Benchmarking FloydHub instances


This post compares all the CPU and GPU instances offered by FloydHub, so that you can choose the right instance type for your training job.
Benchmark
For our benchmark we decided to use the same tests as used by the Tensorflow project. The Tensorflow benchmark process is explained here. AlexNet model was tested using the ImageNet data set for this benchmark. We are planning to add results from other models like InceptionV3 and ResNet-50 soon. You can find the FloydHub project with the benchmark runs here and the Github repo here.
Update (12/14/2017): We have now added benchmark results for InceptionV3, Resnet-50, Resnet-152 and VGG-16.
Update (08/08/2018): Added benchmark results with Mixed Precision Training for GPU2.
Sneak preview of results
Here is the quick results from benchmarking before we go in to the details. You can compare the performance of each instance by the number of images it
can process per second.
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 32 | 9 |
| CPU2 | 64 | 34 |
| GPU | 512 | 662 |
| GPU2 | 1024 | 4700 |
| GPU2 (MXP) | 2048 | 7200 |
Continue reading to learn more about the setup.
Performance Tuning
We also followed various performance optimizations recommended in the Tensorflow best practices guide
Data Format
For our benchmarks we will be using the NHWC format for the CPU instances and NCHW for the GPU instances to take advantage of cuDNN. This is again as recommended by Tensorflow.
Fused Ops
Using fused batch norm can result in 12-30% speed up. In our code we enabled this by setting:
bn = tf.contrib.layers.batch_norm(input_layer, fused=True, data_format='NCHW')
You can learn about this in Tensorflow documentation.
Mixed precision training
Another optimization we did is to use Mixed precision training: this techinque lowers the required resources by using lower-precision arithmetic. This decreases the required amount of memory and enables training of larger models or training with larger minibatches. It also shortens the training or inference time because half-precision halves the number of bytes accessed, thus reducing the time spent in memory-limited layers. This is an experimental feature but gives significant speed boost.
Building Tensorflow from source
To optimize the performance it is recommneded to build and install Tensorflow from source. All the FloydHub environments are
built from source and optimized for the specific instance type.
Instances
For this post we will be comparing 2 CPU instances (CPU, CPU2) and 2 GPU instances (GPU, GPU2):
| Instance | CPU Cores | Memory | GPU Type | GPU Memory |
|---|---|---|---|---|
| CPU | 2 | 8 GB | - | - |
| CPU2 | 8 | 32 GB | - | - |
| GPU | 4 | 64 GB | Nvidia Tesla K-80 | 12 GB dedicated Memory |
| GPU2 | 8 | 64 GB | Nvidia Tesla V100 | 16 GB dedicated Memory |
Data
We used synthetic data for all the tests. Synthetic data removes disk I/O as a variable and historically the numbers for real data is very close to synthetic data. But we are also planning to run another round of benchmark tests with real data soon.
Synthetic data is randomly generated by using tf.truncated_normal then normalized in range [-1,1] and set to the same shape as the data expected ImageNet.
Sample image generated this way:

Results
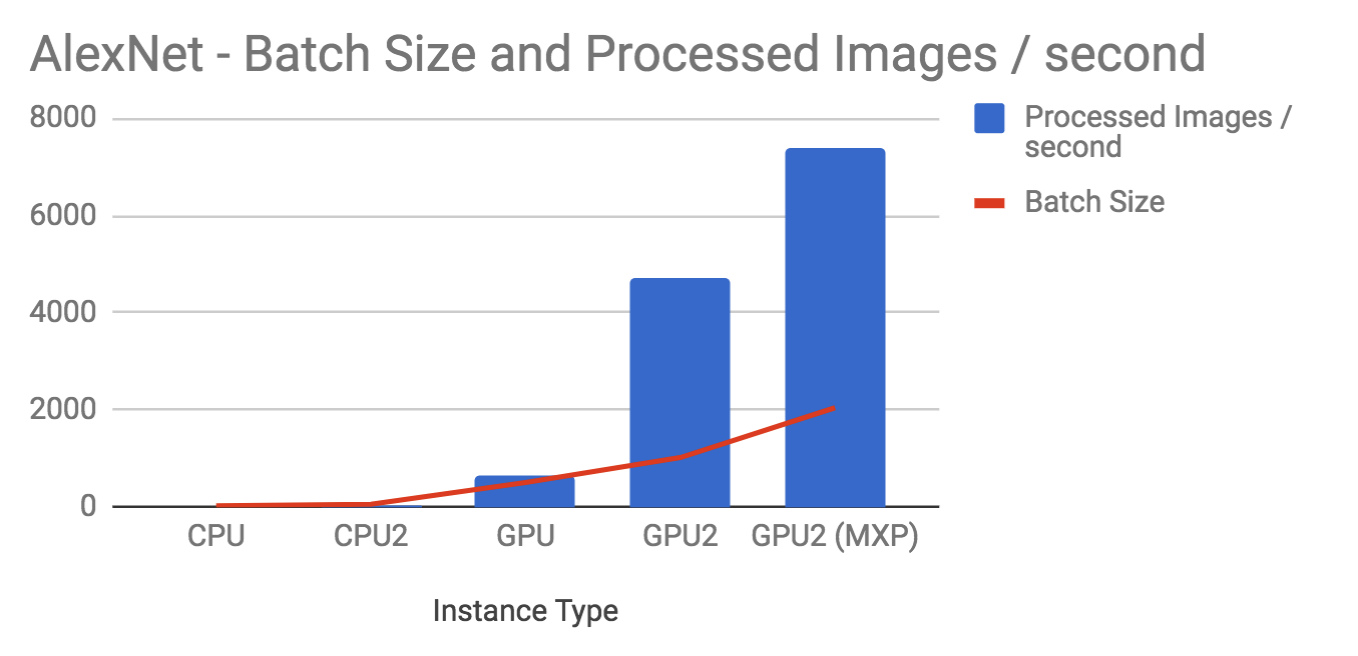
Alexnet
Below are the results of testing Alexnet with the synthetic data. As you can see the batch sizes are different - we picked the batch size the utilizes the memory available in each instance as much as possible.
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 32 | 9 |
| CPU2 | 64 | 34 |
| GPU | 512 | 662 |
| GPU2 | 1024 | 4700 |
| GPU2 (MXP) | 2048 | 7200 |
The GPU instances are orders of magnitude faster than CPU instances. And the new GPU2 instance performs about 7x the standard GPU instance.
Note:
Full training over Imagenet (about 100 epochs on 1.2 images dataset) takes about 7-8h on GPU2 and more than 2 days on GPU.
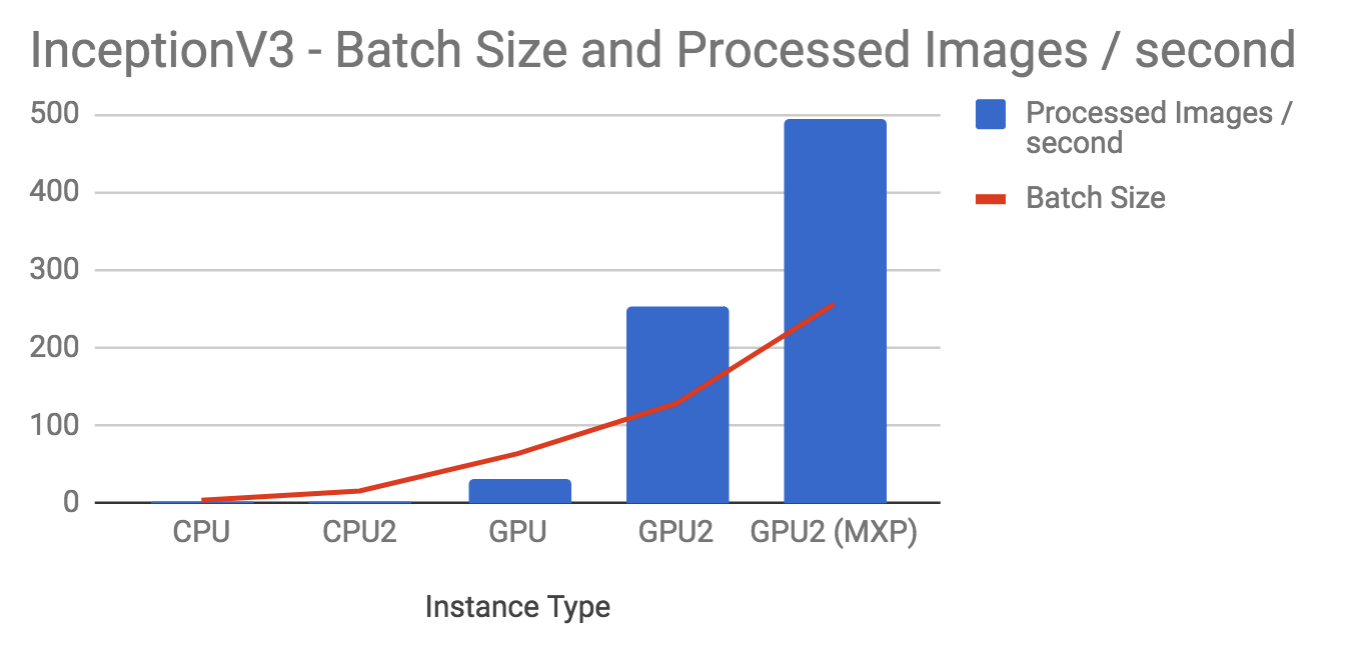
INCEPTION V3
Here are the benchmark numbers for InceptionV3.
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 4 | 1 |
| CPU2 | 16 | 2.8 |
| GPU | 64 | 31 |
| GPU2 | 128 | 253 |
| GPU2 (MXP) | 256 | 495 |
Note:
Full training over Imagenet (about 100 epochs on 1.2 images dataset) takes about 5 days on GPU2 and more than 45 days on GPU.
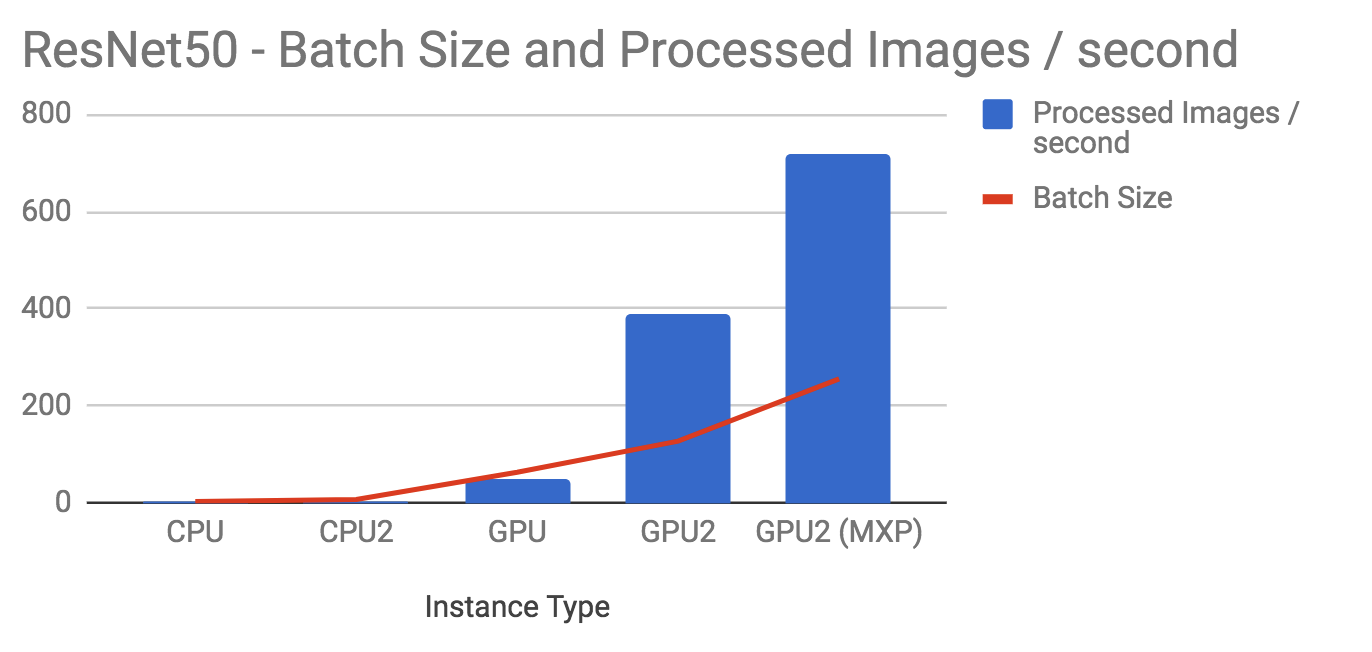
Resnet-50
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 4 | 1.4 |
| CPU2 | 8 | 2.7 |
| GPU | 64 | 52 |
| GPU2 | 128 | 387 |
| GPU2 (MXP) | 256 | 717 |
Note:
A full training over Imagenet (about 90 epochs on 1.2 images dataset) takes 3 days on GPU2 and about 24 days on GPU.
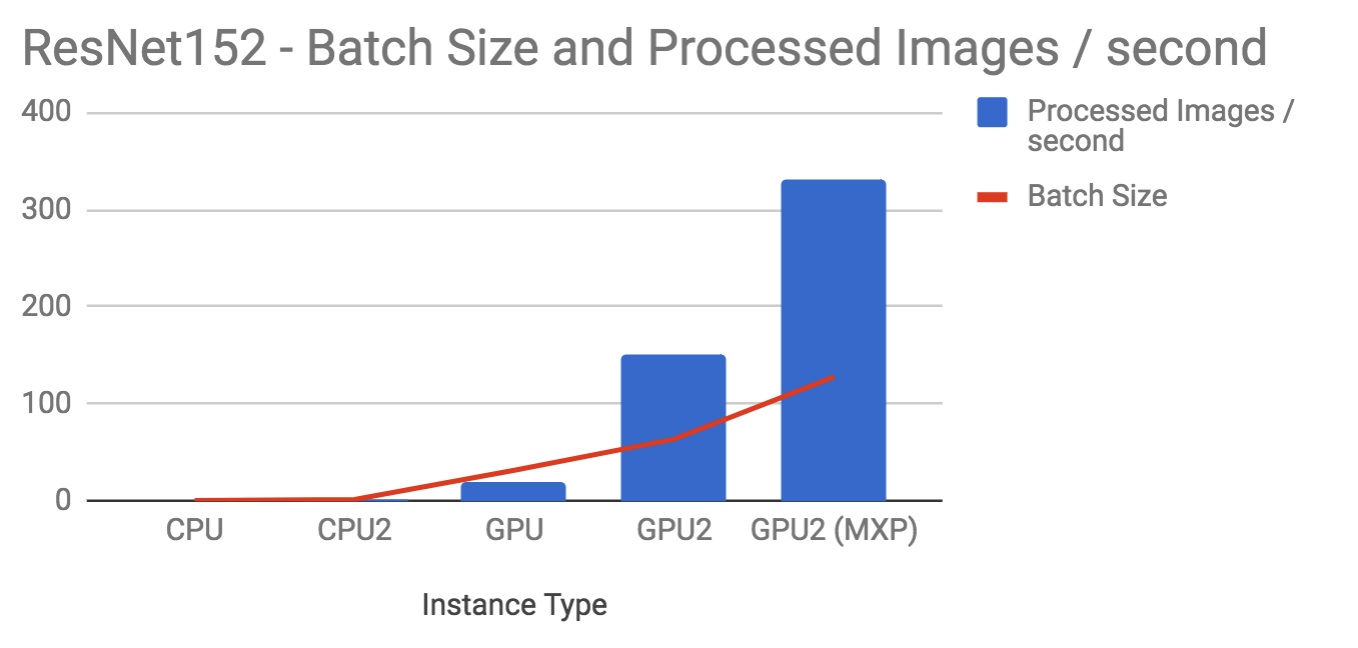
Resnet-152
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 1 | 0.5 |
| CPU2 | 2 | 1.5 |
| GPU | 32 | 20 |
| GPU2 | 64 | 152 |
| GPU2 (MXP) | 128 | 330 |
Note:
A full training over Imagenet (about 100 epochs on 1.2 images dataset) takes 9 days on GPU2 and about 70 days on GPU.
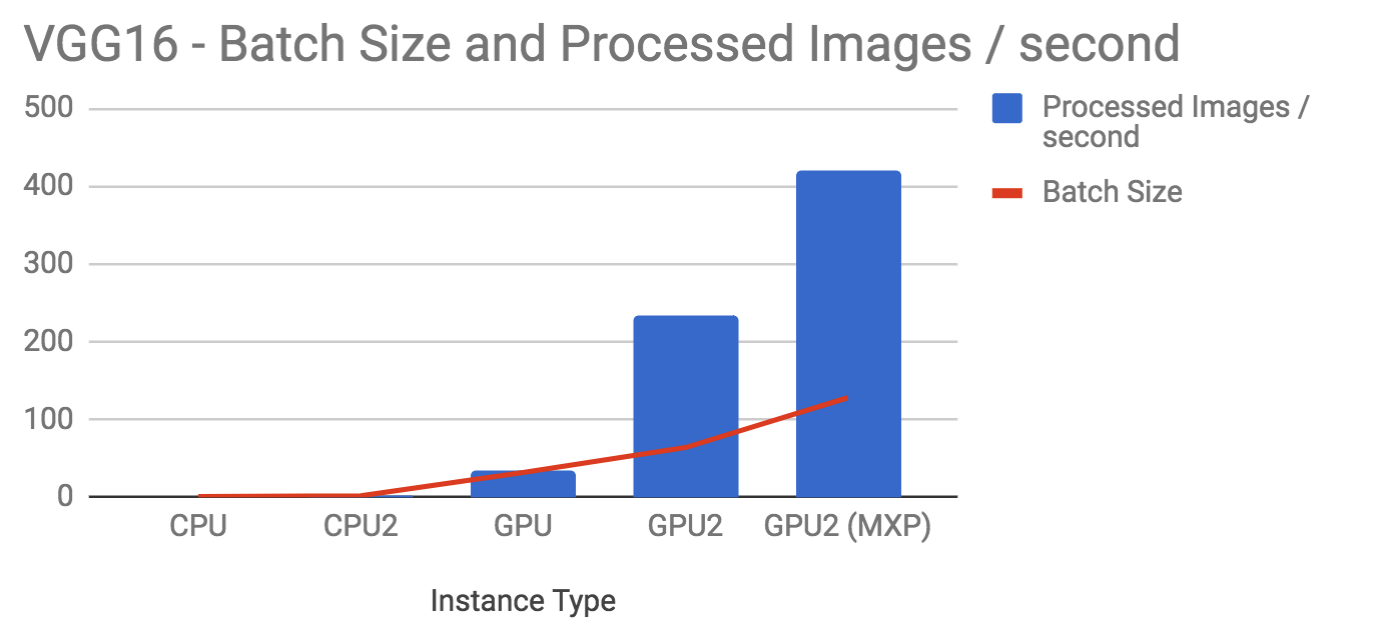
VGG-16
| Instance | Batch Size | Images/second |
|---|---|---|
| CPU | 2 | 0.5 |
| CPU2 | 4 | 1.5 |
| GPU | 32 | 36 |
| GPU2 | 64 | 234 |
| GPU2 (MXP) | 128 | 420 |
Note:
A full training over Imagenet (about 74 epochs on 1.2 images dataset) takes 5 days on GPU2 and about 38 days on GPU.
Up Next
We are planning to keep this post as a live document. When we run new benchmarks on FloydHub we will update the results here. We are hoping you can always refer to this page when making a decision about which FloydHub instance to choose for your next project.