting to change that landscape. They tagged themselves as the Heroku of deep learning and, most importantly, have affordable cloud GPU options. You can learn more about all of FloydHub's features here.
After going through their documentation (which is quite thorough!), it still took me several attempts to finally get going with my project. Most of the challenge was getting a working understanding of the FloydHub directory and instance structure for their deep learning environment.
But here I am, a couple of days in, and I'm absolutely enthralled by FloydHub - so I want to give back to the community by giving my 2 cents to on how to set up FloydHub and get going efficiently with your projects.
Initial Setup
Initial setup is fairly simple and well elaborated in the FloydHub documentation. It involves a simple sign up & installation of floyd-cli via pip. It’s a standard process that is well explained here, as well.
Project Initialization
After having created an account & setting up the floyd-cli command line tool, it is essential to understand how FloydHub manages your data & source code separately. In fact, this separation is part of the reason FloydHub works wonderfully across various fronts while designing your deep learning pipeline.
- On floydhub.com, create & name your new project (following the instructions)
- Locally, within the terminal, head over to the git repo (project directory) managing your project's source code. (Remember to keep your data- like the VGG weights etc in a separate directory- we’ll get there in a bit). Type this command to initialize your project with FloydHub:
$ floyd init [project-name]
Once that's settled, you can try creating a test file to see if everything works. Nothing extensive, a simple sequential model with Keras should suffice. Here’s one -
# test.py
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
Now, to run your first job on FloydHub's cloud GPUs, simply type:
$ floyd run --gpu "python test.py"
That should do the trick. You can check the status of this job via floyd log or in your browser via the FloydHub web dashboard.
One subtle point to see here is that FloydHub will by default execute your source in a Tensorflow based environvment. Should you want to use anything else (PyTorch, Theano, etc.), you have to specify that using the --env flag when entering your floyd run command.
Another note: Running the above script with --gpu flag will consume the GPU time allocated against your account on FloydHub. In case you’re just testing that everything is setup correctly & works fine, you can avoid using the --gpu flag, instead allocating your instance for CPU compute.
Managing datasets
Every time you kick off a floyd run command, FloydHub synchronizes your code (the entire directory) - this provides a sort of version control for your deep learning projects.
As such, it makes no sense to store the training/testing/validation data (basically anything that isn’t going to be altered for a very long time – or possibly ever) in that directory, since it is uploaded so frequently. Instead, you should upload your datasets separately to FloydHub.
Uploading data
Let's consider an example. Say you’re working with MSCOCO and you’ve obtained the VGG-net weights - vectors of length 4096 once (that’s what I was stuck with so..). And you being a nice chap, avoiding it to get into your git commit history, store it far away in some directory called coco. Put simply, now coco has all your data files (csv, mat, xlsx etc).
To upload the coco directory to FloydHub so you can use it in your jobs, navigate to the directory locally, and do the following in order:
$ floyd data init vgg-coco
Data source "vgg-coco" initialized in current directory
You can now upload your data to Floyd by:
floyd data upload
$ floyd data upload
Compressing data...
Making create request to server...
Initializing upload...
Uploading compressed data. Total upload size: 729.0MiB
764440553/764440[================================] 764440553/764440553 - 00:39:13
Removing compressed data...
Upload finished.
Waiting for server to unpack data.
You can exit at any time and come back to check the status with:
floyd data upload -r
Waiting for unpack.....
NAME
--------------------------
sominw/datasets/vgg-coco/1
If everything went well so far, you should have something like this appear in the datasets section of your FloydHub web dashboard:
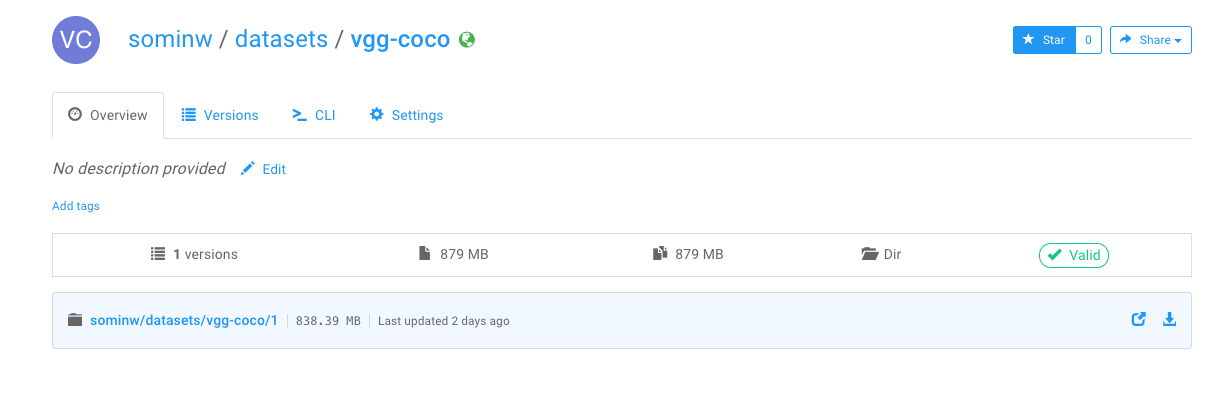
Using Datasets
FloydHub datasets are designed in a way that you can practically associate them with any project/script that you intend to run (just how you’d do on a local machine).
All you have to do is mount them while creating your instance for the job using the --data flag. According to FloydHub’s documentation, you can mount a specific version of a dataset by specify its full name and the mount point. The syntax is --data <data_name>:<mount_point>.
The pivotal thing here is the mount point, which is essentially the name of the directory under which the data is available to your code. By default, the mount point will be /input.
So in our example case, the following will make the data available to the script under execution (test.py):
$ floyd run --data sominw/datasets/vgg-coco/1:input "python test.py"
Again, here's the generic form for mounting data to your jobs:
$--data <username>/datasets/<name_of_dataset>/<version-number>:<mount-point>
Within your code (in our case test.py), you can now access your dataset with:
file_path = "/input/<filename>.csv"
Navigating your project directory
To navigate within the execution directory, FloydHub treats /code as /root. So say if you have a directory structure like the following:
.
├── test.py
└── temp
├── file.txt
Your file file.txt can be accessed from within test.py during execution by specifying its path as:
f = open("/code/temp/file.txt","rb").read()
Storing job outputs
Much like most of the workflow, a separate /output is present within the directory structure FloydHub provides, which is used to store outputs. It can store output logs as well:
floyd run "python helloworld.py > /output/my-output-file.txt"
model.save_weights("/output/MLP" + "_epoch_{:02d}.hdf5".format(k))
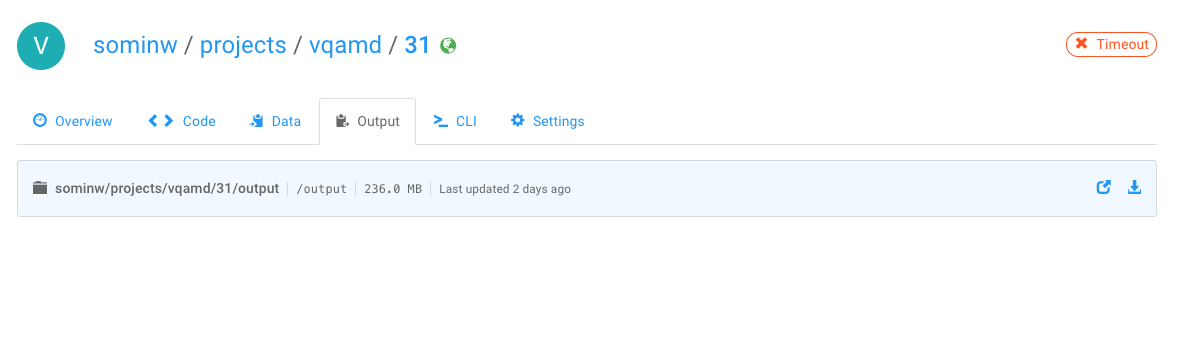
Instances and Dependencies
FloydHub comes with most core DL dependencies pre-installed – numpy, scipy, SpaCy, etc. In case anything is additionally required, it can be specified within a file named floyd_requirements.txt. This file is automatically created with you run floyd init. Some of the other detailed instructions regarding installing external dependencies is given in FloydHub’s official docs.
However, this was one of the areas where I got stuck. I was trying to load SpaCy language models for English to access WordVectors, but FloydHub environments only have the binaries. You need to install language model for the language you’re using yourself. The process is pretty straightforward, except one small subtlety – FloydHub instances.
Every time you run floyd run command, you are getting a new instance.
What this means is that every time you execute your script, dependencies have to be reinstalled. For instance, if I run:
floyd run "python -m spacy download en" & floyd run "python test.py"
In this case, spaCy won’t be of any use because those are separate instances! Instead, we need to run both the dependency installation and the script in a single instance:
floyd run "python -m spacy download en && python test.py"
Try it out
Eventually, if everything goes accordingly, you’d be looking at spinning a NVIDIA Tesla K80 Machine Learning Accelerator & watching it slice through image/text processing tasks like butter! ❤️
About Somin Wadhwa
Somin is currently majoring in Computer Science & is a research intern at Complex Systems Lab, IIIT-Delhi. His areas of interest include Machine Learning, Statistical Data Analysis & Basketball.
You can follow along with him on Twitter or LinkedIn.
We're always looking for more guests to write interesting blog posts about deep learning. Let us know on Twitter if you're interested.