Automate FloydHub with Celery
Jelle Hoffman from Ubidots shows how he used Celery to automate their FloydHub API management


👋 I'm Jelle Hoffman - an engineer at Ubidots. Ubidots is an Internet of Things (IoT) data analytics and visualization company. We transform sensor data into information that powers business decisions, and we're using FloydHub to build and launch our latest feature - detecting anamolies from images captured by IoT devices.
In this post, I'll share our approach (and code!) to automatically create a model API on FloydHub using Celery.
Why FloydHub?
Our goal for this feature was to create and deploy an object-detection model for our customers. We picked FloydHub because it provided a centralized repository for our data, full version control of the training jobs, and cloud GPUs for model training. FloydHub also has a serving mode which was perfect because we knew we wanted to create an API with the model.
In this post, I will be showing how to use celery to start and stop a serving endpoint on FloydHub. You can easily modify this to run training jobs as well.
"FloydHub has greatly reduced our development, testing, and deployment time, drastically simplifying our solution's complexity so that we can continue to focus on delivering innovative products to our end-users." - Gustavo Andrés Angulo - CTO, Ubidots

Why Celery?
Celery is an asynchronous task queue for Python and Django and fits perfectly into our workflow. We use celery for two main purposes:
-
Manage the model serving API by turning starting it on FloydHub when required and shutting it down after use. This saves resources and money by running the FloydHub job only when needed.
-
Process the images from the sensors by querying the model API hosted on FloydHub.
This way, the entire object detection pipeline is automated using celery and requires no manual intervention by our engineers.
Data
For our project, we used the YOLO object-detection model and if you are interested, the YOLO weights dataset is available publicly on FloydHub.
Celery config
When the Celery server starts we want to:
- Login into FloydHub
- Start the model serving job
We use the Celery init method to configure both the steps:
class CustomArgs(bootsteps.Step):
def __init__(self, worker, **options):
# Log in to FloydHub
login_floydhub(username, password)
start_floydhub_job(project_name, dataset_name, mounting_point, instance_type, env, command, mode, description)
app.steps['worker'].add(CustomArgs)
The login method:
Here is the login function. Floyd command line tool or floyd-cli comes with clients that you can use to communicate with FloydHub.
Use AuthClient to login with FloydHub credentials. Then store the access token using the AuthConfigManager. This will be used in
def login_floydhub(self, username, password):
try:
print('Logging into FloydHub')
# Setting the username and password
login_credentials = Credentials(
username=username, password=password)
# Collecting a access code
access_code = AuthClient().login(login_credentials)
# Getting the designated user
user = AuthClient().get_user(access_code)
# Collecting the accesstoken
access_token = AccessToken(
username=user.username, token=access_code)
# Setting the accesstoken
# This will ensure that future sdk calls automatically uses the access token
AuthConfigManager.set_access_token(access_token)
print('Succesfully logged into FloydHub')
except AuthenticationException as exc:
raise self.retry(exc=exc)
Starting a FloydHub job:
Use this code snippet to learn how to create a FloydHub job that will create a model serving API. FloydHub jobs are referred to as Experiment in the SDK. You can mount any public dataset into your job by referring to its name and using the DataClient. You can also pick the environment you would like to use for your job (eg. tensorflow-1.7).
def start_floydhub_job(self,
project_name="alice/rnn-example",
dataset_name="alice/mnist/1",
mounting_point="mnist_input_path",
instance_type="c1",
env="tensorflow-1.7",
command=None,
mode="serve",
description="create model api"):
project = ProjectClient().get_by_name(project_name)
namespace, name = get_namespace_from_name(project_name)
experiment_config = ExperimentConfig(name=name,
namespace=namespace,
family_id=project.id)
ExperimentConfigManager.set_config(experiment_config)
FloydIgnoreManager.init()
print(namespace)
# Define data mounts
data_obj = DataClient().get(dataset_name)
print(data_obj.id)
data_ids = ["{}:{}".format(data_obj.id, mounting_point)]
print(data_ids)
# Define the data mount point for data
module_inputs = {
"name": mounting_point,
"type": "dir" # Always use dir here
}
# First create a module and then use it in the experiment create step
experiment_name = project_name
project_id = project.id
# Get env value
arch = INSTANCE_ARCH_MAP[instance_type]
module = Module(name=experiment_name,
description=description,
command=command,
mode=mode,
family_id=project_id,
inputs=module_inputs,
env=env,
arch=arch)
module_id = ModuleClient().create(module)
experiment_request = ExperimentRequest(name=experiment_name,
description=description,
full_command=command,
module_id=module_id,
env=env,
data_ids=data_ids,
family_id=project_id,
instance_type=instance_type)
try:
expt_info = ExperimentClient().create(experiment_request)
# returning job_id for tracking or stopping purposes
job_id = expt_info['id']
return job_id
except OverLimitException as exc:
# There are jobs running so we need to stop them
# before we can start a new job
stop_all_floydhub_jobs()
raise self.retry(exc=exc)
This will create a model api as per your specifications.
Stopping a FloydHub job:
The only thing we still need to do is figure out how to stop the model API when the Celery server stops or crashes.
For this task, I created a bash script that includes the celery run step followed by the cleanup script. This is because celery does not have callback for the server stop operation. And also you cannot catch the SIGINT and SIGTERM signals because Celery overrides them. Here is the full script file:
# Starting the celery server
echo Starting the Celery server
celery -A tasks worker --loglevel=info
# The celery server is stopped and we need to stop the FloydHub API
echo Starting the cleanup process
python3 cleanup.py
First we start the Celery server which starts the login process and the model API. When you Ctrl+C (once or twice) the Celery server will be stopped. After that the clean up script is invoked - this will terminate all running model apis on FloydHub.
def stop_all_floydhub_jobs():
experiments = ExperimentClient().get_all()
for experiment in experiments:
if experiment.state == 'running':
ExperimentClient().stop(experiment.id)
Conclusion
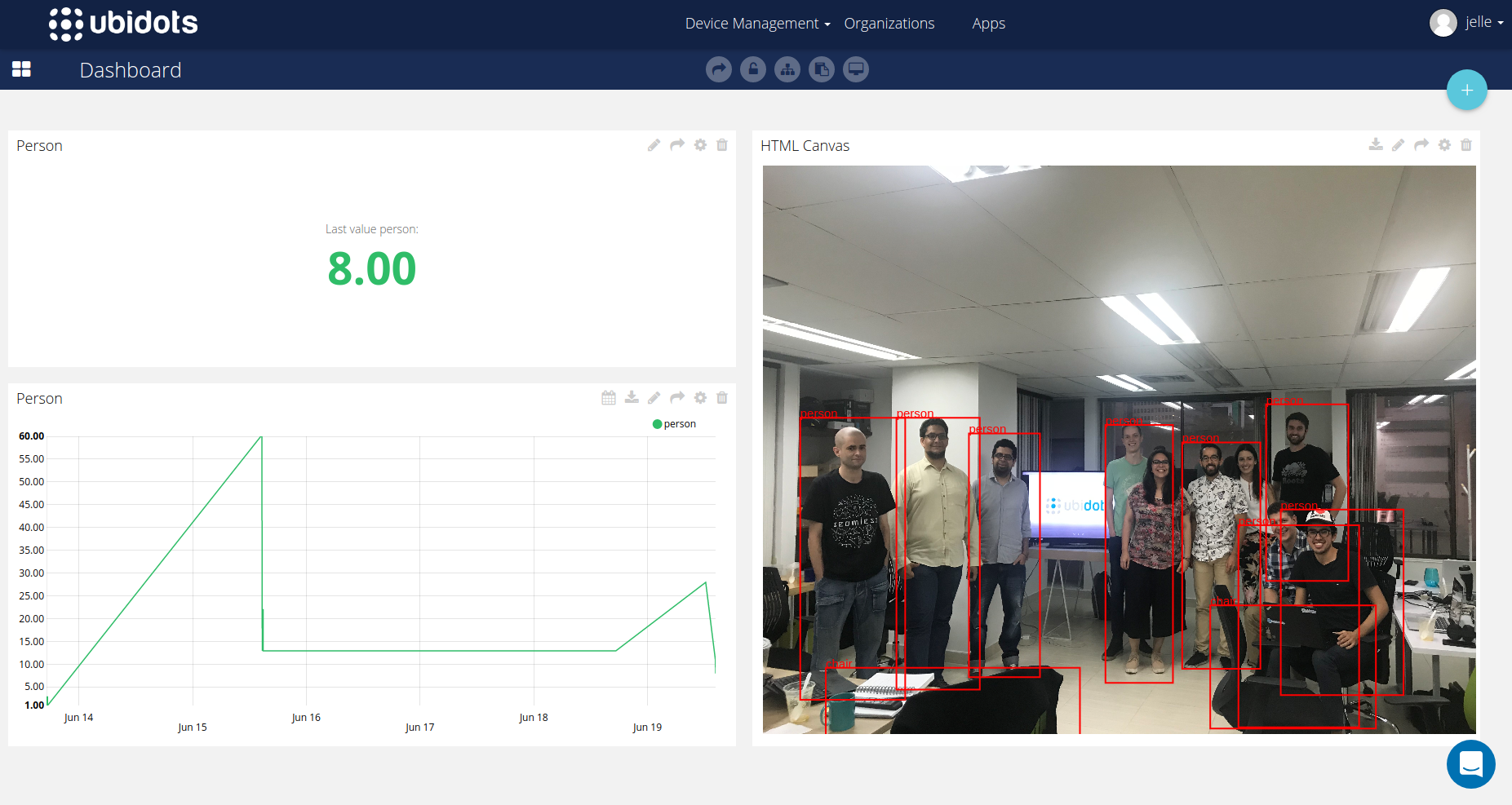
With this we can now manage our FloydHub jobs automatically from Celery. This has been tremendously helpful for us to make sure that the model API is always up when we are processing our customer images and shutdown when they are no longer needed.
You can learn more about FloydHub SDK from the GitHub repo and you can use that to build your own FloydHub automation.
You can learn more about Ubidots on our website. Thanks!