AWS Cost Optimization for ML Infrastructure - EC2 spend
[Series] Based on his deep experience, FloydHub CTO Naren discusses how should companies think about & setup their ML infrastructure. This article focuses on AWS EC2 machines.


AWS is currently the market leader in the cloud infrastructure space with nearly 50% market penetration. With substantial investments in AWS already existing in organizations, as a natural extension, AWS EC2 is the most widely used building block for Machine Learning projects. Machine Learning requires a large amount of flexible compute capabilities to develop, train and test models. Organizations often spend a large amount of money on EC2 as their data science team ramps up model training. This guide offers practical advice on how to setup machine learning infrastructure at your company to get the most out of the EC2 instances and optimize your overall AWS EC2 bill.
Extracting knowledge and insights from data is an inherently experimental and iterative undertaking. As organizations begin to adopt machine learning techniques to solve business problems, they look to develop new mental models and processes to integrate data science into their operations. Studying the evolution of their computational needs over time can provide organizations with extremely valuable and unambiguous inputs into strategic long-term thinking. This guide also shows you how to monitor and measure your EC2 usage to get such inputs.
Who should read this guide?
not data scientists
You will find this guide most useful if you are a:
- Head of Data Science / Chief AI officer
- Head of infrastructure / ML Infrastructure lead
- VP of engineering / CTO
This guide is not meant for data scientists. The recommendations offered here are not directly actionable by them.
When should you adopt these strategies?
Organizations undergo distinct transitions in their adoption of Machine Learning techniques to solve business problems. All teams undergo a pilot phase where they are testing the applicability of Machine Learning techniques. The strategies provided in this guide are not applicable to companies in this phase. In many cases, these strategies are distractions and slow down the pilot phase.
Use this guide when you are scaling ML solutions, not when you are just starting your ML adoption.
Once organizations have established a clear ROI for continued investment in Machine Learning, they undergo a phase of maturation where they look to develop best practices and establish standard processes to stabilize their Machine Learning setup. This guide is applicable to teams in this phase.
Some general markers of this phase are:
- Your team has 3 or more data scientists working full time on ML or DL projects.
- You have identified a roadmap of ML projects for the team to work on for at least 1 year.
- The annual AWS bill for the ML team is upwards of $10,000 or has ascended to over 10% of your total AWS bill.
- Your infrastructure team is starting to build specific tools for your data science team.
Thinking strategically about cost optimization

When it comes to machine learning infrastructure it is imperative to balance reducing the cost of cloud infrastructure against productivity of your data science team.
Remember that you are paying your data scientists a lot more than the EC2 machine.
Sometimes, you will need to run extra machines so that your data scientist does not have to wait 15 minutes for a machine to become available before they can start training. You may need to build tools to have your cloud machines running before a data scientist starts their day. Some machine learning experiments need to run overnight or through the weekend to generate useful output. Remember that you are paying your data scientists a lot more than the EC2 machine.
Giving your data science team enough breathing room to experiment is essential to attaining results and motivating them to grow your organization’s AI capabilities. This guide offers techniques that maintain productivity of the data scientist as a central consideration while still optimizing for cost.
How this guide is structured
Different phases in the lifecycle of an ML project present opportunities to make decisions that yield optimal usage of your cloud infrastructure. This guide is broken into four sections that provide specific recommendations for certain phases.
The section on the setup phase offers guidance on making good upfront decisions when you start a new ML project or setup a new ML team to work on EC2. The tooling section has commentary on tools that we have seen dozens of ML teams use to increase their effectiveness on cloud machines. This section is meant to be a growing set of recommendations for you to consider discussing with your data scientists. The monitoring section offers essential advice and best practices on setting up metrics to keep track of ongoing operations of your team and their changing needs. The billing and purchase planning section reviews best practices for keeping track of your spending. We also provide tactical advices for making bulk purchases through the AWS reserved instances and the EC2 savings plans.
Setup
This section covers advice on EC2 during the initial setup phase for an ML project. Even if your team has already done the setup, it is useful to carefully go over these techniques.
Choosing an AWS region

Choosing an AWS region is, in most cases, not a per-project decision. It is worth your time to investigate your options to make a decision upfront for your ML infrastructure.
While choosing an AWS region for machine, several factors are useful to consider.
- Existing region selection - If your company already uses AWS and has picked a region for your cloud infrastructure, you should default to using the same region for ML projects. There are circumstances where you should stray from this convention – we go over them while discussing the other factors. Using your existing region yields the ability to reuse a lot of your existing AWS configurations. It also makes data transfer between your systems much simple.
- Cost - AWS prices the machines differently in different regions. For example, at the time of writing this guide, a p2.xlarge (Tesla K-80 machine) costs $0.90 in the Oregon region vs $1.718 in the Mumbai region. Typically, instances in the US regions tend to be the most affordable, followed by the EU regions and then the rest of the world. If your data science team uses specific instance types, it is useful to compare prices across regions to understand if this is a factor for your setup.
- Proximity - If your team is planning to move data from your company data center into AWS for ML projects, you should consider picking a region that is physically closer to you. This will make a significant positive impact on data transfer rates. For data scientists who upload and download large amounts of data to build models, this translates directly to a boost in productivity and efficiency.
- Compliance - If you have any compliance considerations around the data you are planning to upload to AWS, or foresee such considerations, choose a region that takes this into account. A common use-case is training ML models on EU user data – you will want to choose an AWS region in Europe to be compliant with EU regulations.
- Hardware availability - AWS regions don’t all stock the same hardware. If you anticipate the need for specific types of machines for your ML projects, it is essential to check if they are available in your region. If they aren’t, choose the region closest to the rest of your AWS infrastructure that has the machines you need. For example, Tesla K-80 GPU machines are not available in the Hong Kong region. The Singapore region is a logical choice in this case.
Choosing EC2 machines
AWS offers over 100 different types of EC2 machines you can choose from for your project. At a high level the machines are classified into 5 categories:
- General Purpose
- Compute Optimized
- Memory optimized
- Specialized hardware
- Storage optimized

For ML applications, picking a General purpose - "m Class" machine usually offers the most flexibility for non-GPU training. For GPU-based training, you will need one of the specialized hardware machines.
Each category has a range of machines that scale horizontally depending on your needs. For example, the m5large has 2 CPUs and 8 GB of memory. The m5xlarge has 4 CPUs and 16GB memory.
Single vs multi-GPU machines
When choosing GPU machines you have the option of getting a machine with single GPU (eg: p2.xlarge) or multiple GPUs (eg: p2.8xlarge). For ease of maintenance and use we recommend that you use single GPU machines whenever possible. Use multi-GPU machines only if there is a clear case for training complexity that saturates a single GPU machine.
As a useful rule of thumb, you will get a 5x speed up in training when using 8x the number of GPUs.
Remember that the cost of a multi-GPU machine typically scales linearly with the number of GPUs, but the performance gains do not. This is due to data communication delays between GPUs. Our peers at Lambda Labs did some useful benchmarking to highlight this effect. As a useful rule of thumb, you will get a 5x speed up in training when using 8x the number of GPUs. You need to decide if this speed up is worth the cost of running expensive multi-GPU machines.

Setting up optimized AMIs
Amazon Machine Images (AMI) are virtual machine images you can use to create your ML machines. Standard Ubuntu AMIs available on AWS are general purpose images and require optimizations to get the most out of the machines during ML training.
Here is a short-list of our recommended optimizations:
- Install the latest Operative System updates, NVIDIA drivers and CUDA for GPU machines. Latest versions of CUDA and other GPU software provide new features and the most up-to-date performance improvements.
- Build ML frameworks specific to the CPU you are using. For instance, TensorFlow can be recompiled specific to the hardware you are using. This allows the framework to take advantage of all the hardware capabilities. (Reference)
- Perform OS level tuning to set appropriate I/O limits. For instance, operating systems limit the number of open files to 1024 per process by default. ML projects often work with large data-sets and this limit needs to be significantly higher to remove bottlenecks. Similarly, network level defaults need to be tweaked to allow for large data-set downloads and improve data transfer rates.
- After fully configuring the AMI, remove any extraneous files present on the machine before finalizing it. This keeps the size of the AMI small and keeps disk space available for ML training.
Once this process is established, any one-off changes to the AMI should be prohibited to avoid drift in the configuration.
We recommend using a tool like Packer to automate the AMI creation. This allows for the organization to share best practices and continuously iterate on improving the hardware performance. Once this process is established, any one-off changes to the AMI should be prohibited to avoid drift in the configuration.
Tooling
A common strategy for running ML infrastructure for a team of data scientists is to set aside a pool of machines and let them share the resources. There are few tools worth investigating for your use case in this approach.
Docker and nvidia-docker
Docker is crucial for reproducibility, but it requires some attention to fit it properly in your infrastructure
A standard best practice is to use Docker to run ML training on the AWS machines.

Docker isolates training processes and gives a brand-new container for every launch of your EC2 instance. This ensures that the environment is exactly as your data scientists want it to be every time. This is crucial for reproducibility.
Docker purges all the extraneous files after each run. There is no old state left around for your data scientists to get confused about. On the flip side, this also means that your data scientists should save all the work they want to retain on disk before they shut down the machine. Work with them to setup a standard operating procedure or file structure on disk.
Your infra team can manage all the docker images and make new updates easily available. The data scientist can just use the "latest" version of the framework they want to use and it should work seamlessly. This also makes pushing new security and performance patches very easy. nvidia-docker works with CUDA and all the GPUs. There are CUDA optimized docker images that work well for GPU environments.
FloydHub’s DockerHub is a resource to get optimized docker images for the most popular machine learning and deep learning frameworks.
Kubernetes

Kubernetes is an open source project for managing & orchestrating docker containers. It is primarily used for running production software using Docker. Recently, Kubernetes has been adding support for managing ML hardware clusters including GPU hardware.
We recommend that you use Kubernetes only if you can identify a very clear need for it. Kubernetes is difficult to set up and manage.
We recommend that you use Kubernetes only if you can identify a very clear need for it. Kubernetes is difficult to set up and manage. It is optimized for long running web services and requires some amount of tweaking to get it to run ML training jobs. It requires expertise from the Infra team to identify and fix operational issues. It requires a yaml config file for each training job and is not data scientist friendly. If you choose to use Kubernetes, plan to build some tooling to make it easy to interface with for your data scientists. Kubernetes works well with heterogeneous hardware clusters. So, if you have a few Tesla K80, V100 and 16 core HPE machines, Kubernetes will absorb all of them easily. When you need a place to run your ML code, you can initiate Kubernetes with your requirements - Docker image, CPU cores, memory and GPUs. Kubernetes will find the best spot for the job and create the docker container with the requested resources. You can use the Kubeflow service can be used for managing ML workflows on Kubernetes.
JupyterHub
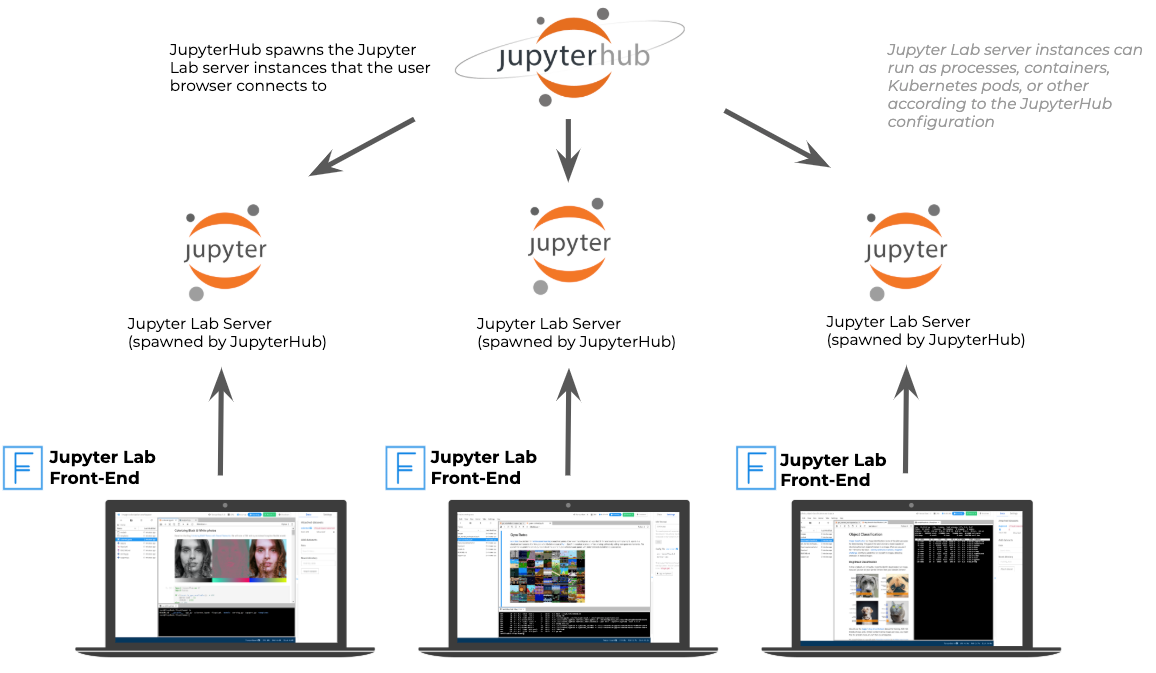
JupyterHub is another open source solution developed by the Jupyter team. It can be used for running Jupyter notebooks on a cluster of a machines. It provides an easy way for the data scientist to connect to a machine and run their Jupyter notebook projects on a familiar interface on their laptops. It works well with EC2 machines with Auto Scaling Groups (more on Auto Scaling groups later)
Monitoring
Monitoring can provide organizations with strategic inputs into infrastructure planning, talent hiring, financial forecasts and business roadmaps.
Monitoring the training infrastructure is essential to ensure that all EC2 instances are fully utilized and identify potential cost optimization opportunities. Because EC2 usage for ML changes with your team’s need for computational power, monitoring usage presents a great opportunity to study how your organization’s ML capabilities are changing over time. This can provide organizations with strategic inputs into infrastructure planning, talent hiring, financial forecasts and business roadmaps.
AWS EC2 instances come with basic monitoring that include metrics like CPU and memory usage. You can view these metrics from the EC2 or CloudWatch dashboard. We recommend that you enable detailed monitoring for more useful metrics and capture additional ML specific metrics like GPU utilization, GPU memory used and instance disk utilization.

It is also a best practice to setup separate dashboards for each cluster of EC2 machines. This dashboard should be reviewed at least once a week to spot usage patterns and under-utilized instances.
You should reviewed your dashboard at least once a week to spot usage patterns and under-utilized instances.
Work with your data science teams to setup a standard protocol for the amount of time machines can idle (typically 1-2 hours). Your infrastructure team should plan to setup alerting using CloudWatch for instances that are not actively in use based on CPU and GPU stats. Once the idle limits are hit, notify the corresponding team or the user on Slack or email to shut down the machine. This is an easy way to reduce wastage and instill best practices in the team. Once you’ve identified a protocol that works for your team, a slack bot or email to do the notification is a worthy investment.

Auto scaling groups
Auto Scaling Groups (ASG) are groups of AWS instances that share the same configuration. ASGs make it easy to scale up your cluster when there is a need from the data science team. Setup Auto Scaling Groups for each instance type you are using in your infrastructure. ASGs can be configured to actively monitor the machines and identify which ones can be turned off.
When configuring the auto scaling rules it is important to balance cost reduction with the productivity of data scientists.
You can write your own monitoring system that tags each machine in the ASG to be “Scale In protected”. These machines are protected from getting shut down when the ASG downscales. When configuring the auto scaling rules it is important to balance cost reduction with the productivity of data scientists.
Billing & Purchase planning
This section covers best practices and cost optimization techniques within the AWS billing system. This is useful for long term planning around EC2 cost.
Billing alerts
With growing usage from the data science team, your AWS bill will keep growing. To guard from unexpected surprises on your monthly invoice, you should set up billing alerts. AWS can send emails or notifications whenever your estimated bill for the current month is above a certain threshold.

We recommend that you set up multiple alerts - one for every quarter installment of your estimated monthly spend. For example, if your estimated monthly EC2 expense is $10,000, set up alerts for every installment of $2,500. This way you can ensure that your bill does not jump suddenly in the middle of the month. This also helps you understand the changing needs of your team and improve your ability to forecast future needs.
We recommend that you schedule a deep dive into your AWS EC2 expense every 3-6 months to understand patterns and detect anomalies. You can work with your data science team to discuss opportunities about cost optimization.
You can also use the AWS Cost Explorer to get details about your bill. You can break down your expenses by accounts, regions, EC2 instance types and more. You can save these reports and revisit them periodically. It is good practice to review your AWS monthly bills or invoices in detail. It gives a lot of useful information about where you are spending the most with your AWS infrastructure.
We recommend that you schedule a deep dive into your AWS EC2 expense every 3-6 months to understand patterns and detect anomalies. It can be useful to include your lead data scientist in these discussions to understand the expenses and plan future ones.
Reserved instances
AWS offers the option of reserving your EC2 machines. This means you are committing to running a certain number of instances 24x7. The upside to reserving instances, beyond guaranteed capacity, is cost savings of up to 35%. This is very useful with ML machines like V100 instances - you can save up to $700 per month on each machine.
Here are our guidelines for reserving ML instances:
- Buy reserved instances for one year - not three years. Although reserving for 3 years gives bigger discounts of (up to 60% off), hardware is improving rapidly and new hardware is introduced for ML regularly. We recommend that you don’t lock yourselves into a long-term contract.
- We recommend choosing “No-Upfront” option. This means you will pay for these reserved instances every month - this makes your AWS spend more consistent and predictable every month. Spiky expenditure is hard to keep track of and confusing when you do retrospectives of your overall AWS spending patterns.
- When reserving GPU instances, consider purchasing the “Convertible” option. This means your reserved instance quota will be applied whether you are running single or multi-GPU instances.
- Use the Reserved instance recommender tool to figure out what is a good number of instances to reserve and the cost savings you will get.
- Remember, Reserved Instances applies only to the region and availability zone you are purchasing. It cannot be used across regions.
- View the Reserved instance utilization report to track if your reserved instances are actively used. Note that the utilization may not be 100% all the time because of low usage periods like weekends and holidays. But ensure that overall you are saving cost with the reserved instances over a 30-day period.
- Track when the reserved instance contract is expiring. Setup appropriate reminders to review your usage and plan to re-purchase these instances if needed.
EC2 savings plans
This is a new cost saving option that AWS announced in Nov 2019. Savings plans are like reserved instances but instead of committing to instance usage, you are committing to dollar payments to AWS. The advantage of using Cost Savings is that your payment commitment applies to all EC2 instances across all regions. This gives a lot of flexibility to your infra cost planning.

Here are our guidelines for the Savings plans:
- Choose “General Compute” Savings Plans whenever possible. The instance specific EC2 Savings Plans is the same as the Reserved Instance plan and does not provide much flexibility.
- Use the recommender to decide how much to purchase - it shows how much you’re committing to every month and how much on-demand you will pay.
- EC2 Savings plan has its own utilization report and coverage report that shows how well you are doing with the Savings plans. Start with a small portion of your infrastructure and plan to review this after the first month to ensure you understand how the plan works before you make the full commitment.

Closing thoughts
You should start to reap benefits from our recommended optimizations almost immediately, but expect to take about 90 days to implement one full iteration of the guide.
With the field itself being nascent, an explosion of options in the last few years, and inherent uniqueness of every team's needs, getting ML infrastructure right is no walk in the park.
Having the right infrastructure is an essential part of successfully using Machine Learning to add business value - both in the short term and in the long run. With the field itself being nascent, an explosion of options in the last few years, and inherent uniqueness of every team's needs, getting infrastructure right is no walk in the park. The right choices to make are sometimes counter-intuitive - for example, allowing a certain amount of process chaos to exist while the data science team is figuring out the viability of an ML solution. At other times, options exist but are hard to discover and hidden underneath complicated interfaces.
Infrastructure decisions in ML are nuanced and intricately tied with your overall ML strategy. Thinking about them in isolation leads to expensive transient phases in your ML adoption.
At FloydHub, we’ve personally had to experiment with and learn from making these choices. We’ve seen many companies get ML infrastructure right and others that got it very wrong. We’ve also learned a thing or two about how this works. The companies that get it right have an adaptive and classically lean way of thinking about infrastructure. They understand their overall maturity with ML capabilities, how this is changing over time and how this reflects on the demands placed on their technical stacks. They make decisions that move them forward in the short run but also get them information to act strategically in the long run.
We’ve partnered with hundreds of companies and helped them establish best practices that yield such outcomes. This blog post is the first in a series of posts that discusses our key learnings and recommendations. In this series, we’ll share our recommendations on other parts of ML infrastructure and broader principles on making good decisions in this area. We aim to provide useful starting points and broad principles that you can adapt to your situation.
Every team is different and having the right partnerships is key to advancing your ML capabilities quickly. Our enterprise partnership wing, Floyd Labs, offers tactical AI consulting to help you make informed decisions and build the right data infrastructure to meet your unique needs. We are also happy to give you real, useful advice based on a decade of experience putting ML into production. Chat with us.
About Naren Thiagarajan
Naren Thiagarajan is the co-founder and CTO of FloydHub. Naren is an expert in building high performance cloud infrastructure specifically for Machine Learning. He designed FloydHub’s core architecture that supports training thousands of ML models every day.
He is passionate about open source software and has developed many open source ML tools like Infinity. Naren is a YCombinator alumnus and regularly advises companies on their AI infrastructure architecture. Naren has a Masters in CS from Stanford and worked with world renowned Dr. Dan Boneh on cryptography and location privacy.