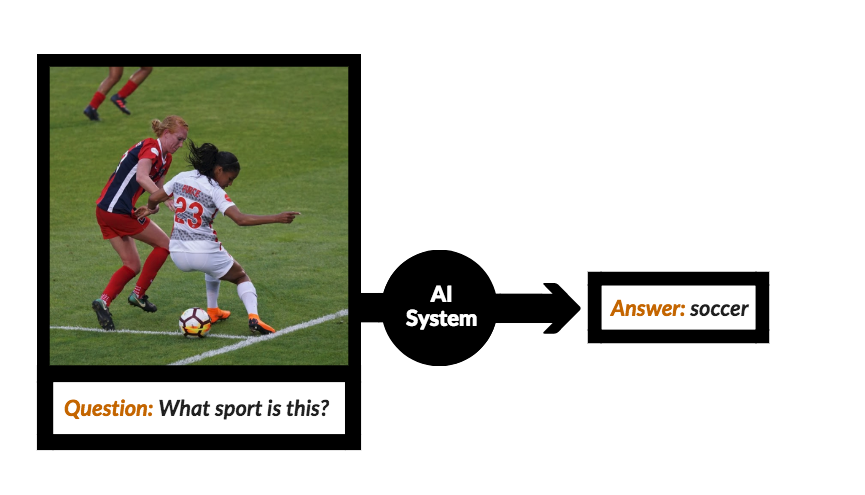
Asking questions to images with deep learning: a visual-question-answering tutorial
In this deep learning tutorial, we'll build Visual Question Answering (VQA) model that allows people to ask open-ended, common sense questions about the visual world.


Improving accessibility through computer interfaces shares a multi-decade history with applied artificial intelligence (AI), most commonly in the area of voice recognition (👋 Siri! 👌Google?).
Now, with advancements in deep learning, the field of computer vision is making exciting gains in accessibility tech as well – we’re seeing new apps and techniques that can enable alternative forms of perception and redefine what it means to “see”.
In 2016, Microsoft released Seeing AI, an “app for visually impaired people that narrates the world around you." The app leverages cameras on users’ devices, natural language processing, and computer vision to describe the surrounding environment.
Apps like Seeing AI are provide powerful alternative perception tools to human sight. However, a core challenge in improving computer “seeing” aids is allowing users to extract the most relevant and desired information from their environment.
In this deep learning tutorial, we’ll take a closer look at an approach for improved object detection called: Visual Question Answering (VQA). VQA can yield more robust visual aids by adding complexity to intelligent systems-based “perception”; this technique allows people to ask open-ended, common sense questions about the visual world, setting the stage for more flexible, personalized engagement.
Much of this research, especially in the area of image classification, has been made possible by the publicly-available ImageNet database – which contains over four million images labeled with over a thousand object categories.
In this post, we’ll first dig a little deeper into the basic theory behind Visual Question Answering and explore two variants of VQA:
- The “bag-of-words” model
- The “recurrent” model
Then I’ll provide some lessons learned and a full tutorial workflow, where you'll learn how to:
- Build and train your own VQA models using Keras + TensorFlow
- Set up a model-serving REST API on FloydHub
- Start asking questions about your own images!
The code for this post is all open source. You can view my experiments directly on FloydHub, as well as the code (along with the weight files and data) on Github. Let's get started!
What's in a question?

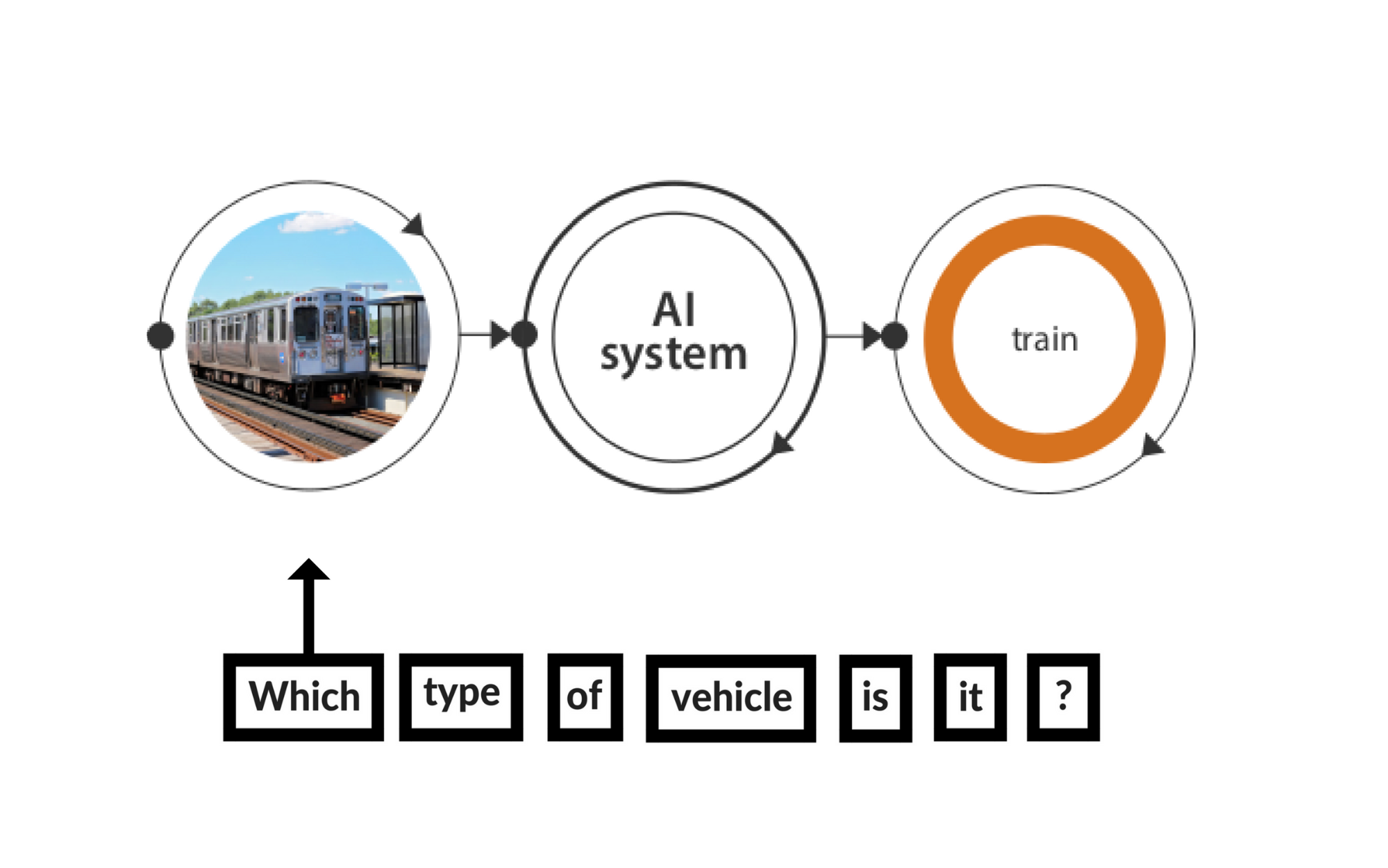
Let’s say that we wanted to develop a model that would be able to answer some questions about the above picture of a train. For example, I’d like to be able to ask the model: Which type of vehicle is it?, and I’d expect it to confidently tell me that it’s a train.
In order to do this, our model would need to understand several things - let’s break them down into sub-tasks:
- Identifying the various objects in the image (the train, traffic signals, tracks, pavement, person, etc)
- Processing the text of the question itself, which can be processed as a ‘sequence’ of words
- Mapping the appropriate sections of the image (in this case - the train) to the input text question.
- Generating natural language text in the form of an answer with an acceptable certainty.
Preparing the dataset
The open-source VQA dataset contains multiple open-ended questions about various images. All my experiments were performed with V2 of the dataset (though I’ve processed v1 of the dataset as well – much smaller in size), which contains:
- 82,783 training images from COCO (common objects in context) dataset
- 443,757 question-answer pairs for training images
- 40,504 validation images to perform own testing
- 214,354 question-answer pairs for validation images.As you might expect, this dataset is huge (12.4 GB of training images).
I’ve provided a helpful script in my repo that can be used to process the questions and annotations (src/data_prep.py). For the images, I decided to use a pre-trained model of VGG16 architecture trained on COCO itself by Andrej Karpathy for his Image Captioning project. For those following along, I’ve created a public dataset on FloydHub called vgg-coco to store this dependency (VGG-Net), so you can simply mount this existing public FloydHub dataset to your jobs and workspaces. This is nice because it eliminates the need for you to ever upload it again yourself.
Once we process the data, we’ll obtain the following preprocessed text files that’ll be used for training:
├── preprocessed # Text files used for training.
├── questions_train2014.txt # Training questions.
├── questions_lengths_train2014.txt # Length of each question
├── questions_id_train2014.txt # Map ques-imgs
├── images_train2014.txt # Image IDs (used for mapping)
└── answers_train2014_modal.txt # Answers for training questions.
├── data # Data used and/or generated
│ ├── get_data.sh # Execute first to download all preprocessed data
├── src # Source Files
│ ├── train_baseMLP.py # Train the feed-forward model.
│ ├── train_LSTM.py # Train the recurrent model.
│ ├── utils.py # Utility methods reqd for training.
│ ├─ data_prep.py # Prepare data for training from the VQA source.
│ ├── evaluate.py # Determines accuracy of the model.
│ ├── test.py # Test file to run with your own image-question pairs.
├── preprocessed # Preprocessed Data for reference
├── models # Stored model files required for test execution
├── LICENSE
└── README.mdAs in any supervised learning project, our core task is to frame a set of input features and feed them through some model weights in order to get the output. In its most basic form, VQA is no different.
As a result, this will be the first approach that we’ll take. We'll simply coalesce the feature vectors of our image and the text question input to feed them into a fully connected network that can predict an answer to the question.
Baseline: Bag of Words
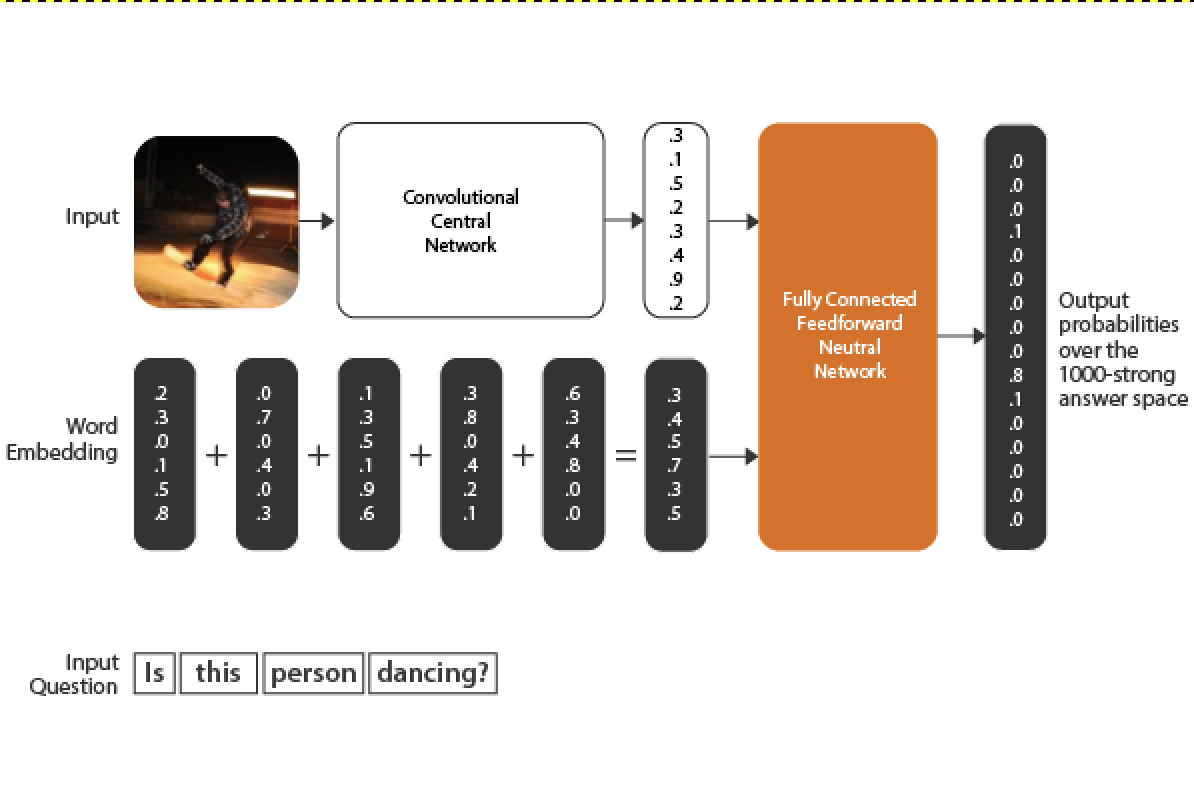
There are many ways to represent text data with machine learning. One of most simple (and elegant) approaches is the Bag of Words model. The Bag of Words approach is simple to understand, straightforward to implement, and has seen great success in problems such as language modeling and document classification. You can check out this post for a quick intro to BoW model.
It’s important to observe that the feature vector for our question (which is being fed into the network) is the sum of all the feature vectors of the words of that particular question. Therefore, regardless of the word order of the original question, this feature vector remains the same – thus, the Bag of Words. The topology of this network is defined as follows:
num_hidden_units = 1024
num_hidden_layers = 3
batch_size = 128
dropout = 0.5
activation = 'tanh'
img_dim = 4096
word2vec_dim = 300
num_epochs = 100When training your model, it’s a good idea to add a TensorBoard integration to visualize your training process more effectively. This is quite simple when using FloydHub. All you have to do is export your TensorBoard logs to ./Graph:
model = Sequential()
model.add(Dense(num_hidden_units, input_dim=word2vec_dim+img_dim,
kernel_initializer='uniform'))
model.add(Dropout(dropout))
for i in range(num_hidden_layers):
model.add(Dense(num_hidden_units, kernel_initializer='uniform'))
model.add(Activation(activation))
model.add(Dropout(dropout))
model.add(Dense(nb_classes, kernel_initializer='uniform'))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop')
tensorboard = TensorBoard(log_dir='./Graph',
histogram_freq=0,
write_graph=True,
write_images=True)Another subtle implementation observation is that the questions are of variable length. In order to represent the question vectors as Tensors, the smaller questions should be zero padded.
Note: The default FloydHub environment does not contain internal dependencies (Word Vectors) of SpaCy installed, so in order to run the script on FloydHub jobs you can execute this Floyd CLI command:
floyd run --gpu --data sominw/datasets/vqa_data/2:input 'bash run_me_first_on_floyd.sh && python src/train_baseMLP.py --logdir ./Graph'
Our baseline performed fairly well with about 48% accuracy. This architecture should took around 400 sec/epoch to complete on FloydHub’s K80 GPU instances. It is also interesting to note that this baseline architecture flattens out after 35-40 epochs.
Here are some of the mistakes I made and lessons learned in the process of building this first iteration of a baseline model. Keep these in mind when building your own model:
- Preprocessing requires a lot of patience: There were certainly very diverse elements before even getting to the training models part. Like processing JSON to extract questions, answers, and ids for images. These in turn require a lot of patience and effort. I suggest you understand thoroughly how these are done. Processing these elements helped me understand how powerful NumPy’s vectorized operations are.
- Don’t be overwhelmed: With problems like VQA, where research is going on at an astonishing pace, it is very easy to stumble upon a state of the art research paper, spend hours figuring out complex equations and ultimately end up with nothing. It is always better to start up with what you already know. Hence, I decided to build this baseline using the absolute basics of Neural Nets.
- Start out small, then scale: One of the early mistakes I made while starting out with this project was to do everything at once. Make sure you start with a very tiny subset of this huge dataset–rapidly prototype a model with maybe a single epoch. See if it processes well on your evaluation code. Once you have all these things in place, you’re good to scale it up.
Recurrent Model
As a next step, let’s try to improve the accuracy of our model through a posterior processing of text. This approach is called a Recurrent Model.
In our previous approach, the order and structure of the words in the question were discarded—it was just a “bag” of, otherwise “independent”, words. In a Recurrent Model, the sequence of words is preserved. Another way to think about RNNs is that they have a “memory”, which captures information about what has been calculated so far. This nature of preserving long sequences is what makes RNNs perfect for NLP related tasks.
We choose to go ahead with LSTMs to avoid a fundamental limitations of vanilla RNNs: the Vanishing Gradient Problem. (If you want to know more about RNNs–limitations, strengths and types–you can refer to this great article by Andrej Karpathy).
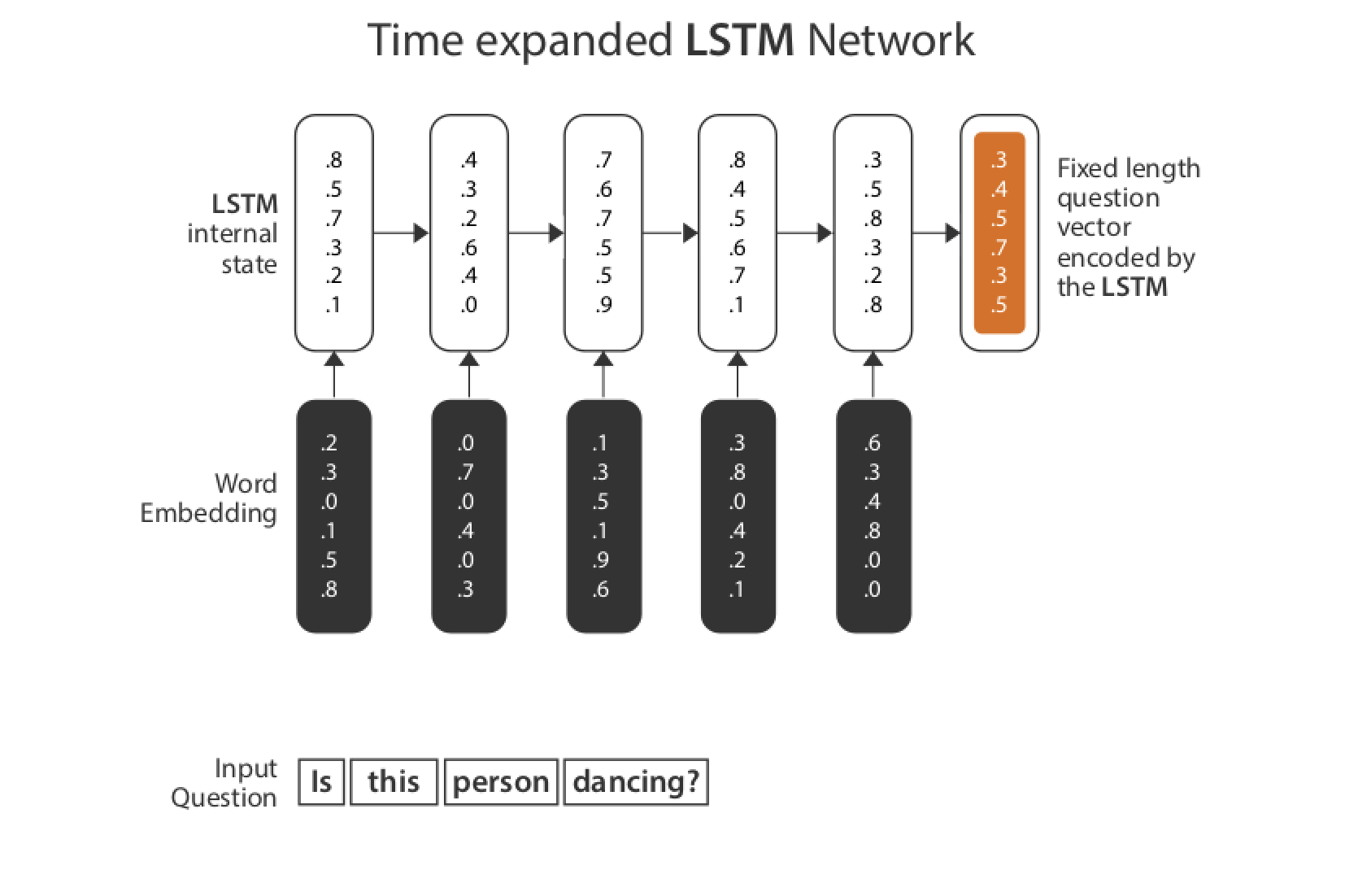
The neural network has 3 stacked 512-unit LSTM layers to process questions, which are then merged with the image model. One fully-connected regular layer takes the merged model output and brings it back to the size of the vocabulary (as depicted in the figure above).
The LSTM network in Keras expects the input (Tensor X) to be provided with a specific array structure in the form of: [samples, time steps, features] Currently, our data is of the form [samples, features]. So we define two different models: an image model to process image feature vector (len: 4096), and a language model to process the sequences of the question text (len: 300, timestep: 30 – max length of question available with us).
number_of_hidden_units_LSTM = 512
max_length_questions = 30
### Image model
model_image = Sequential()
model_image.add(Reshape((img_dim,),
input_shape=(img_dim,)))
### Language Model
model_language = Sequential()
model_language.add(LSTM(number_of_hidden_units_LSTM,
return_sequences=True,
input_shape=(max_length_questions,
word2vec_dim)))
model_language.add(LSTM(number_of_hidden_units_LSTM,
return_sequences=True))
model_language.add(LSTM(number_of_hidden_units_LSTM,
return_sequences=False))
### Merging the two models
model = Sequential()
model.add(Merge([model_language, model_image],
mode='concat',
concat_axis=1))
This architecture took around 460-500 sec/epoch to complete on FloydHub’s K80 GPU instances, with performance flattening out after 50 epochs.
floyd run --gpu --data sominw/datasets/vqa_data/2:input 'bash run_me_first_on_floyd.sh && python src/train_LSTM.py --logdir ./Graph'
There still remains a lot of scope for hyper-parameter tuning in both the architectures (i.e number of layers), percentage of dropout, and timesteps in case of LSTM etc.
Takeaways and Tests
The evaluation performed on the validation set yielded the following results:
| Model | Accuracy (%) |
|---|---|
| Baseline (MLP) | 48.33 |
| Recurrent Model (LSTM) | 54.88 |
The results obtained are in line with the original VQA Paper, although we evaluated it on the validation set.
Overall, building and evaluating VQA models was extremely educational. Based on my experience, these are the key takeaways that I think others interested in the space should consider:
- Beware of rabbit holes: Due to the sheer variety of components involved here, it is important to take your time and follow a step by step approach, carefully assessing how the data is being processed. As you move forward from simpler models like MLP towards complicated ones like RNNs/LSTMs, it is fairly common to run into dimensionality errors while feeding your data into the models. But it is perfectly okay, if you assess your input pipeline thoroughly, assessing dimensionality of individual elements, you should be able to resolve such issues.
- Reproducibility issues with dependencies: In case you’re trying to reproduce the results or are deploying deep learning models, ensure that dependencies are consistent with what you’ve trained with. I had to spend nearly 2 days diagnosing an issue where my training speed came to a crawl because an updated third-party dependency messed up my input pipeline.
- The way forward: One of the very cool things about VQA in general is that it is an extremely new domain. Therefore, there is absolutely no end to what you can do, even if it means replicating original research. Now that you have a pipeline ready, it will be interesting to attempt some of the latest work in VQA with attention models, among other things.
Let's try it out: FloydHub model serving API tutorial
After building these two potential solutions to the VQA problem, we decided to create a serving endpoint on FloydHub so that we can test out our models live using new images.
Here’s what you'll need to run a model serving job on FloydHub:
- A trained model + weights stored inside a Dataset on FloydHub: I’ve already stored my models in the VQA Dataset, so I’ll be using the same dataset in my serving job.
- A simple Flask app (called
app.py) to process your input image & return an output from your model - A
floyd_requirements.txtfile to specify any additional requirements, like Flask!
To make things easy, I like to create a separate repository for my model serving jobs in order to avoid uploading the excess code overhead required for training/evaluating models. To speed up your process, I've created a sample serving repo that you can clone and test out with my trained models. You can use my sample app.py and floyd_requirements.txt files to bootstrap your own serving jobs.
# clone my GitHub repo with the Flask app and other requirements
git clone https://github.com/sominwadhwa/vqamd_api
# login in FloydHub command line tool
floyd login
# connect with a FloydHub project
floyd init vqa_apiAfter you've initialized your project with FloydHub, you're ready to start up a model-serving job on FloydHub:
# start my serving job (along with the attached dataset)
floyd run --data sominw/datasets/vqa_data/3:input --mode serveNow you'll get URL to your job's dashboard on FloydHub as well as your serving job's REST endpoint:
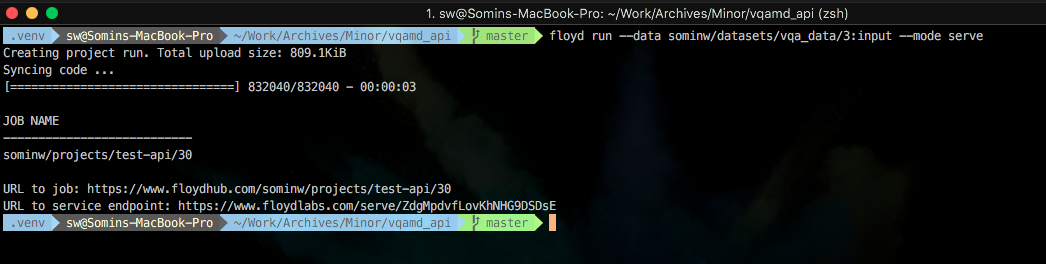
Opening this URL will direct you to FloydHub where you can see the current logs from your REST endpoint. Note that it can take a few minutes to install all the requirements before your serving endpoint is ready. You'll see the following in your logs when your endpoint is ready:
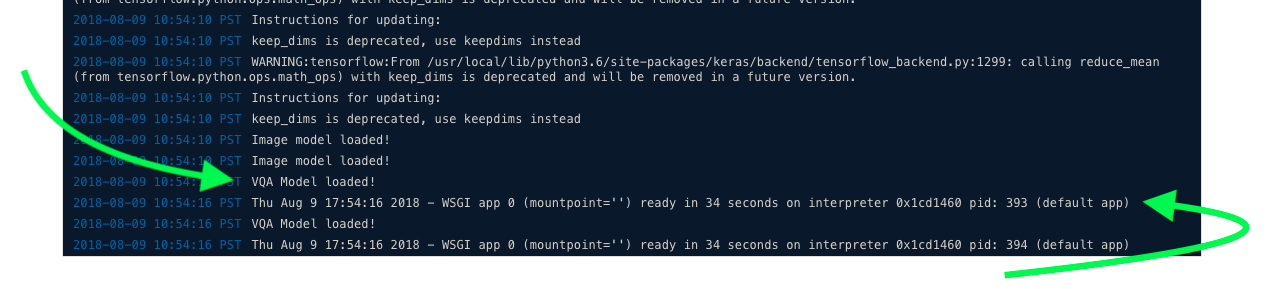
Now the fun really begins – you can start pushing queries to your model on FloydHub with the curl command (or any other HTTP request framework). Here's an example:
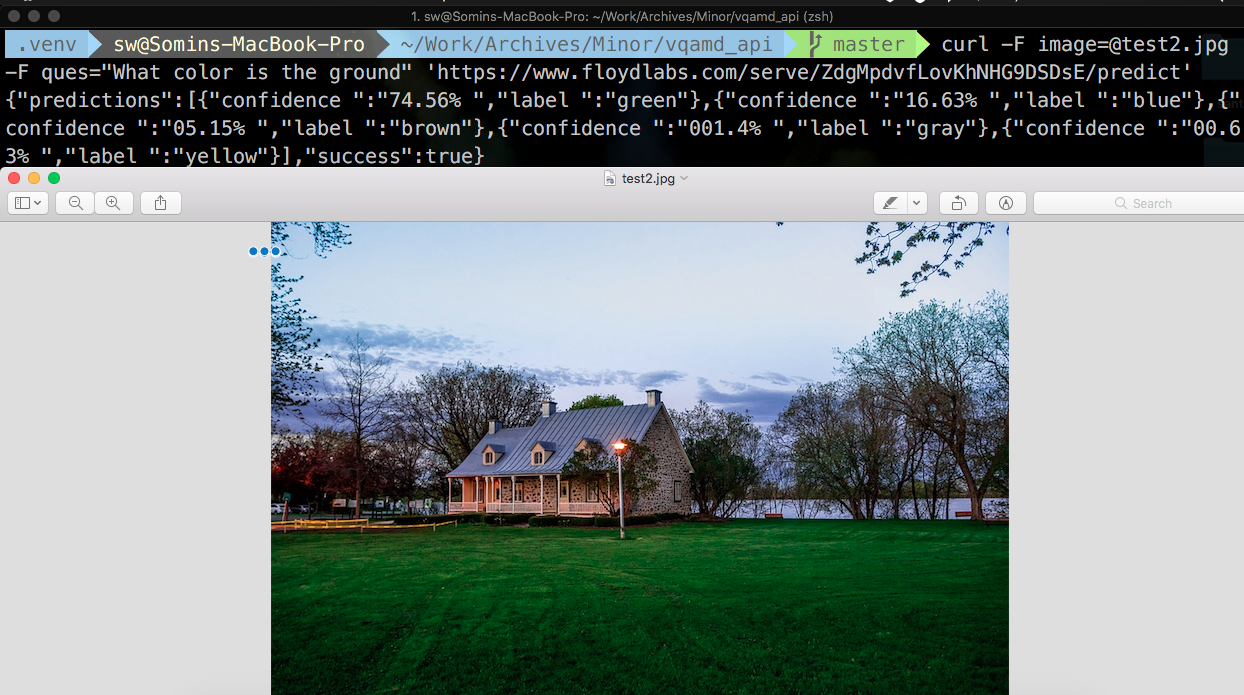
Once you're done using your model's API, don't forget to shutdown your job on FloydHub. For more information on Serving Models on FloydHub, you can checkout their docs and other tutorials.
About Somin
Somin is currently majoring in Computer Science & is a research intern at Complex Systems Lab, IIIT-Delhi. His areas of interest include Machine Learning, Statistical Data Analysis & Basketball. Somin is also an AI Writer for FloydHub.You can follow along with him on Twitter or LinkedIn.
Sincere thanks to J. Raunaq for being a part of this project all along and contributing to it. If you try to replicate or run some of your own tests and have some feedback, get stuck or pursue a similar project in this domain, do ping @me or @Raunaq on twitter. We’d love to see what you’re up to.
We're always looking for more guests to write interesting blog posts about deep learning on the FloydHub blog. Let us know on Twitter if you're interested.